
데이터 모델
데이터 베이스 시스템에서 데이터를 저장하는 이론적인 방법
( 데이터가 어떻게 구조화되어 저장되는지 결정 )
관계 데이터 모델 ( 가장 많이 사용되는 모델 )
SQL 언어는 비절차적인 언어로 원하는 데이터를 쉽게 표현
절차적 언어 : 명령어가 “순차적으로 실행”하는 것에 중점
ex) C언어
장점 : 프로그램 흐름 파악이 쉬움 / 실행속도 빠름
단점 : 유지보수 어려움 / 코드 순서 바뀌면 동일 결과 보장 X
객체지향적 언어 : 기능별로 “모듈화”, 중복 연상을 하지 않고 모듈을 재활용, 객제간 관계와 기능에 중심을 둔 언어
ex) C++, JAVA, Python
장점 : 재사용가능( 상속성 ) / 자연스러운 모델링 ( 우리가 사는 세계와 유사, 개발자가 생각하는 대로 자연스러운 구현 용이 )
단점 : 느린 개발 속도, 실행 속도 / 이해하는데 어려움
비절차적 언어 : 개발자가 처리 절차를 정하지 않고, 원하는 결과를 정의하고 요청하는 언어
ex) SQL
관계 데이터 모델 개념
릴레이션 ( relation ) : 행과 열로 구성된 테이블 표
관계 ( relationship ) : 릴레이션 내에서 생성되는 관계
ex) “고객” 과 “주문” 릴레이션의 관계, “상품”과 “주문” 릴레이션의 관계

릴레이션 스키마 ( relation schema ) : 릴레이션에 어떤 정보가담길지 정의 -> 표기법 : 릴레이션 이름 ( 속성A, 속성B, …. )
ex) 고객( 이름, 주소, 전화번호, 포인트, 등급 )
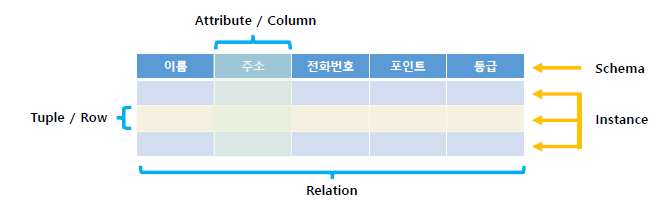
릴레이션 인스턴스 ( relation instance ) : 릴레이션 스키마에 실제로 저장된 데이터
투플 / 행 ( Tuple / Row )
속성 / 열 ( Attribute / Column )
속성 ( Attribute ) : Entity의 특성이나 속성을 의미 ( 가져오고 싶은 데이터 )
ex) 마트에서 고객 개체에서 알고 싶은 데이터
릴레이션 특징
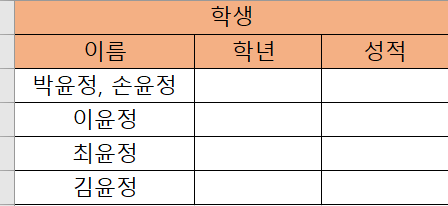
- 속성은 단일값을 가짐 : 1개의 값만을 가짐
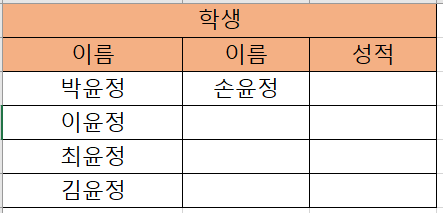
- 속성은 서로 다른 이름을 가짐
- 한 속성의 값은 모두 같은 도메인 값을 가짐 : 집합에 속한 값이 스키마에 관련된 값이어야 함
