✏️ 쓰레드 풀에 대한 이해
💻 쓰레드 풀이란?
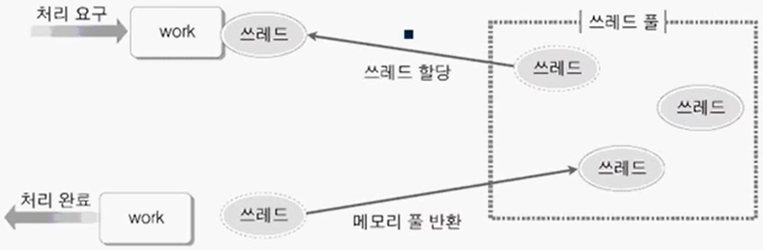
쓰레드를 미리 만들어서 쓰레드 풀에 저장해두고 일이 들어올 때마다 쓰레드를 할당해 일을 처리. 일을 마치면 반환된 쓰레드를 다시 쓰레드 풀에 넣어둬서 시스템의 전체적인 성능을 높여주는 매커니즘
프레임워크: 프로그램을 구현할 때 제공되는 틀. 프로그램이 완성되면 프레임워크의 부가적인 기능들과 함께 프로그램이 돌아간다.
쓰레드 풀을 대표적인 프레임 워크. 프로그래머가 직접 개발하지 않아도 사용할 수 있다.
쓰레드를 커널 오브젝트로 본다고 가정. 커널 오브젝트는 생성과 소멸에 많은 리소스를 동반한다. (메모리의 할당과 반환, OS에 해당 리소스에 대한 정보를 등록, 커널 모드 - 유저 모드 전환)
쓰레드같은 경우 스케줄러의 관리 대상이기 때문에 OS가 정보를 가지고 있고 + 스케줄러에 의해 감지되어야한다.
- 필요한 이유
처리해야 일이 10개가 있고 쓰레드 하나 당 1개의 일을 맡아서 처리한다고 가정하면, 총 10개의 쓰레드를 생성-소멸해야 한다. 그러나 10개의 일이 동시에 처리되는게 아니라, 시간 텀을 두고 들어온다면? 하나의 쓰레드만 생성하고 해당 쓰레드가 10개의 일을 모두 처리하도록 할 수 있다.
혹은 일이 2개, 3개, 5개.. 매번 다르게 들어온다면? 이 경우 요구되어지는 최대 쓰레드의 개수만큼 쓰레드를 미리 만들어두고, 이를 풀에 저장. 2개의 일이 들어왔을 때 쉬고 있는 2개의 쓰레드를 풀에서 꺼내 일을 처리. 먼저 나간 쓰레드의 일이 아직 안 끝났을 경우 풀에서 대기 중인 3개의 쓰레드가 다음번에 들어온 일을 처리. 그리고 일을 마친 쓰레드는 소멸되는게 아니라 다시 풀에 저장.
이처럼 쓰레드 풀을 통해 쓰레드의 생성-소멸을 줄일 수 있고, 이는 성능(속도) 향상으로 이어진다.
💻 쓰레드 풀의 구현
- 배울 내용
Work(작업)이 무엇인지, 그리고 작업을 어떻게 할당하는지.
쓰레드를 어떻게 쓰레드 풀에 저장하고 가져오는지.
// 작업이라는 건, 함수로 구현 가능함. 즉, 작업의 기본 단위는 함수.
// 반환 자료형과 매개변수 목록은 프로그래머 마음대로 가능.
typedef void(*WORK)(void);
// 사실 쓰레드 풀은 Framework라 했음. 즉, OS에서 제공되는 API들.
// 구현 하려면 마치 윈도우즈가 쓰레드를 관리하듯이, 우리도 비슷하게 구현 해보자.
// 이를 위해서 아래와 같은 구조체가 필요함. 단순하게 두 멤버만 추가함.
typedef struct __WorkerThread
{
HANDLE hThread;
DWORD idThread;
// 이외에도 우선순위와 같은 멤버도 추가 가능. 일의 성격, etc ...
} WorkerThread;
// Work와 Thread 관리를 위한 구조체. Thread Pool의 기본적인 모델. 꼭 이렇게 구현하라는 표준이 아님에 유의.
typedef struct __ThreadPool
{
// Work을 등록하기 위한 배열. 이는 풀 밖에 있을 수도 있음.
WORK workList[WORK_MAX];
// Thread 정보와 각 Thread별 Event Object
WorkerThread workThreadList[THREAD_MAX]; // Thread 정보를 저장할 수 있는 배열
HANDLE workerEventList[THREAD_MAX]; // Event Object 정보를 저장할 수 있는 배열
// Work에 대한 정보
DWORD idxOfCurrentWork; // 대기 1순위 Work Index.
