복습
-
지금까지의 학습 순서
-> Linear Regression
-> Logistic Regression(binary classification)
-> Multinomial Classification(정확도 92%)
-> 비정형 Data -> DNN 사용(정확도 95%)
-> 특징만 뽑아내서 학습 -> CNN 사용(정확도 98%)
-> 사용하는 DATA -> MNIST data 이용 -
오늘 진행할 내용
실사 이미지를 이용하여 학습시키기. 개와 고양이 분류
수업 시작
데이터 받아오기(Kaggle)
-
예제 데이터
: Dogs VS Cats 예제는 우리에게 주어진게 image file
25,000장 (dogs : 12,500장 / cats : 12,500장)
https://www.kaggle.com/c/dogs-vs-cats/data -
작업 내용
1. 그림파일을 읽어들여서
2. JPG file을 RGB pixel값으로 decoding
3. 정규화 진행
4. file (CSV) 하나로 만들 예정(local에서 진행)
실습 (local에서 진행)
다운받은 이미지데이터 디렉토리 설정
jupyter home/data/cats_dogs/train/
위 디렉토리에 개, 고양이 이미지파일 25000장을 위치시킨다.
jupyter 코드 실행
개발한경으로 진입
conda activate data_env
모듈 설치
- 명령어
conda install tqdm
- 명령어
conda install -c conda-forge ipywidgets
- 명령어
conda install -c conda-forge opencv
설치 끝났으면 jupyter notebook 입력해서 실행
코드 입력
# Dogs vs Cats (Kaggle) 분석하기
import numpy as np
import pandas as pd
from PIL import Image
import matplotlib.pyplot as plt
import random
import os
import cv2 as cv
from sklearn import utils
from tqdm.notebook import tqdm
# 파일 경로
train_dir = './data/cats_dogs/train/'
# img = 파일 이름
def labeling(img):
class_name = img.split('.')[0]
if class_name == 'cat': return 0
elif class_name == 'dog': return 1
# label data와 pixel data 담을 변수
x_data = []
t_data = []
# os.listdir(): 인자로 준 폴더 경로 안에 있는 모든 파일들 이름 리스트 ):
for img in tqdm(os.listdir(train_dir),
total=len(os.listdir(train_dir)),
position=0,
leave=True):
# 위에서 만든 labeling()을 통해 이름이 cat이면 0 / dog면 1 반환
label_data = labeling(img)
# 이미지 파일 경로 설정
path = os.path.join(train_dir, img)
# 이미지 파일 nd.array로 불러오기 (cv2.imread())
# 형태만 필요해서 흑백으로 불러오기 (cv2.IMREAD_GRAYSCALE)
# 이미지 pixel size 조정하기
img_data = cv.resize(cv.imread(path, cv.IMREAD_GRAYSCALE), (80, 80))
# 리스트 변수에 담아주기
t_data.append(label_data)
