사용한 자료구조 : 그래프
사용한 알고리즘 : BFS(Breadth-First Search)
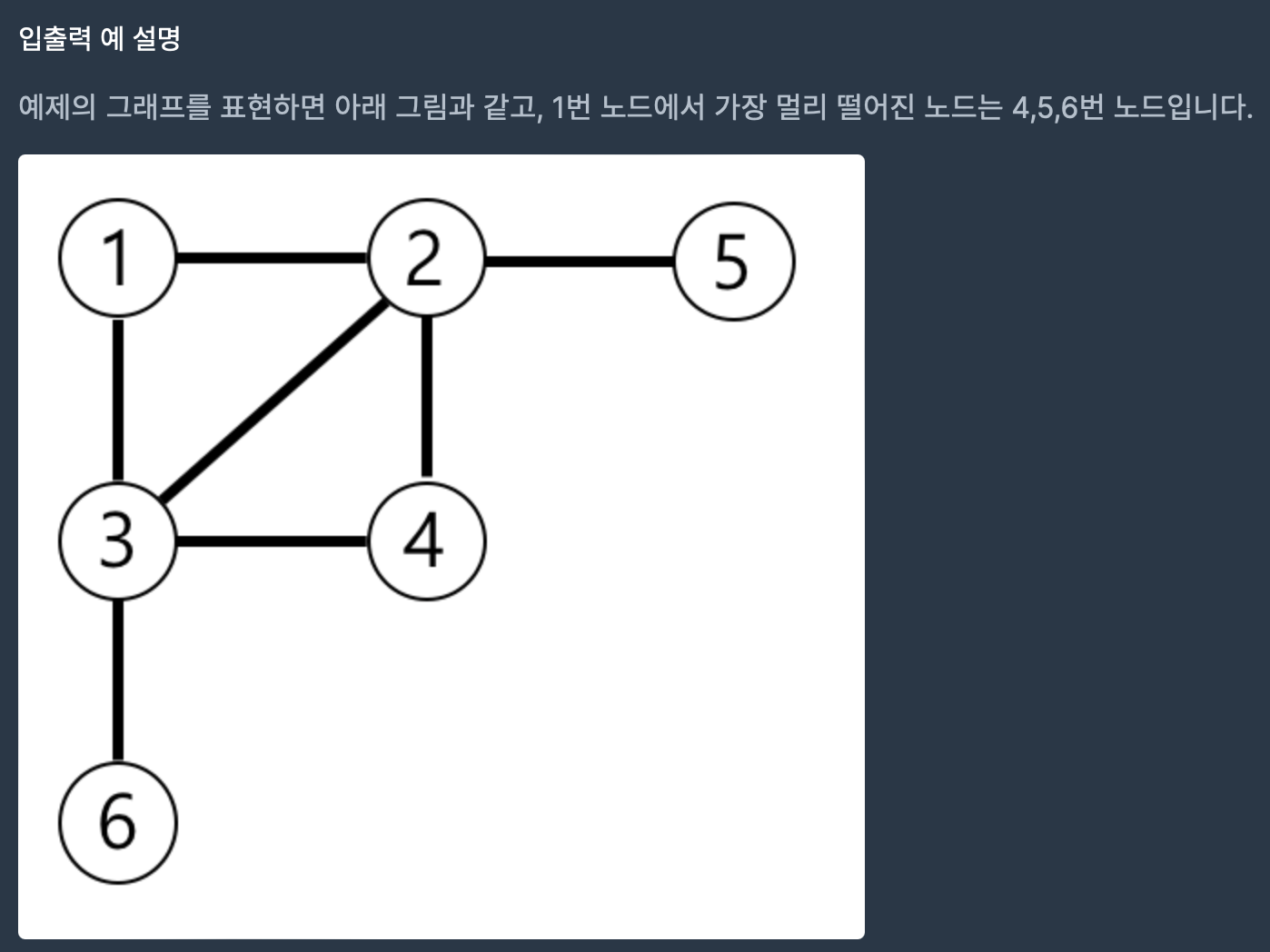
참고)해당 문제를 표 로 그려보면
(1 은 인접한 노드, 0은 인접하지 않은 노드)
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| 2 | 1 | 0 | 1 | 1 | 1 | 0 |
| 3 | 1 | 1 | 0 | 1 | 0 | 1 |
| 4 | 0 | 1 | 1 | 0 | 0 | 0 |
| 5 | 0 | 1 | 0 | 0 | 0 | 0 |
| 6 | 0 | 0 | 1 | 0 | 0 | 0 |
이 된다.
