✏️ 쓰레드란 무엇인가
💻 프로세스 VS 쓰레드
-
멀티 프로세스가 필요한 경우
- OS 관점에서는 두 개 이상의 프로그램을 동시에 실행시키기 위해 기본적으로 필요.
- 하나의 프로그램은 하나의 흐름을 갖는다. 하나의 흐름 = 코드의 흐름
- 프로그램이 복잡해지면서 하나의 프로그램 안에서 둘 이상의 실행 흐름을 가지는 일이 생긴다.
- ex) 2인 전투 테트리스 => 하나의 프로그램 안에서 두 사람의 입력을 받아서 두 개의 실행 흐름을 보여줌.
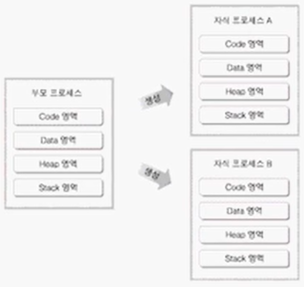
- 쓰레드를 공부하기 전에는 두 개의 프로세스가 필요하다는 생각을 하게 됨. ex) 두 개의 프로세스가 필요해질때 자식 프로세스를 생성
-
실행 흐름이 2개가 되기 위해 필요한 요소
- 프로세스가 생성이 되면 코드, 데이터, 힙, 스택 영역을 갖게 됨.
- 코드 영역: 프로그램의 코드가 올라가는 영역.
- 데이터 영역: 전역 변수
- 힙 영역: 동적할당된 메모리 공간이 저장됨.
- 스택 영역: 지역 변수, 매개 변수.
- 프로세스의 개수가 늘어나다보면 프로세스 간 컨텍스트 스위칭이 그만큼 잦아짐.
- 또한 OS는 프로세스의 커널 오브젝트를 생성해서 해당 프로세스를 관리해줘야 함. 이는 시스템 입장에서 부담스러움.
- 그렇다면 일단 시스템 입장에서 실행 흐름이 2개가 되기 위해서 필요한건 독립된 코드 영역.
- 프로세스가 생성이 되면 코드, 데이터, 힙, 스택 영역을 갖게 됨.
-
하나의 코드 영역을 2개의 실행 흐름으로 분리한다면?
- 실행 흐름은 연속된 함수의 호출. 따라서 스택 영역이 필요하다.
- 하나의 스택 영역을 나눠 쓰는 것이 가능하기는 하지만, 메모리 구조 상 하드웨어는 하나이기 때문에 결국 하드웨어 하나를 나눠쓰고 있는 것. 따라서 관리하기 힘듦.
- 흐름 A를 위한 스택, 흐름 B를 위한 스택을 두면 OS 입장에서 프로그램을 관리하기 편하지 않을까?
-
코드 영역은 나눠서 쓰되, 스택 영역은 분리가 필요
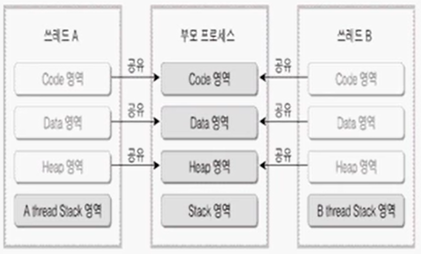
- 이는 멀티 프로세스가 아닌, 쓰레드의 개념.
- 부모 프로세스를 하나의 실행 흐름이라고 본다면, 스레드 A, 스레드 B라는 각 별도의 흐름이 존재.
- 코드 영역: 각 쓰레드의 코드 영역은 부모 프로세스의 코드 영역을 공유. 이는 부모 프로세스의 메모리 공간에 접근할 수 있다는 뜻. 부모 프로세스의 main() 함수를 공유한다는 뜻 X
- 데이터 영역: 자주 안 쓰이기 때문에 공유 가능.
- 힙 영역: 메모리 할당 시 철저하게 해제되기 때문에 공유 가능.
- 따라서 별도의 스택 공간만 만들어두면 하나의 프로세스 내에서 두 개의 실행 흐름을 만들어낼 수 있다는 것이 쓰레드의 개념.