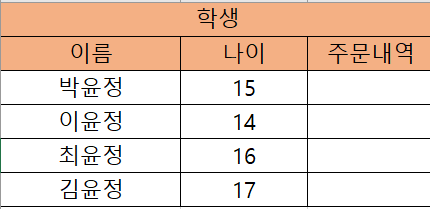
- 속성의 순서는 상관 없음
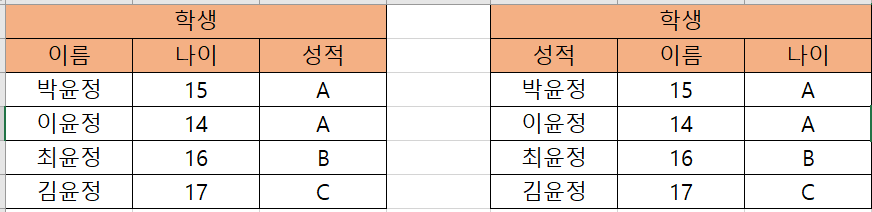
- 릴레이션 내의 중복된 투플(행) 허용 안됨
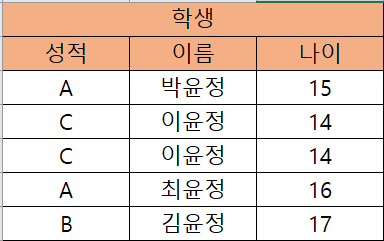
- 투플(행) 순서 상관없음
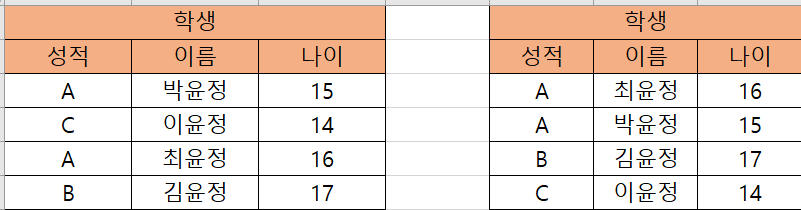
도메인 ( domain ) : 릴레이션의 각 속성이 가질 수 있는 값의 집합
ex) 학생 ( 학생번호, 이름, 주소, 운동 )
운동의 집합 = { 축구, 야구, 배구, 농구, …. } → 값의 집합을 도메인이라 함
실습01
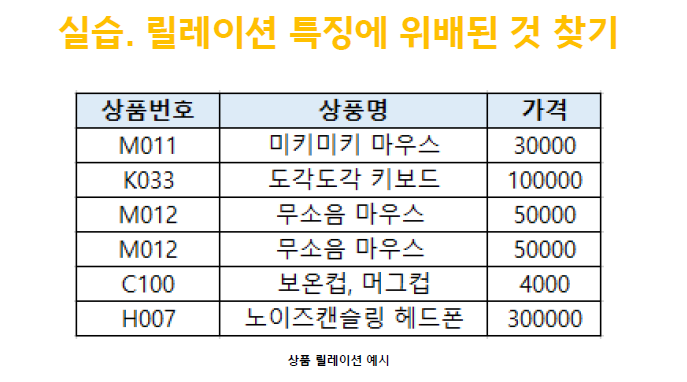
5번 위배 (투플 값 중복) → M012 무소음 마우스 50000
1번, 3번 위배 (속성 중복값 존재, 도메인) → 보온컵, 머그컵
실습02

학원
Relation : 강사, 학생, 교재
학생 Relation의 Attribute : 이름, 학년, 레벨, 학교명, 수업명, 담당강사명
Relationship ( 강사와 교재 ) : 어떤 강사가 어떤 교재를 사용하는지
✨Review
앞선 수업에서의 개념들, 개체, 속성, 관계 등등의 개념들에 대해 공부하였고, 이번 수업에서는 이제 개체들이 어떤 속성을 가지며, 그 속성들로 하여금 어떤 관계로 이어지는에 대한 내용을 학습하였다.
정형화 되지 않는 데이터들을 관계 데이터 모델링을 통해 구조화를 통해 저장되어질 수 있도록 한다. 음, 그러니까 존재하는 엄청 많은 데이터 중에 내가 필요한 데이터만을 사용하고 싶을 때, 정리하고 싶은 스타일로 추출할 수 있는 그런 게 아닐까 싶다... 그래서 이 데이터를 mySQL프로그램을 이용하여 SQL 언어로 데이터를 이렇게 저렇게 슉슉 짜잔 ! 내가 원하는대로 결과나오게 할려고 사용하는게 아닌가 싶다.
🐱🚀느낀점
데이터들간의 관계의 관점에서 많이 생각해봐야겠는 생각이 들었다. 개인적으로 앞서 10일간 배웠던 죽음의 C++보다는 한결 수업내용이 쉽게 다가왔다. 뭔가 C++ 배웠을 땐, 훨씬 더...뭐랄까 모래사장에서 바늘 찾기랄까? 망망대해 나혼자 두둥 떠다니는 느낌... 뭘 먼저, 어떻게 공부를 시작해야할지 너무 고민이 많았는데 SQL은 좀 공부할만 한 것 같다 ^^*