x_data.append(img_data.ravel()) # 이미지 shape이 2차원: (80,80)
# 이게 그대로 들어가면 차원 하나 더 있어서 결국 3차원이므로
# 1차원으로 바꿔주기: ravel()
# labeling data ==> DataFrame으로 만들기
t_df = pd.DataFrame({
'label': t_data
})
# 이미지 픽셀 data ==> DataFrame으로 만들기
x_df = pd.DataFrame(x_data)
# 2개 dataframe 합치기
df = pd.merge(t_df, x_df, left_index=True, right_index=True)
# utils.shuffle() ==> pandas dataframe 행을 shuffle 한다.
shuffled_df = utils.shuffle(df)
# DataFrame을 csv 파일로 저장하기
result = shuffled_df.to_csv('C:/python_ML/data/cat_dog/train.csv', index=False)학습 실행
- 진행 중인 모습
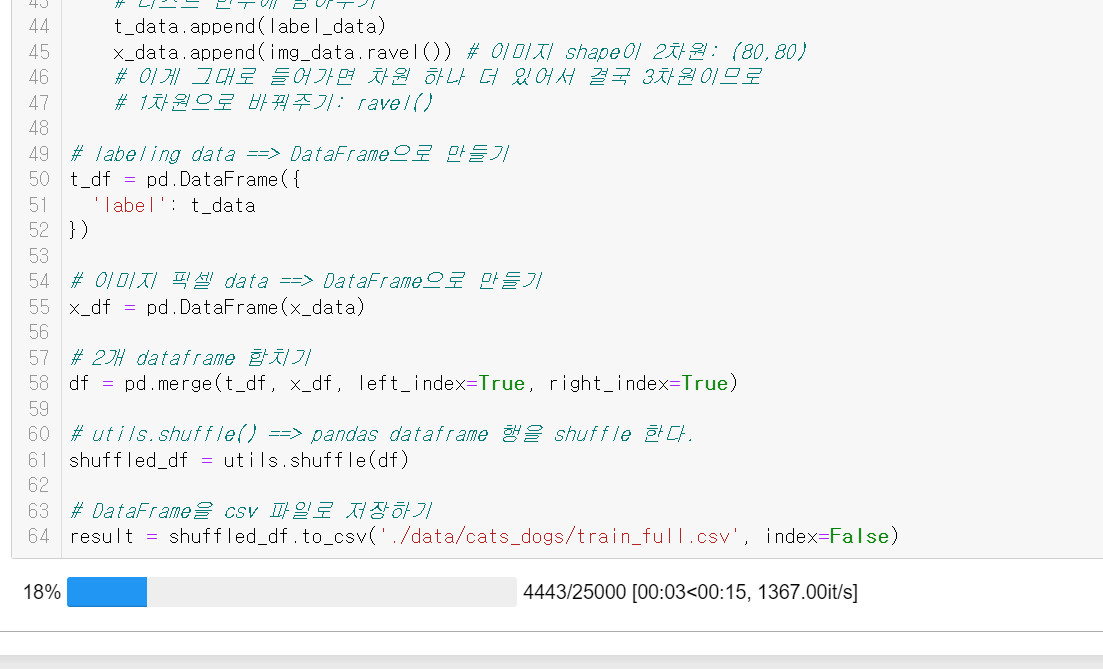
진행률이 100%여도 끝난 게 아니다. 100%는 금방 되는데, 시스템에서 메모리를 엄청 잡고 있으며(필자의 경우 7GB정도), 제대로 완료되면 설정한 위치에 파일이 하나 생성되고, 메모리를 반환해준다.(반환 후 파이썬은 700MB 정도)
colab에서 실습
local에서 얻은 training 데이터 업로드
위에서 만든 train_full.csv 파일을 구글 드라이브에 업로드
(파일명은 cat_dog_full.csv 로 변경)
새 파이썬 파일 생성
코드 작성
모듈 불러오기
- 코드
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense, Conv2D, MaxPooling2D, Dropout
from tensorflow.keras.optimizers import Adam, RMSprop
import matplotlib.pyplot as plt- 출력
없음
데이터 가져오기
- 코드
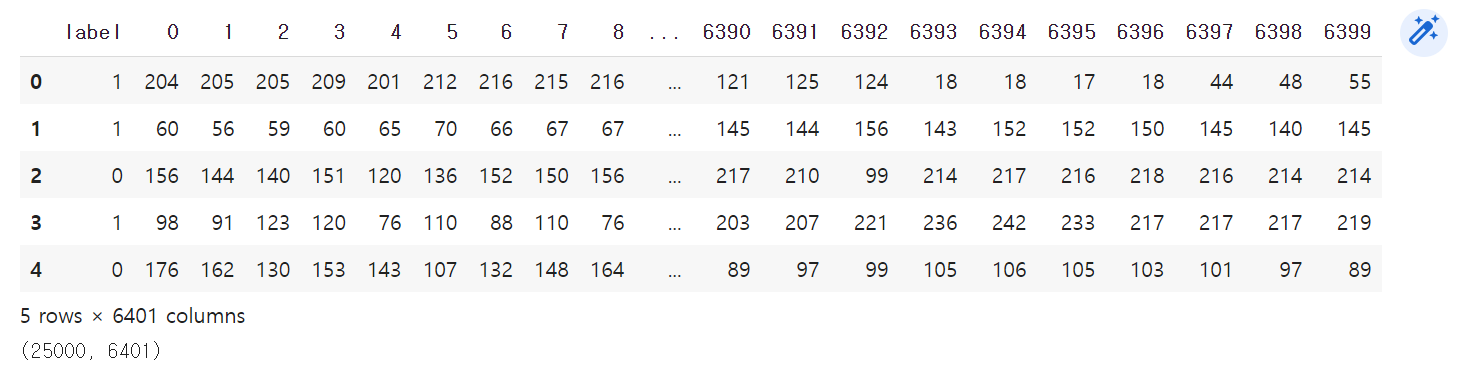
# 1. Raw Data Loading
df = pd.read_csv('/content/drive/MyDrive/한국SW산업협회 교육-Java 과정/파이썬 실습/cat_dog_full.csv')
display(df.head(), df.shape) # (25000, 6401)
# 6401 에서 1 : 개인지 고양이인지 표기- 출력
이미지 데이터(픽셀 정보), 라벨 데이터
- 코드
# 2. 이미지 데이터(픽셀 정보), 라벨 데이터
label_data = df['label'].values
img_data = df.drop('label', axis=1, inplace=False).values # 2차원 ndarray- 출력
없음
샘플 이미지 확인
- 코드
# 3. 샘플 이미지 확인
plt.imshow(img_data[150:151].reshape(80,80), cmap='gray')
plt.show()- 출력
data split (train 7 : test 3)
학습용 데이터를 70% 잡아주기
- 코드
# 4. data split (train 7 : test 3)
x_data_train, x_data_test, t_data_train, t_data_test = \
train_test_split(img_data, label_data, test_size=0.3, random_state=0)- 출력