-
프로세스
메모리 영역 -
스레드
부모 프로세스 내에서 별도의 실행 흐름을 만들어 동작하기 위해 프로세스의 코드, 데이터, 힙 영역을 공유하고, 스레드 자신의 별도의 흐름을 위해 존재하는 스택 + 코드 영역을 묶어 스레드라고 정의.
프로세스 같은 경우 별도의 프로그램. 스레드는 하나의 프로세스 안에서 동작하는 것이기 때문에 프로세스 + 스레드를 묶어서 하나의 프로그램이라 할 수 있다.
-
코드 상 쓰레드의 구현
- 쓰레드가 프로세스와 공유하는 영역들은 일단 없다고 생각
- 코드 영역에는 함수가 올라감.
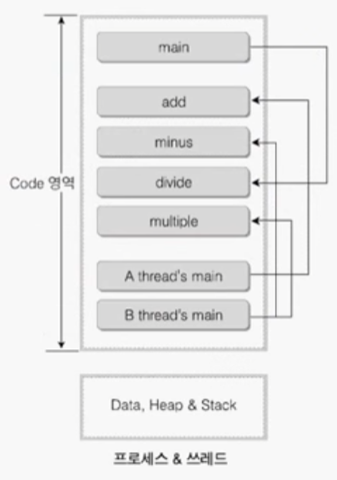
함수 -> 전역 함수, main() 함수 - 이 때 main() 함수는 하나의 실행 흐름. main() 이 여러 개라는 건 실행 흐름이 여러 개인 것.
- main() 함수는 프로세스가 생성되자마자 실행되고, 다른 main2(), main3()도 누군가에 의해 실행된다.
- 코드 영역을 공유한다는 건 코드 영역에 있는 리소스도 공유한다는 것.
- main() 함수가 원래의 프로세스, main2()와 main3()이 각 쓰레드 A, 쓰레드 B를 대표한다고 가정
- 전역 함수 Add가 있을 경우, 이는 코드 영역에 올라가 있을 것. 따라서 main() 함수들은 같은 코드 영역을 공유하기 때문에 Add를 호출할 수 있다.
- 마찬가지로 전역 변수를 선언하면, 이는 데이터 영역에 올라와 있기 때문에 사용 가능.
- 스레드 B가 힙에 메모리를 할당하면 해당 메모리에 스레드 A도 접근 가능하다.
- 프로세스의 경우, 서로 공유하는 메모리가 없기 때문에 IPC 통신 기법을 적용해야만 통신이 가능했음.
- 프로세스 - 스레드는 스택을 제외한 메모리 공간을 공유하기 때문에 별도의 통신 기법이 필요하지 않음.
그러나 스레드가 무조건 좋은 것은 아님. 이는 경우에 따라 다르다.
프로세스와 스레드가 담당하는 영역이 다르기 때문에 서로 다른 경우에서 사용되고, 멀티 프로세스로 해결해야하는 문제/멀티 쓰레드로 해결해야 하는 문제가 나뉜다.
💻 프로세스와 쓰레드의 관계
프로세스와 쓰레드는 코드 영역을 공유하기 때문에 main() 함수가 호출할 수 있는 모든 전역 함수는 쓰레드에서도 접근 가능.
💻 Windows에서의 프로세스와 쓰레드
이전까지 얘기했던 건 OS 관점에서의 쓰레드. 이번 장에서는 Windows 관점에서의 쓰레드에 대해 얘기해볼 것.
