1️⃣ K-means 개요
- K-means 는 비계층적 군집화 방법
- 군집의 개수(k)를 미리 정하고, 데이터를 각 군집의 중심과의 거리가 최소가 되도록 군집을 형성
- 주로 sklearn 라이브러리를 이용하여 구현
2️⃣ K-means 코드 예시
from sklearn.cluster import KMeans
import pandas as pd
# 예제 데이터
data = {'x': [1, 2, 1, 4, 5, 4, 6, 5, 8, 9, 8, 10],
'y': [1, 1, 2, 4, 4, 5, 7, 8, 1, 2, 0, 1]}
df = pd.DataFrame(data)
# Kmeans 군집화 모델 (군집 갯수 k = 3)
kmeans = KMeans(n_clusters=3, random_state=42)
# 군집화 적용
kmeans.fit(df)
# 결과를 데이터프레임에 추가
df['cluster'] = kmeans.labels_
print(df)→ 반환
| index | x | y | cluster |
|---|---|---|---|
| 0 | 1 | 1 | 2 |
| 1 | 2 | 1 | 2 |
| 2 | 1 | 2 | 2 |
| 3 | 4 | 4 | 0 |
| 4 | 5 | 4 | 0 |
| 5 | 4 | 5 | 0 |
| 6 | 6 | 7 | 0 |
| 7 | 5 | 8 | 0 |
| 8 | 8 | 1 | 1 |
| 9 | 9 | 2 | 1 |
| 10 | 8 | 0 | 1 |
| 11 | 10 | 1 | 1 |
3️⃣ K-means 시각화
✨ 시각화 코드 (Seaborn 이용)
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
# 예시 데이터 생성
data = {
'x': [1, 2, 3, 8, 9, 10],
'y': [1, 2, 3, 8, 9, 10],
'cluster': [0, 0, 0, 1, 1, 1]
}
# DataFrame 생성
df = pd.DataFrame(data)
# 시각화
sns.lmplot(x='x', y='y', data=df, hue='cluster', fit_reg=False, legend=True)
plt.title('K-means Clustering')
plt.show()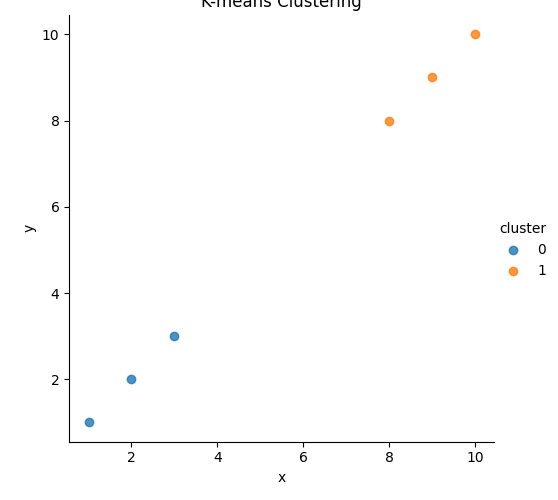
4️⃣ Iris 데이터 군집화
✨ Iris 데이터 로딩 및 K-means 적용
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
import pandas as pd
# Iris 데이터 로딩
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
# Kmeans 모델 (군집 갯수 k=3)
kmeans = KMeans(n_clusters=3, random_state=42)
# 군집화
kmeans.fit(df)
df['cluster'] = kmeans.labels_
print(df.head())→ 반환
sepal length (cm) sepal width (cm) ... petal width (cm) cluster
0 5.1 3.5 ... 0.2 1
1 4.9 3.0 ... 0.2 1
2 4.7 3.2 ... 0.2 1
3 4.6 3.1 ... 0.2 1
4 5.0 3.6 ... 0.2 1
[5 rows x 5 columns]5️⃣ Iris 데이터 시각화
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
import pandas as pd
# Iris 데이터 로딩
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
# Kmeans 모델 (군집 갯수 k=3)
kmeans = KMeans(n_clusters=3, random_state=42)
df['cluster'] = kmeans.fit_predict(df)
# 시각화
plt.scatter(df['petal length (cm)'], df['petal width (cm)'], c=df['cluster'], cmap='viridis')
plt.xlabel('petal length (cm)')
plt.ylabel('petal width (cm)')
plt.title('K-means Clustering of Iris Dataset')
plt.colorbar(label='Cluster')
plt.show()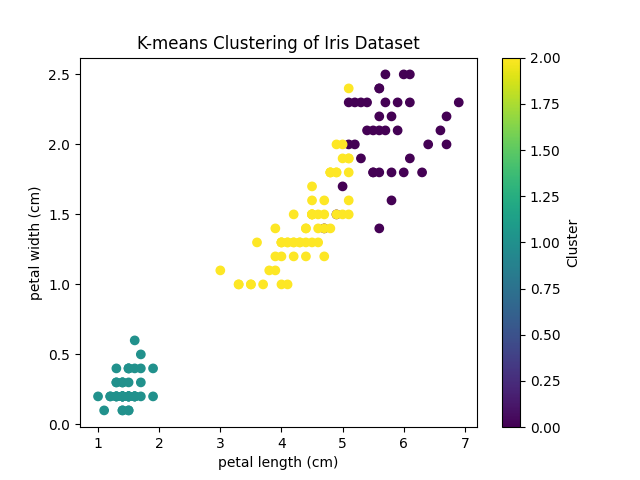
🚀 정리
✅ K-means 주요 특징
- 군집 수(k) 를 미리 정해야 함
- 각 군집 중심과의 거리 최소화를 통해 군집화
- 빠르고 직관적이며 대용량 데이터에 적합
✅ 활용 분야
- 데이터 탐색 및 초기 분석
- 고객 세분화, 이미지 및 문서 분류 등 다양한 분야 활용 가능
✅ 장단점
- 장점: 직관적이고 빠름, 이해하기 쉬운 알고리즘
- 단점: 초기 군집 중심 선정에 따라 결과가 달라질 수 있음
Hello World