없음
- 코드
# 5. 정규화 처리
scaler = MinMaxScaler()
scaler.fit(x_data_train)
x_data_train_norm = scaler.transform(x_data_train)
scaler.fit(x_data_test)
x_data_test_norm = scaler.transform(x_data_test)- 출력
없음
모델 생성 1
- 코드
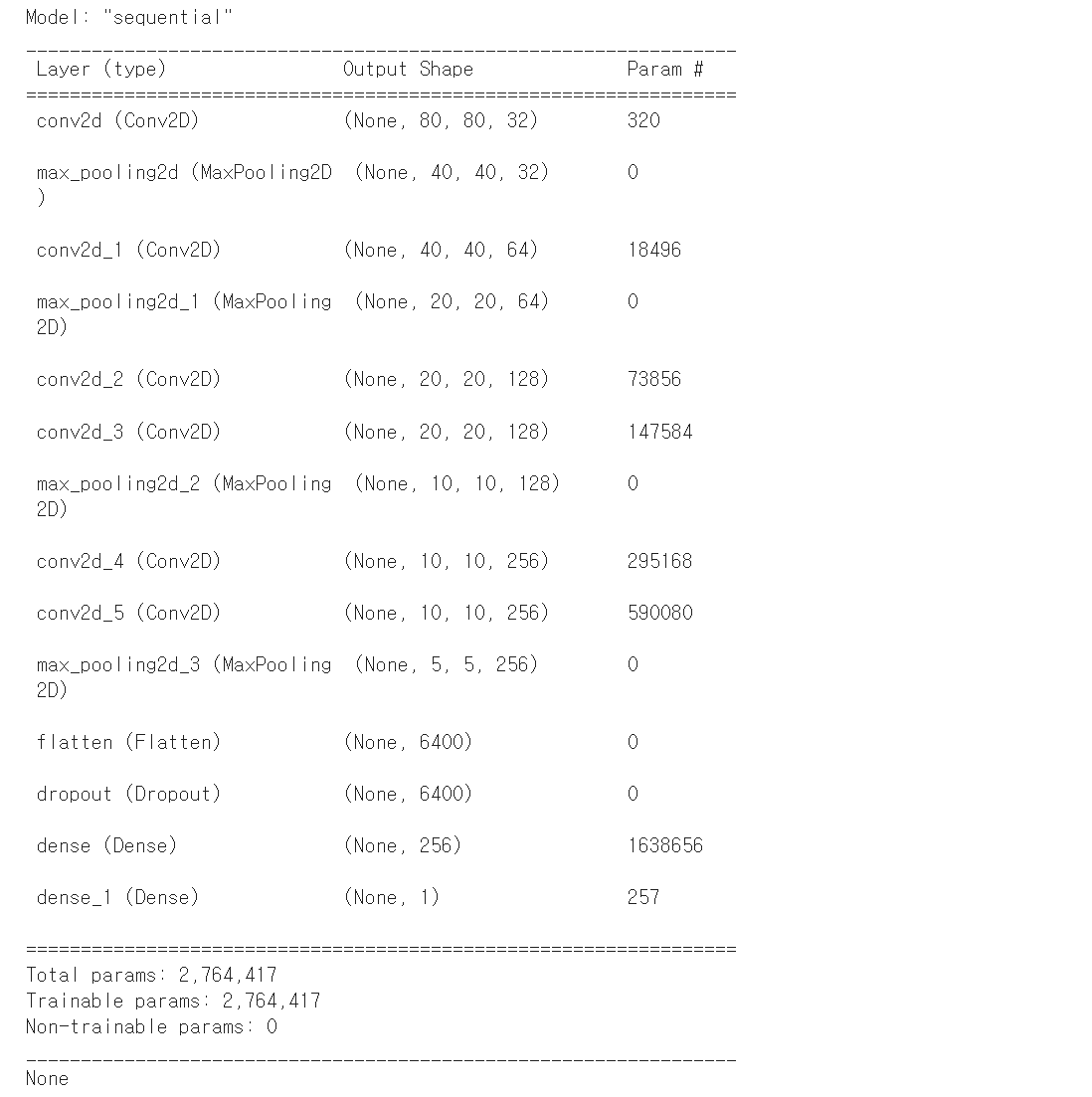
# Model 생성
# 학습 데이터 가공
model = Sequential()
model.add(Conv2D(filters=32,
kernel_size=(3,3),
activation='relu',
padding='same',
input_shape=(80,80,1)))
model.add(MaxPooling2D(pool_size=(2,2))) # 이미지 크기 줄이기
model.add(Conv2D(filters=64,
kernel_size=(3,3),
padding='same',
activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=128,
kernel_size=(3,3),
padding='same',
activation='relu'))
model.add(Conv2D(filters=128,
kernel_size=(3,3),
padding='same',
activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=256,
kernel_size=(3,3),
padding='same',
activation='relu'))
model.add(Conv2D(filters=256,
kernel_size=(3,3),
padding='same',
activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))- 출력
없음
모델 생성 2
- 코드
# Input Layer
model.add(Flatten())
# Dropout Layer
model.add(Dropout(rate=0.5))
# Hidden Layer
model.add(Dense(units=256,
kernel_initializer='he_normal',
activation='relu'))
# Output Layer
model.add(Dense(units=1,
kernel_initializer='he_normal',
activation='sigmoid'))
# units=1
# 결과에는 이미지 하나 당 개인지 고양이인지 판단만 하면 된다.
print(model.summary())- 출력
학습 실행
오래 걸린다.
- 코드
# 학습 실행
# Optimizer
model.compile(optimizer=RMSprop(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['accuracy'])
# Learning
history = model.fit(x_data_train_norm.reshape(-1,80,80,1),
t_data_train.reshape(-1,1),
epochs=100,
batch_size=100,
verbose=1,
validation_split=0.3)
# x_data_train_norm.reshape(-1,80,80,1)
# CNN에서는 입력이 무조건 4차원이어야 한다.- 출력
실행 후 약 1분쯤 지났을 때
너무 느리니까 리소스 런타임에서 하드웨어 가속기를 GPU로 변경하자.
