[RAG] Overview
프로젝트가 끝난 김에 전체 개념을 복기해보려 한다. 구현 중에는 개념을 정리할 여유가 없었어서.. ㅎㅎ 본 게시글에서는 RAG의 개념적 의의 + 모델 튜닝과의 비교 + 평가하는 방법 등을 포괄적으로 다루려고 한다.
요약
1.RAG는
👍 모델의 정확성 향상, 최신 정보 반영, hallucination 보강, 데이터 정보 보호를 위해 사용한다.
👎 한편 모델 답변의 복잡성 및 응답 시간이 증가하며, 데이터의 품질에 영향을 많이 받는다는 단점이 있다.
✅ NDCG(순위가 중요한 경우), recall(순위가 중요하지 않은 경우) 등 매트릭으로 평가한다.
2.파인튜닝은
👍 많은 리소스를 들여서라도 특정 도메인에 대해 높은 정확도가 필요할 때 사용한다.
📋 그 전에 시도해볼 수 있는 것이 프롬프트 엔지니어링, RAG, PEFT 등이다.
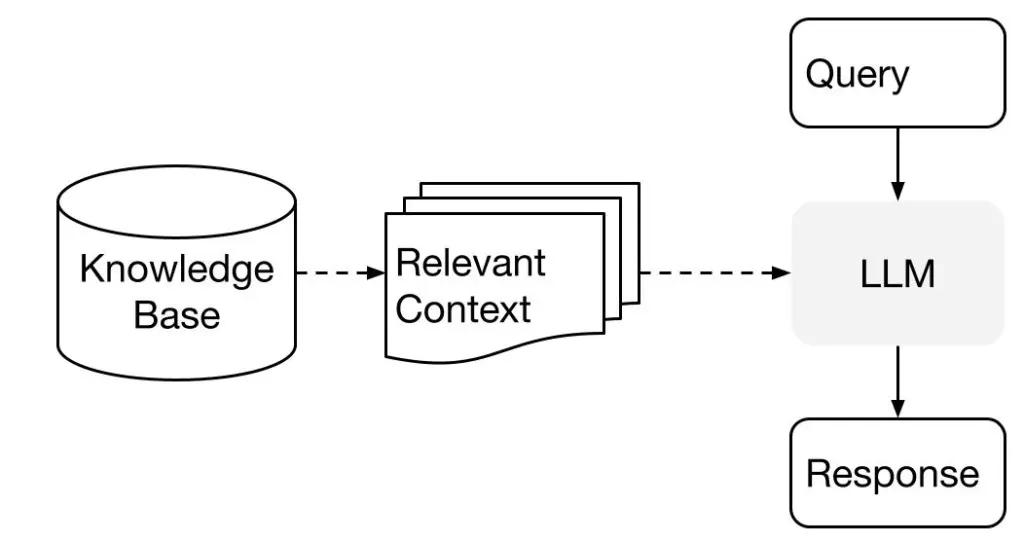
💡 Retrieval-Augmented Generation
정보 검색(IR) + 자연어 생성(NLG) 모델 → AI 가 더 정확하고 상세한 정보를 제공할 수 O
검색을 통해 강화된 생성 기술
Preview
- 구조
- 검색 (Retrieval Component)
입력된 질문에 대해 관련 있는 문서를 외부 데이터베이스나 문서 집합에서 검색합니다.
주로 Dense Retriever(BERT 기반)나 Sparse Retriever(TF-IDF, BM25) 등이 사용됩니다.
- 생성 (Generation Component)
검색된 문서를 바탕으로 최종 응답을 생성합니다.
주로 Transformer 기반의 모델(GPT, BART 등)이 사용됩니다. 이 모델은 검색된 정보를 기반으로 자연스럽고 의미 있는 문장을 생성합니다.
- 검색 (Retrieval Component)
- 👍 필요성
- 데이터 보호: 로컬 모델로 수행할 경우, 외부 API로 사내 데이터가 나갈 위험이 없습니다.
- 정확성 향상: 외부 정보의 도움을 받아 답변의 정확성이 크게 향상됩니다.
- 최신 정보 반영: 학습된 데이터 외에도 최신 정보를 검색하여 반영할 수 있습니다.
- 다양한 응답 생성: 다양한 문서와 정보를 바탕으로 더욱 풍부하고 다양한 응답을 생성할 수 있습니다.
- 생성형 AI의 환각 현상을 보강
- AI에게 훈련된 데이터 외의 추가적인 자료를 검색해 답변을 보강할 수 있게 하여 답변의 정확성을 높이고 환각을 줄입니다.
- 복잡한 질문에 대한 답변, 고급 정보 요구, 특정 주제에 대한 심층적인 이해가 필요할 때 유용합니다.
- 👎 단점
- 복잡성 증가: 검색기와 생성기를 결합하여 사용하므로 시스템 구조가 복잡해지고, 구현과 유지보수가 어려울 수 있습니다.