DWORD idxOfLastAddedWork; // 마지막 추가 Work Index + 1.
// Number of Thread
DWORD idxOfThread; // Pool에 존재하는 Thread의 갯수.
} gThreadPool;- 쓰레드 풀 구현 시 필요한 정보
- 할당된 일의 정보
- 쓰레드 정보
- 각 정보는 배열로 들어가 있다.
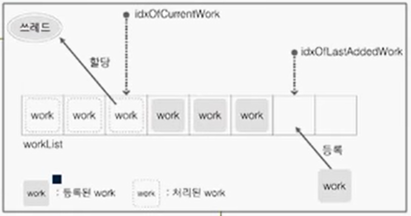
- workList 배열
- 작업을 등록하기 위한 배열
- 1) 일이 할당되면 함수 포인터(작업)를 배열에 순차적으로 저장
- 2) 저장된 함수 포인터를 하나씩 쓰레드에 할당해서 처리
- 현재는 단순 배열이기 때문에 가득 차면 일이 더이상 할당되지 않는 구조. Linked List나 원형 큐로 구현하는 것이 더 좋음.
- 쓰레드 등록
- 쓰레드 생성 + 이벤트 오브젝트 생성
- 각 쓰레드가 생성될 때 쓰레드 개수만큼 이벤트 오브젝트도 생성된다.
- 쓰레드가 풀에 있을 때는 일을 하지 않는 상태이기 때문에 스케줄러에 의해 스케줄링, 즉 시간을 할당받아서는 안 된다. 이처럼 작업이 없는 쓰레드를 잠재우기 위해서 이벤트 오브젝트가 필요하다.
- 쓰레드는 생성될 때 기본적으로 WaitForSingleObeject() 함수를 호출하고 이를 통해 이벤트 오브젝트를 감시. 생성과 동시에 이벤트는 Non-Singnaled 상태이기 때문에 쓰레드는 Blocked 상태가 된다. Blocked 상태의 쓰레드는 잠자고 있는 상태로, 스케줄러에 의해 스케줄링되지 않는다.
- 위 과정을 쓰레드 풀에 저장했다고 말한다. 소프트웨어적으로 쓰레드는 Blocked 상태이며, WaitForSingleObeject() 함수를 통해 쓰레드를 쓰레드 풀에 저장하게끔 유도하는 것.
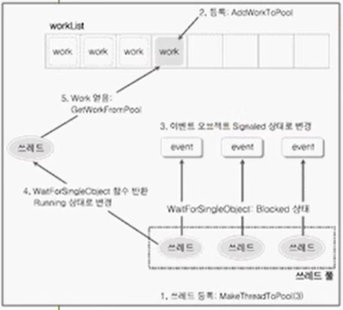
- Work 등록
- 작업이 배열에 등록되면 쓰레드를 관리하는 쓰레드 풀에서 쓰레드를 하나 깨움
- 쓰레드가 WaitForSingleObeject() 함수를 호출하게 해 이벤트 오브젝트를 Signaled 상태로 전환
- 이벤트 오브젝트가 Signaled 상태이기 때문에 쓰레드는 Blocked -> Running 상태로 전환됨
- Work 할당
- GetWorkFromPool() 함수를 통해 쓰레드가 workList에서 함수 포인터를 얻어오고, 이를 통해 함수를 호출
- 쓰레드 반환
- 함수 호출이 완료되면 하나의 작업이 끝난 것이기 때문에 다시 WaitForSingleObeject() 함수를 호출하며 루프.
다시 말해, 쓰레드는 자신에게 할당된 이벤트 오브젝트가 Signaled 상태인지 확인하기 위해 WaitForSingleObeject() 함수를 호출하고, 반환되면 GetWorkFromPool()를 통해 작업(함수 포인터)을 얻고 다시 WaitForSingleObeject() 호출.
이처럼 쓰레드 풀은 일이 끝나면 자기 스스로 반복되는 구조.
Intelligent Pool쓰레드의 개수를 상황에 따라 몇 개를 생성하고 소멸할지 중간에 결정 가능한 풀.
일이 생겼을 때 쓰레드를 생성하고 풀에 저장하려면 시간이 걸리기 때문에, 일이 없더라도 쓰레드 풀에는 미리 쓰레드가 저장되어 있어야 한다.
작업이 없을 때 쓰레드 풀에 쓰레드를 몇 개 까지 만들어서 저장해둘 것인지, 그리고 작업량이 생각보다 많을 때 쓰레드를 몇개 더 생성할지, 반대로 작업이 생각보다 없을 때 쓰레드를 몇 개 소멸할지에 대한 결정이 가능하다.