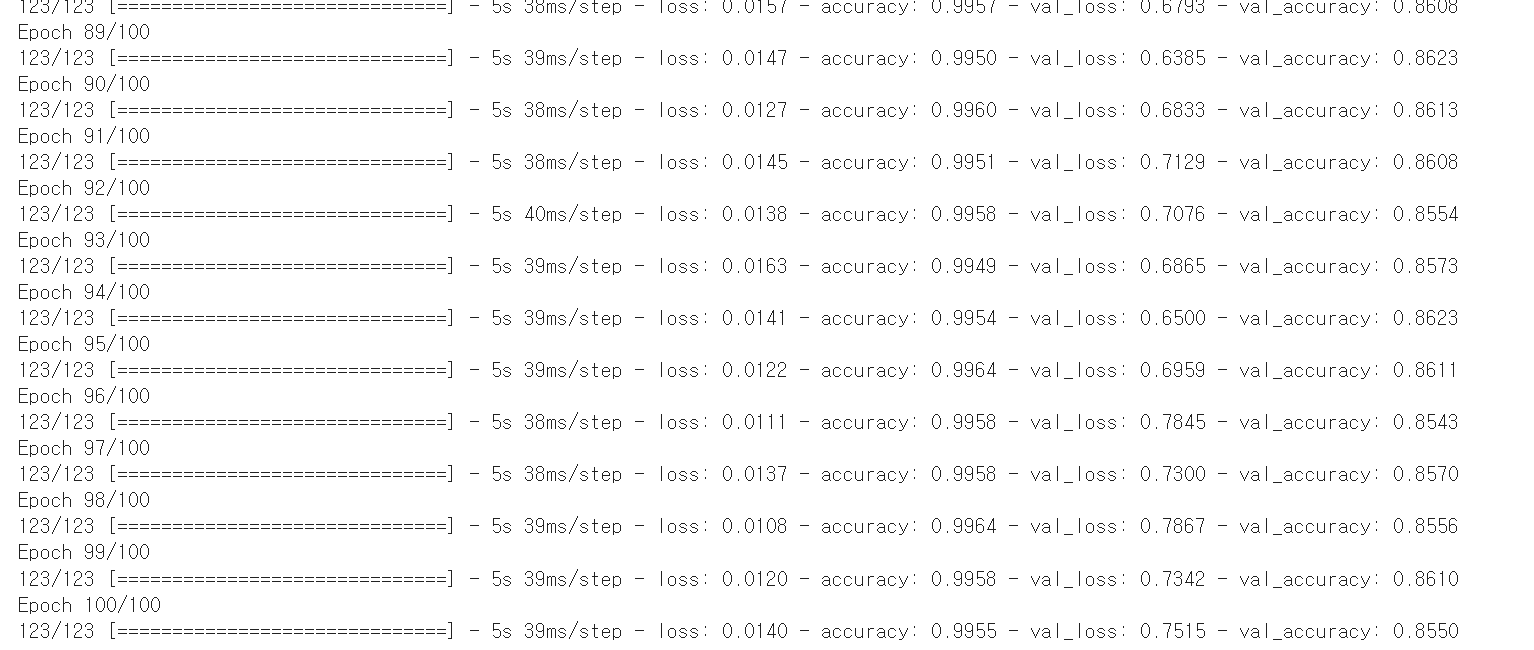
GPU로 수행한 결과
Evaluation. 평가
- 코드
# Evaluation
print(model.evaluate(x_data_test_norm.reshape(-1,80,80,1),
t_data_test.reshape(-1,1)))- 출력

결과 그래프 확인
- 코드
# 결과 그래프
train_acc = history.history['accuracy']
train_loss = history.history['loss']
validation_acc = history.history['val_accuracy']
validation_loss = history.history['val_loss']
fig = plt.figure()
fig_1 = fig.add_subplot(1,2,1)
fig_2 = fig.add_subplot(1,2,2)
fig_1.plot(train_acc, color='b', label='training accuracy')
fig_1.plot(validation_acc, color='r', label='validation accuracy')
fig_1.set_title('Accuracy')
fig_1.legend()
fig_2.plot(train_loss, color='b', label='training loss')
fig_2.plot(validation_loss, color='r', label='validation loss')
fig_2.set_title('Loss')
fig_2.legend()
plt.tight_layout()
plt.show()- 출력
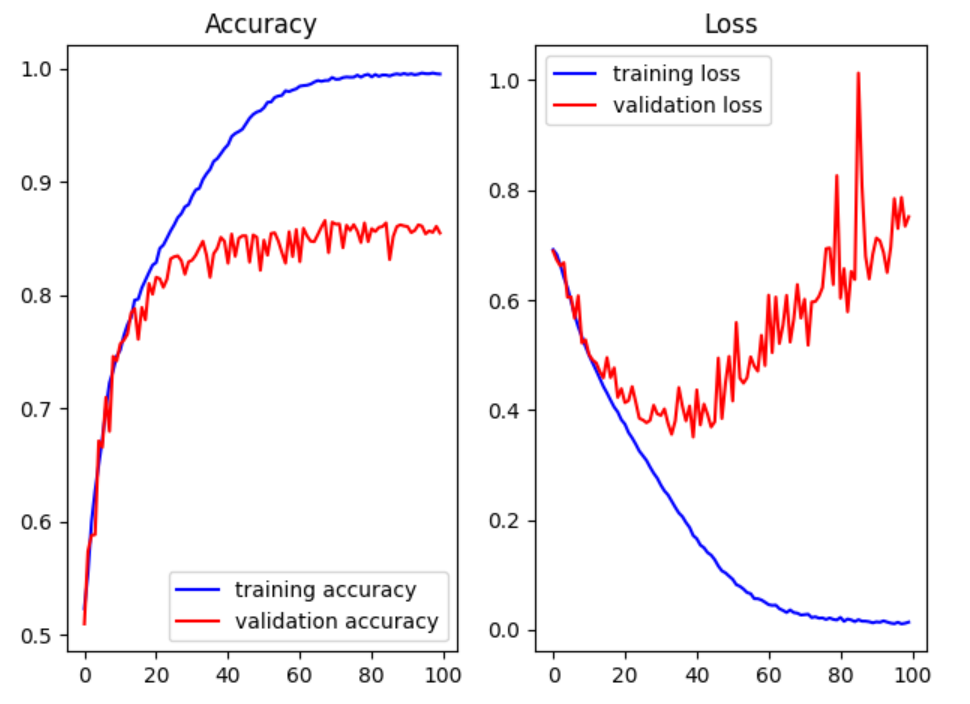
정리
25000장의 학습 결과가 좋지 않다. CNN까지 사용했는데도. (결과정확도 : 86%)
빨간색 선이 어느 순간부터 다시 중가하고 있잖아. 과적합 문제가 생긴 거지.