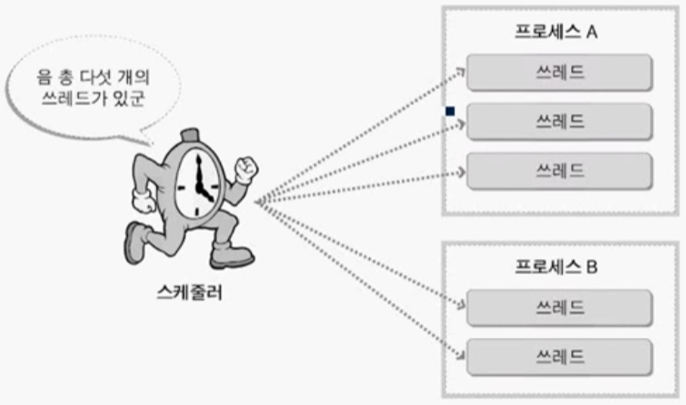
- 이전까지 배운 윈도우즈 스케줄러의 스케줄링 대상 -> 프로세스. 그러나 실제로 스케줄러의 스케줄링 대상은 쓰레드.
- 아래 사진에서 스케줄러는 프로세스 A와 B의 쓰레드를 합친 총 5개의 쓰레드를 관리하는 상황.
- 이전 OS 관점에서 상태 정보는 프로세스가 가지고 있다고 배웠지만, 윈도우즈에서 상태 정보는 쓰레드가 가지고 있다.
- 프로세스의 개념인 상태 정보(Running, Blocked, Ready), 우선 순위, 스케줄링 알고리즘 등은 쓰레드에 똑같이 적용됨.
- 프로세스의 경우 명확히 개념을 정의내릴 수 있지만, 쓰레드를 정의내리고 프로세스와 쓰레드를 명확히 나누는 것은 어려움.
- 따라서 "쓰레드 = 실행의 흐름" 으로 정의.
- 쓰레드를 구성하는 건 쓰레드의 메인 코드 + 독립적으로 할당된 스택
- 윈도우즈 관점에서 쓰레드는 프로세스 내 존재하는 실행의 흐름
- 실행의 주체 != 프로세스
main() 함수도 하나의 쓰레드에 의해 실행됨. 해당 쓰레드는 main 쓰레드. 즉 main쓰레드가 생성되어 main() 함수가 실행된다.
그렇다면 프로세스는 쓰레드를 감싸고 있는 껍질?
X. 데이터, 힙, 코드 영역은 쓰레드라 할 수 없음. 프로세스는 쓰레드가 실행될 수 있는 환경을 제공해주고, 그 환경 안에서 쓰레드가 동작한다.
✏️ 쓰레드 구현 모델에 따른 구분
💻 커널 레벨 쓰레드 VS 유저 레벨 쓰레드
해당 단원은 OS를 넘나드는 개발을 할 경우 매우 중요한 내용.
OS는 다음과 같이 구분할 수 있다.
- 멀티 쓰레드를 지원하는 OS vs 멀티 쓰레드를 지원하지 않는 OS
- 쓰레드를 지원하는 OS vs 쓰레드를 지원하지 않는 OS
- 쓰레드를 지원 = 커널이 쓰레드를 제공
- 쓰레드를 지원하지 않음 = 커널이 쓰레드 기능을 제공하지 않는다.
- 그럼에도 개발자가 쓰레드를 돌려야 할 경우 라이브러리 형태로 제공. 커널 또한 개발자가 만든 프로그램이기 때문에 개발자가 쓰레드를 만들어서 지원하는 것이 가능하다.
- 이처럼 유저(개발자)가 직접 만든 쓰레드 => 유저 레벨 쓰레드
- 커널이 만들어서 API 형태로 지원해주는 쓰레드 => 커널 레벨 쓰레드
OS(=커널 영역)만 설치되어 있는 상태에서 사용자는 필요한 라이브러리를 설치할 경우, (ex. ANSI 표준 Lib, DirectX3d lib, ...)
- OS만 설치되어 있는 상태 => 커널 영역
- OS를 제외한 모든 라이브러리 등 => 유저 영역
4GB 메모리 기준 각 영역이 2GB씩 차지.
쓰레드를 지원하는 라이브러리 또한 유저 영역에 포함.