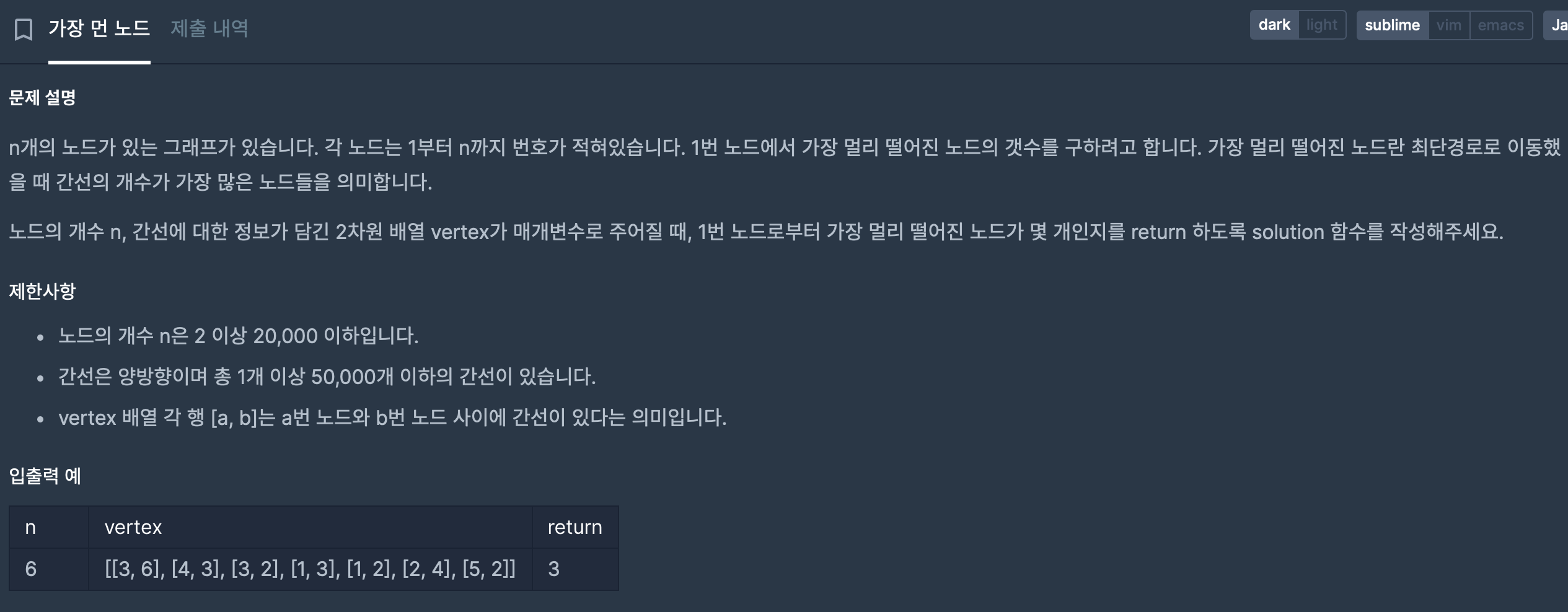
문제의 핵심은 1번 노드에서 가장 멀리 떨어진 노드가 몇개인지 구현하는 것
📌인접그래프 표현하기
-
matrix 2차원 배열을 초기화해줄때, n * n 이 아닌
(n + 1) * (n + 1) 으로 해주는 이유는 인덱스의 시작번호는 0번 부터 시작하기 때문에 직관적으로 알기쉽게 하려고 0번 인덱스는 사용하지 않는다. 그러므로 인덱스 크기를 하나 더 늘려주는것. -
양방향 그래프이기 때문에 두 노드들 간의 연결을 양방향으로 설정
(1 은 인접한 노드, 0은 인접하지 않은 노드)
int[][] matrix = new int[n + 1][n + 1];
for (int[] ed : edge) {
matrix[ed[0]][ed[1]] = 1;
matrix[ed[1]][ed[0]] = 1;
}📌BFS 구현 함수
❗️ BFS는 꼭 필요한것이 방문여부를 체크할 배열과 큐가 필요하다.
해당 문제에서는 추가적으로 모든 노드들의 거리를 확인해야 하기때문에,
1. Boolean 배열 (방문여부 체크)
2. Queue 자료형 (FIFO. 선입선출)
3. 방문했던 거리를 저장할 배열 (return 값)
이 필요했다.
1. 거리 배열과 방문 배열 크기도 직관적으로 알기쉽게 n + 1 씩 크게 만듦.