실제 (현업)로 사용할 때는 위의 case보다 학습이 더 안 된다.
이를 실제 코드로 작성해서 실행해보자.(일부분만 사용해서 학습 진행하기)
local에서 적은 데이터로 실습해보기
파일명
230406-Cats_dogs_SMALL_CNN
적은 수의 파일예제 만들기
- 코드
# 일부 이미지 분리(총 4000개)
import os, shutil
original_dataset_dir = './data/cats_dogs/train'
## directory 생성 ##
base_dir = 'data/cat_dog_small'
os.mkdir(base_dir)
train_dir = os.path.join(base_dir,'train').replace('\\','/')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir,'validation').replace('\\','/')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir,'test').replace('\\','/')
os.mkdir(test_dir)
train_cats_dir = os.path.join(train_dir,'cats').replace('\\','/')
os.mkdir(train_cats_dir)
train_dogs_dir = os.path.join(train_dir,'dogs').replace('\\','/')
os.mkdir(train_dogs_dir)
validation_cats_dir = os.path.join(validation_dir,'cats').replace('\\','/')
os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir,'dogs').replace('\\','/')
os.mkdir(validation_dogs_dir)
test_cats_dir = os.path.join(test_dir,'cats').replace('\\','/')
os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir,'dogs').replace('\\','/')
os.mkdir(test_dogs_dir)
## file 복사 ##
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname).replace('\\','/')
dst = os.path.join(train_cats_dir, fname).replace('\\','/')
shutil.copyfile(src,dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1000,1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname).replace('\\','/')
dst = os.path.join(validation_cats_dir, fname).replace('\\','/')
shutil.copyfile(src,dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1500,2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname).replace('\\','/')
dst = os.path.join(test_cats_dir, fname).replace('\\','/')
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname).replace('\\','/')
dst = os.path.join(train_dogs_dir, fname).replace('\\','/')
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000,1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname).replace('\\','/')
dst = os.path.join(validation_dogs_dir, fname).replace('\\','/')
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1500,2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname).replace('\\','/')