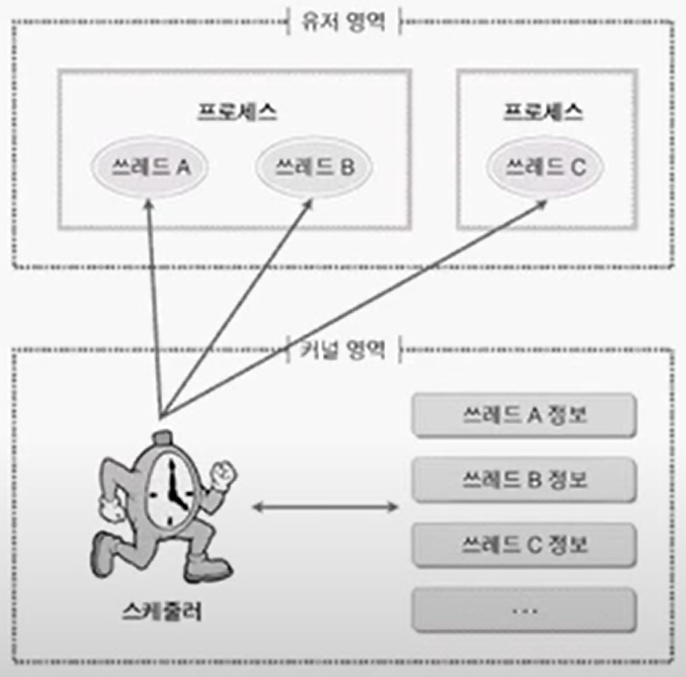
커널 레벨 쓰레드
- 커널이 쓰레드 기능을 제공 및 직접 관리.
- 관리한다 = 쓰레드의 존재 정보 및 쓰레드에 관한 정보를 가지고 있다.
- 따라서 스케줄러가 각 커널의 상태를 관리.
- 각 쓰레드는 우선 순위가 동일하다는 가정 하에 쓰레드 단위로 시간을 균등하게 분배받아서 실행됨.
유저 레벨 쓰레드
- 커널에게는 쓰레드가 라이브러리 모델로 제공이 되기 때문에 커널 입장에서는 그게 쓰레드인지 모름. 커널은 단순히 프로세스를 관리하는 입장.
- 프로세스 안에서 쓰레드가 동작하는 형태
- 프로세스 안에 쓰레드 정보가 있다 = 프로그래머가 메모리를 할당해서 쓰레드 정보를 넣은 것
- 우선 순위가 동일하다는 가정 하에 프로세스 단위로 실행 시간이 분배되고, 다시 쓰레드 단위로 시간을 나눠서 실행하는 형태.
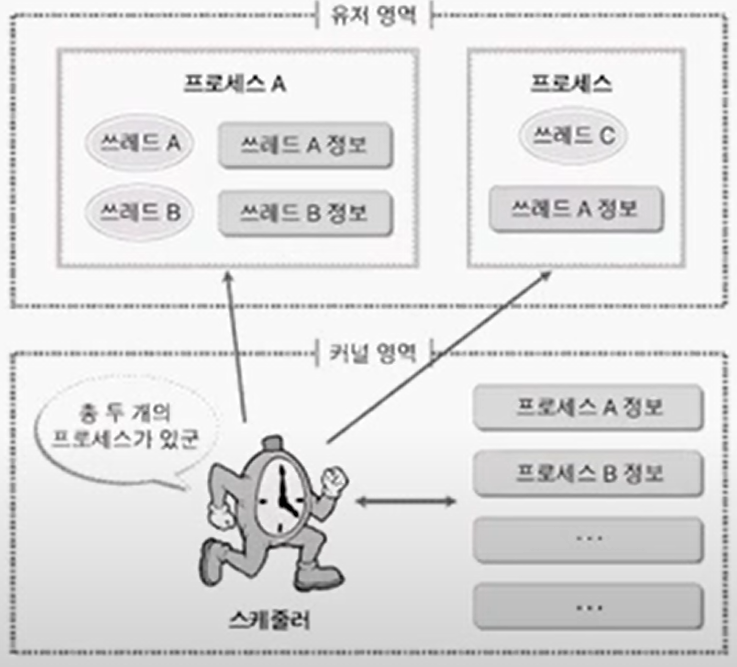
쓰레드 A가 I/O 상태에 빠져서(Blocked) 자신의 실행을 포기한다면 스케줄러는 다른 쓰레드에게 우선 순위를 넘길 것. 그러나 유저 레벨 쓰레드의 경우 스케줄러가 프로세스 단위로 스케줄링을 하기 때문에, 쓰레드 A가 실행을 포기하더라도 스케줄러는 해당 쓰레드의 존재를 모름. 따라서 다른 쓰레드에게 실행 권한을 줄 수 없다. 또한 한 쓰레드가 Blocked 상태에 빠졌을 때 해당 쓰레드를 포함한 프로세스 전체가 Blocked 상태에 빠짐.