2. 시작(start) 지점을 1로 지정
3. 거리 배열은 모두 무한값으로 초기화 하고, 시작 정점의 거리는 0으로 설정
4. 방문 배열의 시작지점은 이미 방문했다는 표시로 설정
5. 큐에 시작 노드를 추가하고 탐색을 시작
6. while 반복문으로 큐가 비어있지 않을때 동안
7. 큐에서 노드를 꺼내고, 해당 노드의 인접한 노드들을 탐색
8. 아직 방문한 노드가 아니라면, 거리배열을 1로 업데이트 하고 큐에 추가public int[] bfs(int[][] matrix, int n) {
int[] distance = new int[n + 1];
boolean[] visited = new boolean[n + 1];
int start = 1;
Queue<Integer> queue = new LinkedList<>();
Arrays.fill(distance, Integer.MAX_VALUE);
distance[start] = 0;
visited[start] = true;
queue.add(start);
while (!queue.isEmpty()) {
int cur = queue.poll();
for (int i = 1; i <= n; i++) {
if (matrix[cur][i] != 0 && !visited[i]) {
distance[i] = distance[cur] + 1;
visited[i] = true;
queue.add(i);
}
}
}
return distance;
}
해당 알고리즘으로 현재 distance 배열안에는
[2147483647, 0, 1, 1, 2, 2, 2] 로 만들어졌다.
📌solution 함수로 돌아와 최대거리 찾기
- bfs 함수를 받아 max 변수에 최대값을 얻었다.
아래 작업으로 max 변수에는 2가 들어가있다
int[] distance = bfs(matrix, n);
int max = Integer.MIN_VALUE;
for (int i : distance) {
if (i != Integer.MAX_VALUE) {
max = Math.max(max, i);
}
}📌최대거리의 갯수 찾기
- max 값은 현재 2 이므로 동일한 거리에 있는 노드들의 갯수를 세는 cnt변수가 필요.
현재 cnt 변수안에는 3이 들어있음
int cnt = 0;
for (int i : distance) {
if (i == max) {
cnt++;
}
}
return cnt;
}💻 최종 코드 💻
import java.util.*;
class Solution {
public int solution(int n, int[][] edge) {
int[][] matrix = new int[n + 1][n + 1];
for (int[] ed : edge) {
matrix[ed[0]][ed[1]] = 1;
matrix[ed[1]][ed[0]] = 1;
}
int[] distance = bfs(matrix, n);
int max = Integer.MIN_VALUE;
for (int i : distance) {
if (i != Integer.MAX_VALUE) {
max = Math.max(max, i);
}
}
int cnt = 0;
for (int i : distance) {
if (i == max) {
cnt++;
}
}
return cnt;
}
public int[] bfs(int[][] matrix, int n) {
int[] distance = new int[n + 1];
boolean[] visited = new boolean[n + 1];
int start = 1;
Queue<Integer> queue = new LinkedList<>();
Arrays.fill(distance, Integer.MAX_VALUE);
distance[start] = 0;
visited[start] = true;
queue.add(start);
while (!queue.isEmpty()) {
int cur = queue.poll();
for (int i = 1; i <= n; i++) {
if (matrix[cur][i] != 0 && !visited[i]) {
distance[i] = distance[cur] + 1;
visited[i] = true;
queue.add(i);
}
}
}
return distance;
}
public static void main(String[] args) {
int n = 6;
int[][] edge = {
{3, 6}, {4, 3}, {3, 2}, {1, 3}, {1, 2}, {2, 4}, {5, 2}
};
Solution sol = new Solution();
System.out.print(sol.solution(n, edge));
}
}
이대로 제출했더니 정답률이 77.8%
제한사항을 살펴보니, 메모리 관련해서 문제가 있었던것 같다.

제한사항에 따르면 노드개수는 최대 20,000개
간선개수는 최대 50,000개
즉,
n = 20,000
e = 50,000
인접행렬을 사용하면 메모리 사용량은 O(n^2)
즉, 20,000 * 20,000 = 400,000,000,000 = 약 373 GB
인접리스트로 사용하면 메모리 사용량은 O(n + e)
정점의 메모리(n) 20,000 * 32 = 640,000 = 625KB
간선의 메모리(e) 50,000 * 4 = 200,000 = 195KB
640,000 + 200,000 = 820KB
ArrayList 객체의 오버헤드는 대략 32 byte
각 간선은 4 byte의 정수로 저장.
😱인접 행렬과 인접 리스트는
엄청난 용량 차이가 있었다는것을 알게 되었다.
인접 행렬
장점 : 간선 존재 여부를 빠르게 확인할 수 있다.
단점 : 메모리 사용량이 크다.
인접 리스트
장점 : 메모리 사용이 적다.