dst = os.path.join(test_dogs_dir, fname).replace('\\','/')
shutil.copyfile(src,dst)- 출력
모듈 불러오기
- 코드
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.layers import Flatten, Dense, Dropout
from tensorflow.keras.optimizers import Adam, RMSprop
from tensorflow.keras.preprocessing.image import ImageDataGenerator
train_dir = './data/cat_dog_small/train'
validation_dir = './data/cat_dog_small/validation'- 출력
없음
ㅁㄴㅇㄹ
- 코드
# ImageDataGenerator 생성
# 모든 이미지 데이터의 값을 1/255로 scaling(MinMaxScaling)
train_datagen = ImageDataGenerator(rescale=1/255)
validation_datagen = ImageDataGenerator(rescale=1/255)
train_generator = train_datagen.flow_from_directory(
train_dir, # target directory
classes=['cats', 'dogs'], # cats, dogs 순서로 label 0,1
# (생략하면 폴더순서로 label적용)
target_size=(150,150), # image size scaling
batch_size=20, # 한번에 20개의 이미지를 가져온다.
# label에 상관없이 가져온다.
class_mode='binary') # 고양이와 멍멍이만 존재하므로
# 2진 분류이기 때문에 binary
# 다중분류인 경우 'categorical'(기본값),
# 'sparse' 이용가능
# 오토인코더처럼 입력을 target으로 하는 경우 'input'
validation_generator = validation_datagen.flow_from_directory(
validation_dir,
classes=['cats', 'dogs'],
target_size=(150,150),
batch_size=20,
class_mode='binary')- 출력
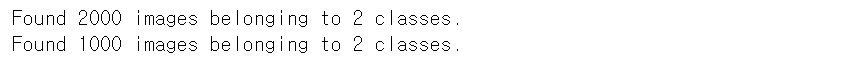
ㅁㄴㅇㄹ
- 코드
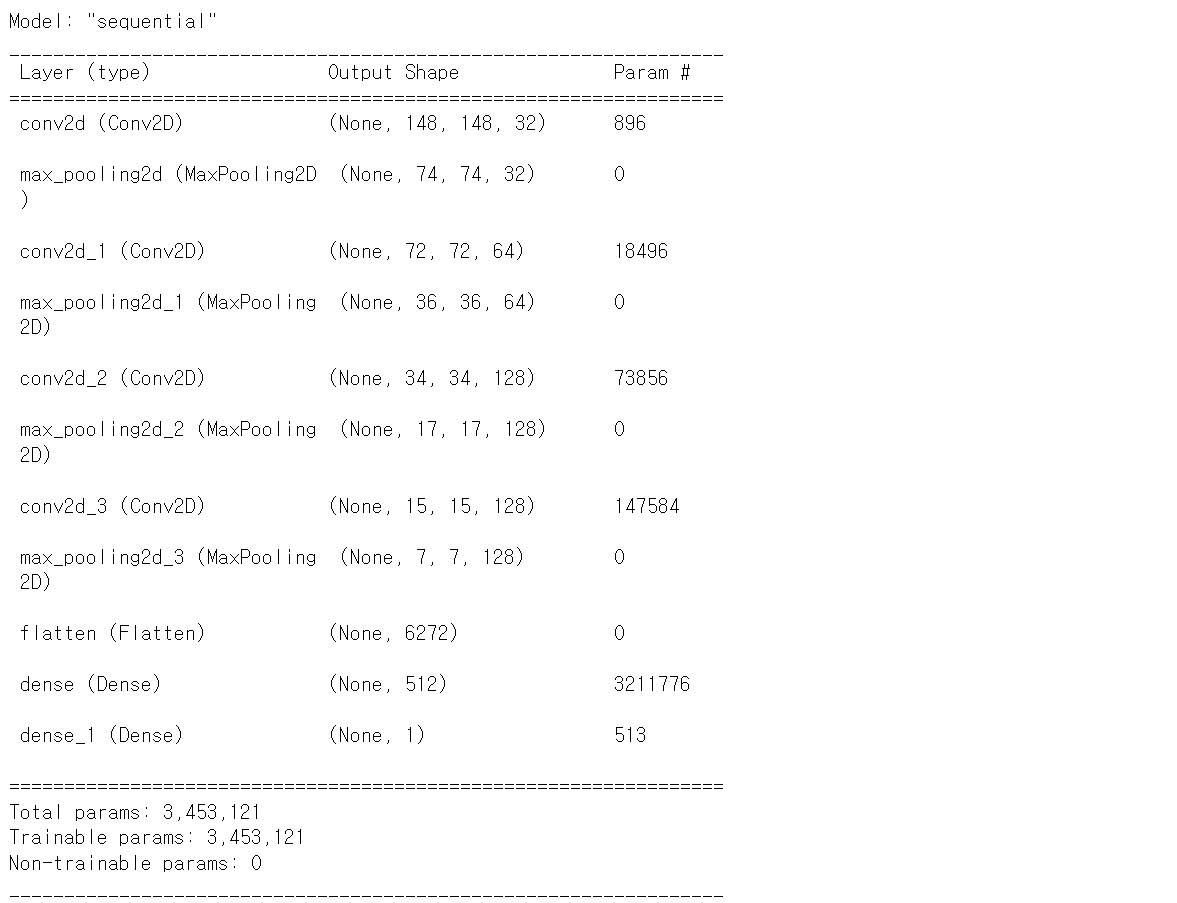
model = Sequential()
model.add(Conv2D(filters=32,
kernel_size=(3,3),
activation='relu',
input_shape=(150,150,3)))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=64,
kernel_size=(3,3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=128,
kernel_size=(3,3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=128,
kernel_size=(3,3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(units=512,
activation='relu'))
model.add(Dense(units=1,
activation='sigmoid'))
print(model.summary())
model.compile(optimizer=RMSprop(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['accuracy'])
## keep in mind that by default, batch_size is 32 in model.fit()
## steps_per_epoch = len(X_train) // batch_size
history = model.fit(train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)- 출력
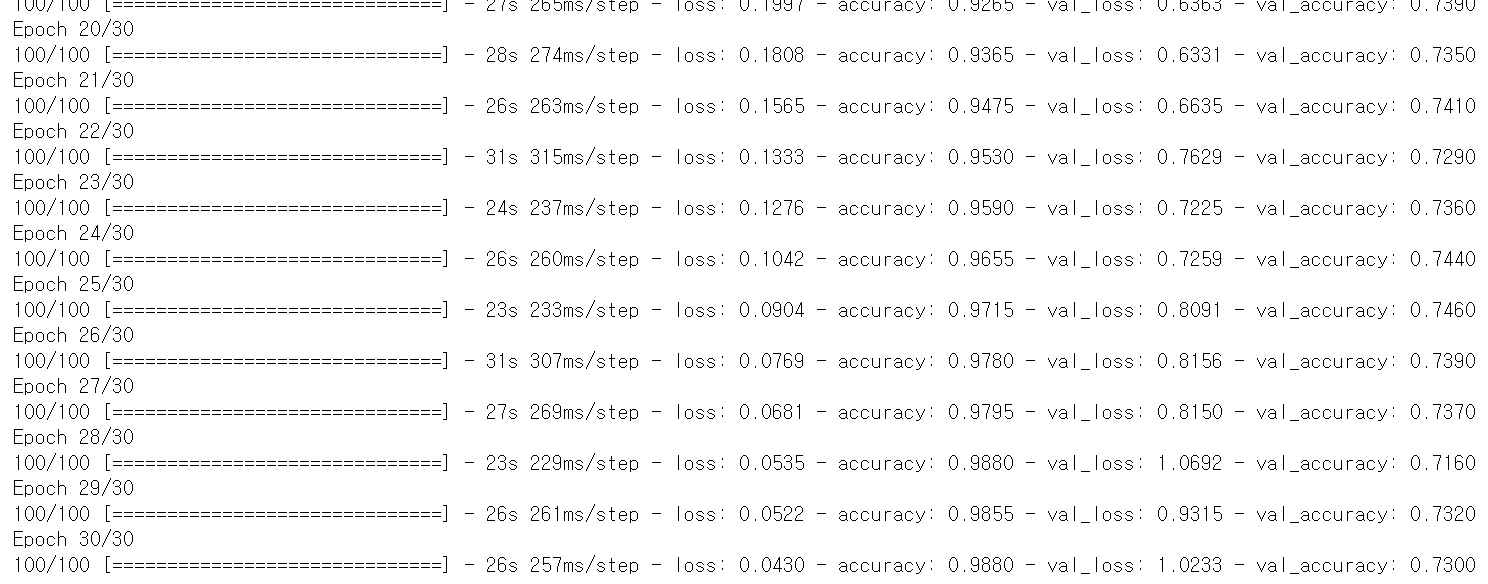
정리
당연히 학습이 더 잘 안 됐다.
-> 그럼 어떻게 해야 할까?