이처럼 유저 레벨 쓰레드는 Blocked 상태에 빠졌을 때 문제가 있지만, 이러한 점을 고려해 프로그래밍을 한다면 속도 측면에서는 빠르다는 장점이 있음.
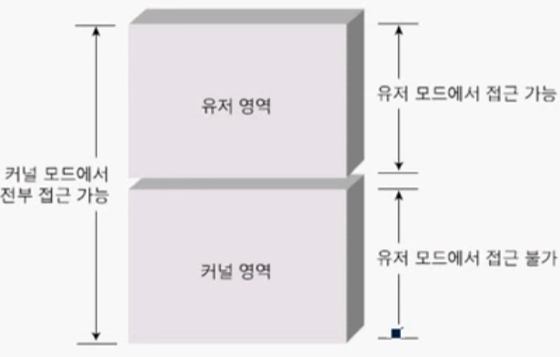
💻 커널 모드와 유저 모드
윈도우즈는 커널 모드 or 유저 모드 둘 중 하나의 모드를 가짐.
프로그램은 OS + Application으로 나뉨.
하드웨어 입장에서는 둘 다 하나의 프로그램.
그러나 OS를 일반적인 프로그램과 동일시한다면 다음과 같은 문제가 있다. 4GB 메모리 기준 OS와 Applicaion이 반 씩 나눠가짐. 이 때 OS가 가지는 2GB 모두 코드가 아니라, 실행을 위한 공간. OS의 코드 또한 해당 공간에 맵핑이 되긴 하는데, 메모리 주소 값을 가져야 OS에 F D E를 할 수 있기 때문.
프로세스 4개 실행할 경우, OS가 모든 영역에 동시에 존재? X
코드는 1개. 각 영역마다 일부 맵핑됨.
현재 0~4GB까지 메모리가 맵핑되어 있기 때문에 잘못된 메모리 접근을 할 수도 있음. 따라서 커널 모드/유저 모드를 나눠서 이를 방지.
커널이 실행될 때는 커널 모드로 진입되어 메모리 공간 어디던 접근 가능.
그러나 유저 모드, 즉 유저의 프로그램이 실행될 경우 커널 영역 메모리 접근을 막음.
-
커널 모드가 동작하는 경우
- 스케줄러의 동작
- 자식프로세스 생성
-
커널 레벨 쓰레드가 느린 이유
커널 레벨 쓰레드의 경우 쓰레드의 기능을 커널이 제공하고 커널이 관리해야 하는 대상인 쓰레드가 많다. 그리고 쓰레드를 생성할 때마다, 쓰레드 간의 컨텍스트 스위칭이 일어날 때마다 커널 모드로 진입해야 함.
반면 유저 레벨 쓰레드의 경우 관리하는 대상이 프로세스. 프로세스 단위로 관리를 할 때만 커널 모드로 진입하고, 같은 프로세스 내 쓰레드를 관리할 때는 커널 모드로 진입할 필요가 없기 때문에 비교적 속도가 빠르다.
-
커널 레벨 쓰레드의 장점 및 단점
- 장점: 커널에서 직접 제공해주기 때문에 안정성과 다양한 기능을 제공.
- 단점: 유저 모드에서 커널 모드로의 전환이 빈번
-
유저 레벨 쓰레드의 장점 및 단점
- 유저 모드에서 커널 모드로의 전환이 필요 없다
- 단점: 프로세스 단위 블로킹