단점 : 두 노드 간의 간선 존재 여부를 확인하는데 시간이 더 걸릴 수 있다.로 정리할수 있겠다.
📌solution 함수
- 특별히 바뀐건 2차배열을 사용한 방식(인접행렬) 이 아닌
이중 리스트로 그래프를 구현for (int i = 0; i <= n; i++)
{ list.add(new ArrayList<>()); }
해당 반복문으로 각 배열들을 초기화
List<List<Integer>> list = new ArrayList<>();
for (int i = 0; i <= n; i++) {
list.add(new ArrayList<>());
}
for (int[] ed : edge) {
list.get(ed[0]).add(ed[1]);
list.get(ed[1]).add(ed[0]);
}📌bfs 함수
- List를 사용했기 때문에 해당 함수에서도 마찬가지로 for 반복문이 아닌 향상된 for문을 사용하였다.
for (Integer i : list.get(cur)) {
if (!visited[i]) {
distance[i] = distance[cur] + 1;
visited[i] = true;
queue.add(i);💻 2차 최종 코드 💻
import java.util.*;
class Solution {
public int solution(int n, int[][] edge) {
List<List<Integer>> list = new ArrayList<>();
for (int i = 0; i <= n; i++) {
list.add(new ArrayList<>());
}
for (int[] ed : edge) {
list.get(ed[0]).add(ed[1]);
list.get(ed[1]).add(ed[0]);
}
int[] distance = bfs(list, n);
int max = Integer.MIN_VALUE;
for (int i : distance) {
if (i != Integer.MAX_VALUE) {
max = Math.max(max, i);
}
}
int cnt = 0;
for (int i : distance) {
if (i == max) {
cnt++;
}
}
return cnt;
}
public int[] bfs(List<List<Integer>> list, int n) {
int[] distance = new int[n + 1];
boolean[] visited = new boolean[n + 1];
int start = 1;
Queue<Integer> queue = new LinkedList<>();
Arrays.fill(distance, Integer.MAX_VALUE);
distance[start] = 0;
visited[start] = true;
queue.add(start);
while (!queue.isEmpty()) {
int cur = queue.poll();
for (Integer i : list.get(cur)) {
if (!visited[i]) {
distance[i] = distance[cur] + 1;
visited[i] = true;
queue.add(i);
}
}
}
return distance;
}
public static void main(String[] args) {
int n = 6;
int[][] edge = {
{3, 6}, {4, 3}, {3, 2}, {1, 3}, {1, 2}, {2, 4}, {5, 2}
};
Solution sol = new Solution();
System.out.print(sol.solution(n, edge));
}
}👏👏👏👏👏👏👏👏👏

👉BFS 알고리즘 - 너비 우선 탐색
BFS 알고리즘은 시작 정점(vertax) 부터 가까운 노드부터 차례대로 탐색을 시작한다.
각 레벨을 탐색하고, 다음 레벨로 이동한다
- 시작 정점을 큐에 추가 한다
- 각 정점까지의 거리 배열을 초기화 한다.(무한대로 설정 후 시작 정점의 거리를 0으로 설정)
- 큐에서 정점을 꺼내고, 해당 정점의 이웃 노드를 확인한다.
- 이웃 노드가 아직 방문되지 않은 경우 (거리 배열이 무한대인 경우), 해당 이웃 노드의 거리를 현재 정점의 거리 + 1 로 설정하고, 큐에 추가한다.
- 큐가 비어있을 때까지 탐색을 계속한다.
장점
- 가중치가 없는 그래프에서(각 간선의 가중치가 동일할 때) BFS는 최단 경로를 보장한다.
- 레벨순서대로 노드를 탐색하기 때문에, 특정 노드까지의 거리를 단계별로 알 수 있다. 예를들면 해당 문제를 풀이하는데 유용하다.
- 시작 정점의 모든 이웃을 방문한 후, 다음 레벨의 노드를 방문하기 때문에 그래프의 구조를 넓게 탐색할 때 유용하다.
- 큐를 사용하기 때문에, 코드가 상대적으로 단순하고 직관적이다.
단점
- 탐색중에 큐를 사용하여 모든 노드를 저장하므로, 큰 그래프의 경우 메모리 사용량이 많이 증가할 수 있다. 즉, 노드와 간선의 수가 많을수록 메모리 사용이 급격히 증가할 수 있다.
- 간선의 수가 많은경우 모든 노드와 간선을 탐색하므로, 탐색 시간이 길어질 수 있다.
- 가중치가 있는 그래프의 경우에는 최단경로를 보장하지 않는다. 가중치가 있는 그래프의 경우 다익스트라(Dijkstra) 알고리즘이 좋을거 같다.