해결방식 2가지
- Augmentation(증식)
Augmentation(증식)
Augmentation 예제
- 코드
# data augmentation
from tensorflow.keras.preprocessing import image
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
datagen = ImageDataGenerator(rotation_range=20,
# 지정된 각도 범위내에서 임의로 원본이미지를 회전
width_shift_range=0.1,
height_shift_range=0.1,
# 지정된 방향 이동 범위내에서 임의로 원본이미지를 이동.
# 수치는 전체 넓이의 비율(실수)
shear_range=0.1,
# 밀림 강도 범위내에서 임의로 원본이미지를 변형.
# 수치는 시계반대방향으로 밀림 강도를 라디안으로 표시
zoom_range=0.1,
# 지정된 확대/축소 범위내에서 임의로 원본이미지를 확대/축소.
# "1-수치"부터 "1+수치"사이 범위로 확대/축소
horizontal_flip=True,
vertical_flip=True,
# 수평, 수직방향으로 뒤집기.
fill_mode='nearest')
img = image.load_img('./data/cat_dog_small/train/cats/cat.3.jpg',
target_size=(150,150))
x = image.img_to_array(img) # (150,150,3)
x = x.reshape((1,) + x.shape) # (1,150,150,3)
fig = plt.figure(figsize=(10,10))
axs = []
for i in range(20):
axs.append(fig.add_subplot(4,5,i+1))
idx = 0
for batch in datagen.flow(x, batch_size=1):
imgplot = axs[idx].imshow(image.array_to_img(batch[0]))
idx += 1
if idx % 20 == 0:
break
fig.tight_layout()
plt.show()- 출력

Cats and Dogs 1000장짜리 데이터로 증식 실습
모듈 불러오기
- 코드
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.layers import Flatten, Dense, Dropout
from tensorflow.keras.optimizers import Adam, RMSprop
from tensorflow.keras.preprocessing.image import ImageDataGenerator
train_dir = './data/cat_dog_small/train'
validation_dir = './data/cat_dog_small/validation'- 출력
없음
ImageDataGenerator 생성 - 설정
- 코드
# ImageDataGenerator 생성 - 설정
# 모든 이미지 데이터의 값을 1/255로 scaling 하면서 augmentation
train_datagen = ImageDataGenerator(rescale=1/255,
rotation_range=40,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# Validation data에 대해서는 당연히 증식을 사용하면 안된다.
validation_datagen = ImageDataGenerator(rescale=1/255)- 출력
없음
ImageDataGenerator 생성 - 실행
- 코드