- 응답 시간 증가: 검색과 생성 과정이 추가되므로 응답 시간이 길어질 수 있습니다.
- 의존성 문제: 외부 데이터베이스의 품질과 가용성에 따라 응답의 품질이 달라질 수 있습니다.
- 📋 RAG 모델을 만들 때 유의해야 할 점
- 데이터 품질: 높은 품질의 데이터베이스나 문서 집합이 필요합니다. 검색기의 성능은 사용되는 문서의 품질에 크게 의존합니다.
- 모델 튜닝: 검색기와 생성기를 효과적으로 결합하기 위해 각 모델의 하이퍼파라미터를 튜닝해야 합니다.
- 훈련 시간: 두 개의 모델을 동시에 학습시켜야 하므로 훈련 시간이 증가할 수 있습니다. 적절한 하드웨어와 학습 자원이 필요합니다.
- 평가 지표: 모델의 성능을 평가하기 위한 적절한 지표를 설정해야 합니다. 단순한 생성 모델 평가 방식이 아닌 검색과 생성의 조합을 평가할 수 있는 방법이 필요합니다.
파인튜닝과 비교
파인튜닝: 사전 학습된 모델(pre-trained model)에 특정 도메인이나 작업에 맞는 추가 학습을 시키는 과정
- AI에 특정 분야에 대한 데이터를 추가로 훈련시켜, 특정 분야에 대한 전문성을 높여 정확도를 높이는 기술.
- 사전 학습된 모델(BERT, GPT 등)을 특정 데이터셋에 맞춰 추가 학습시켜, 해당 도메인에서의 성능을 향상시킵니다.
- 막대한 데이터 학습 비용 + 해당 분야의 발전에 따른 지속적인 업데이트에 대한 부담이 있습니다.
특정 도메인에 대한 사전학습된 LLM을 커스터마이징 하고자 할 때 사용합니다. 대부분의, 혹은 모든 매개변수를 도메인별 데이터셋으로 업데이트하여, 리소스를 많이 사용해야 한다는 단점이 있지만 특정 도메인에 대해서 높은 정확도를 제공할 수 있습니다.
| 장점 | 단점 |
|---|---|
| - 특정 도메인에서 높은 성능 발휘 | - 고정된 지식에 의존 |
| - 상대적으로 간단한 구조 | - 최신 정보 반영 어려움 |
| - 효율적인 학습 시간 | - 도메인 전이 문제 (다른 도메인에서 성능 저하 가능성) |
- 사용 사례:
- 특정 산업(의료, 법률 등)의 전문 지식 응답
- 고객 지원 챗봇의 도메인 특화 응답
- 특정 언어 모델의 성능 최적화
RAG: 검색기(retriever)와 생성기(generator)를 결합하여, 외부 데이터베이스에서 관련 정보를 검색하고 이를 바탕으로 응답을 생성
- 모델 자체를 업데이트할 필요성 없음
- 모델 자체의 전문성은 다소 떨어지나, 주어진 자료로 한 번 더 체크해 환각 현상을 줄일 수 있음.
외부 데이터베이스의 정보를 이용해 LLM 프롬프트를 강화하며, 사실상 프롬프트 엔지니어링의 정교한 형태입니다.
* RAG 시스템을 평가하는 프레임워크에는 Ragas , ARES , Bench 등이 있습니다 .
| 장점 | 단점 |
|---|---|
| - 최신 정보 반영 가능 | - 시스템 복잡성 증가 |
| - 외부 데이터의 도움으로 정확성과 관련성 향상 | - 응답 시간이 길어질 수 있음 |
| - 외부 데이터베이스 품질에 의존 |
- 사용 사례:
- 뉴스나 백과사전 기반의 최신 정보 제공
- 질문 답변 시스템에서 최신 정보 반영
- 대화형 AI에서 다양한 정보 기반의 응답 생성
-
RAG 파이프라인을 최적화하는 방법은?
데이터 전처리, 인덱싱 및 검색, LLM 추론 프로세스에서 RAG 파이프라인을 가속화할 수 있습니다.
-
전처리
- 중복 데이터 제거
- 청킹 가속화 (NVIDIA cuDF)
- 토크나이저 가속화 (GPU 사용)
-
인덱싱 및 검색
- 적절한 DB 선택
- 최적화된 retriever
-
LLM 추론
- 텐서 샤딩 (TensorRT-LLM)
- 추론 서버
- 스트리밍 사용
-
평가
- 데이터셋을 생성 : 자체 데이터에서 생성 OR 밴치마크 데이터셋 이용
- 정량적 / 정성적 평가를 수행: NDCG(Normalized Discounted Cumulative Gain), recall 등.
* 벤치마크에서 볼 수 있는 인기 있는 변형은 recall@K로, 시스템에서 반환된 상위 K개 항목만 고려합니다. 그러나 시스템이 항상 고정된 K개 항목을 반환하는 경우, recall@K와 recall은 사실상 동일한 메트릭입니다.