train_generator = train_datagen.flow_from_directory(
train_dir, # target directory
classes=['cats', 'dogs'], # cats, dogs 순서로 label 0,1
# (생략하면 폴더순서로 label적용)
target_size=(150,150), # image size scaling
batch_size=32, # 한번에 32개의 이미지를 가져온다.
# label에 상관없이 가져온다.
class_mode='binary') # 고양이와 멍멍이만 존재하므로
# 2진 분류이기 때문에 binary
# 다중분류인 경우 'categorical'(기본값),
# 'sparse' 이용가능
# 오토인코더처럼 입력을 target으로 하는 경우 'input'
validation_generator = validation_datagen.flow_from_directory(
validation_dir,
classes=['cats', 'dogs'],
target_size=(150,150),
batch_size=32,
class_mode='binary')- 출력
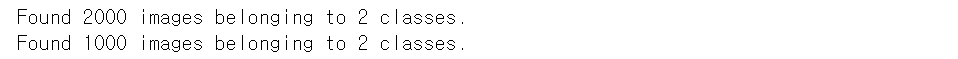
Model 생성
- 코드
model = Sequential()
model.add(Conv2D(filters=32,
kernel_size=(3,3),
activation='relu',
input_shape=(150,150,3)))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=64,
kernel_size=(3,3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=128,
kernel_size=(3,3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=128,
kernel_size=(3,3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dropout(rate=0.5))
model.add(Dense(units=512,
activation='relu'))
model.add(Dense(units=1,
activation='sigmoid'))
print(model.summary())
model.compile(optimizer=RMSprop(learning_rate=1e-4),
loss='binary_crossentropy',
metrics=['accuracy'])
## keep in mind that by default, batch_size is 32 in model.fit()
## steps_per_epoch = len(X_train) // batch_size
## validation_steps = len(X_test) // batch_size
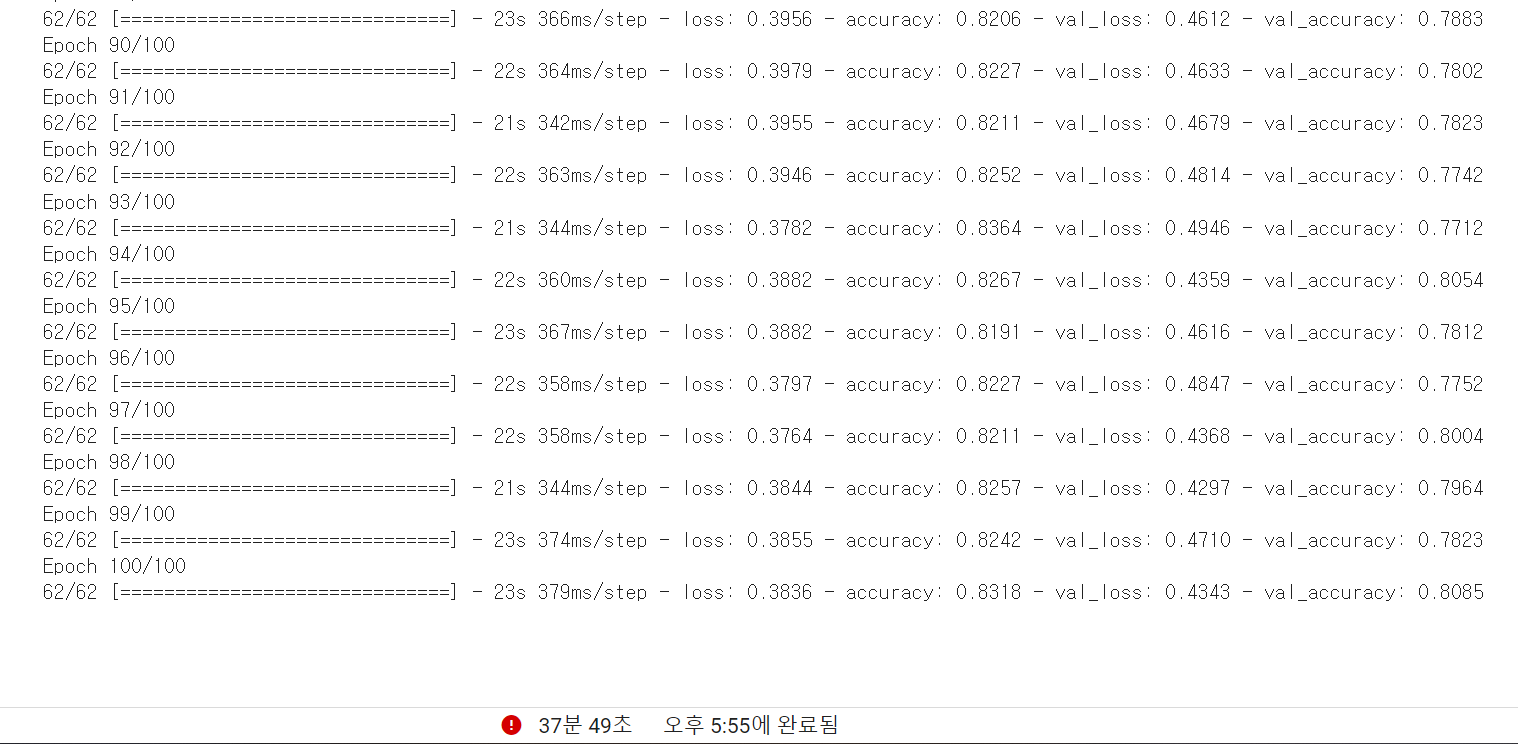
history = model.fit(train_generator,
steps_per_epoch=62,
epochs=100,
validation_data=validation_generator,
validation_steps=31)- 출력
커널이 터져버렸다... 메모리를 너무 많이 먹나..?
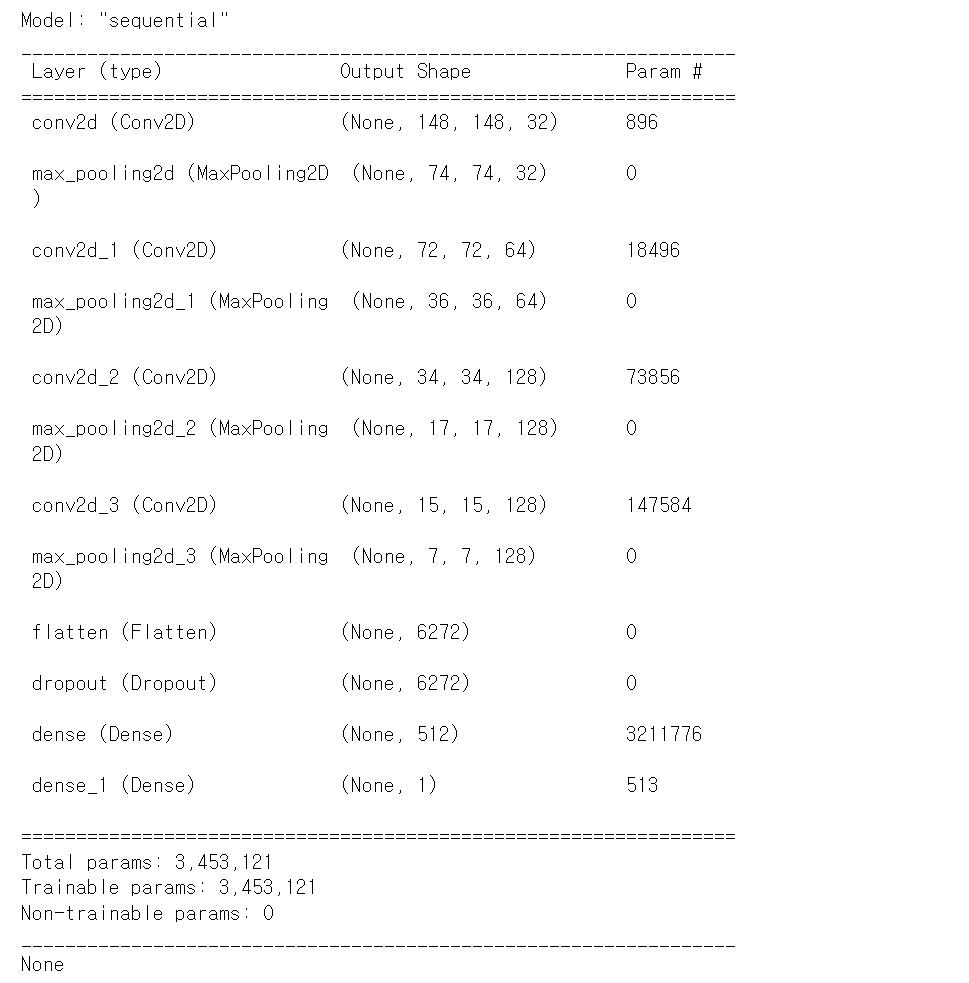
결과에서 None이 아니라 학습이 진행되면 정상.
증식(Cats and Dogs) - colab에서 진행
데이터 경로만 적당히 변경한 후, 실행
- 출력
실행 5분 후
한참 걸린다...
n분 후... (37분? 그 이상 걸린 것 같은데..?)