유의성검정, 유의확률과 AB테스트
AB테스트의 결과분석은 주로 빈도주의 관점에서 유의성 검정(NHST)를 따른다. 유의성 검정이란 기존 이론이나 법칙을 부정하는 것으로 보이는 현상이 관측되었을 때, 이 현상이 반증으로서 얼마나 강력한지 그 강도를 검증함으로써 기존의 이론이나 법칙을 부정하거나 개선할지를 결정하는 검증방법이다.유의성 검정에서의 그 강도를 측정하는 기준이 바로 P-value, 유의확률이다.
AB테스트에서 P-value를 활용하면 수치적으로 타당성을 확보할 수 있지만 이 유의확률에만 신경을 쓰게된다면 실험 결과를 편향되게 해석할 수 있다. 유의성 검정을 하는 이유는 개선안이 얼마나 효과가 있는지를 살펴보는 것이지 통계적 유의성(Statistical Significnace)을 확보하는 것이 아니다!
p-value
통계를 활용한 실험을 할 때 유의해야하는 상황은 유의미한 상황이 나올 때까지 불필요한 자원을 지출하지 않는 것이다. 실험을 너무 일찍 끝내지도, 너무 오래 끌지도 않으면서 유의미한 결과가 나오기 위해서 개념에 대해 복습을 해보고자 한다.
가설검정
AB테스트에서 가설검정은 A와 B의 전환율로 나타낼 수 있다. A와 B의 전환율을 각각 와 로 나타낸다면 귀무가설(Null Hypothesis,)와 대립가설(Alternative Hypothesis, )는 아래와 같이 나타낼 수 있다. 아래는 양측 검증인 상황에서의 귀무가설과 대립가설이다.
:
:
즉, 귀무가설은 A와 B의 전환율은 차이가 없다라고 표현할 수 있고 대립가설은 A와 B의 전환율에는 차이가 있다라고 정의할 수 있다.
1종 오류와 2종 오류
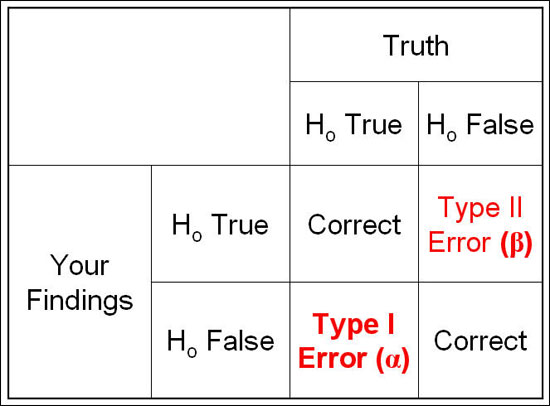
1종오류 : Type 1 Error, 귀무가설이 사실인데 기각할 오류.
2종오류 : Type 2 Error, 귀무가설이 거짓인데 기각하지 않을 오류.

임신하지 않은 사람에게 임신했다고, 즉 없는데 있다고 할 오류는 1종 오류.
임신한 사람에게 임신하지 않았다고, 즉 있는데 없다고 할 오류는 2종 오류이다.
오류가 생겼다면 어떤 오류들을 방지할 것인지에 대해서도 논의할 필요가 있다.
없는데 있다고 하는 1종 오류와 있는데 없다고 하는 2종 오류 중 무엇이 더 심각한 오류일까?
이는 문제에 따라 상이하다. 암이 없는데 있다고 하는 오류보다 암이 있는데 없다고 하는 오류가 더 심각하겠지만 어떤 정책이 마련된 근거가 없는데 있다고 하는 것은 있는데 없다고 하는 것보다 심각할 것이다.
일반적으로 이러한 오류의 기준은 5%가 많이 책정된다. 유의수준 95%의 확률에서~라던가 p-value<0.05에서의 5%는 여기에서 비롯되었다.
효과크기를 무시한 유의성 검정?
두 실험군의 차이가 비슷한데 통계적으로 유의한 차이를 얻으면 과연 좋을까?
이 의문에 대해 어느 정도 해답을 줄 수 있는 키워드가 효과크기(Effect Size)이다.
효과크기란 비교하려는 집단 사이에 얼마나 연관성이 있는지(즉, 얼마나 차이가 있는지)를 나타내는 지표이다. 효과크기를 살펴보면 좋은 점은 P-value가 샘플사이즈에 영향을 받는 것과는 달리 샘플의 크기에 영향을 덜 받기 때문이다. 적절한 표본 수 산출 과정을 통해 연구에 필요한 표본 수를 계산했다하더라도 표본 수의 계산 과정이 많은 가정을 바탕으로 이루어지기 때문에 실제 연구 과정에서 기존 가정과 다른 상황이 발생하게 되는 경우 P>0.05인 결과가 나온다거나 비교하려는 집단 사이의 실제 차이와의 괴리 등은 overpower의 문제가 생기곤 한다. 효과크기는 실제 차이를 파악하여 수치화한 것으로 여러 연구결과를 효과크기라는 표준화된 수치로 나타내어 메타분석에 사용할 수 있다.
효과크기란 비교하려는 집단 사이에 '얼마나' 차이(혹은 연관성)가 있는지를 나타내 주는 지표.
비교하려는 집단들 사이의 차이 혹은 관계를 나타내는 표준화된 지표를 의미한다.
standardized measure of the size of the mean difference or the relationship among the study groups.
p-value는 관찰된 현상이 기존에 알려진 확률 분포와 비교해 볼 때 어느 정도로 희귀하게 발생하는지에 대한 확률적 의미를 가지고 있지만 효과크기는 실제 관찰된 데이터에서 비교하려는 집단 사이의 차이 혹은 연관성을 직접적으로 기술해주는 장점을 가지고 있다. 이러한 특성으로 인해 추론 통계에서는 주로P-value를, 기술 통계에서는 효과크기를 활용할 수 있다.
효과크기는 실제 효과가 큰 지 혹은 작은 지에 대해 정보를 제공하며 효과 크기가 크다는 것은 실험의 효과가 크다는 것을 의미하며 효과의 크기가 0이라는 것은 실험 효과가 없음을 나타낸다.
귀무가설이 남녀의 성별 비율이 50:50이라고 할 때 어떤 집단에서 남녀의 비율이 53:47이라고하면 효과크기는 3%가 된다. 만약 전 인구의 평균 IQ가 100이라고 할 때 어떤 집단에서의 평균 IQ가 120이라고 하면 효과크기는 20IQ Unit이 된다.
참고자료
A/B테스트에서 p-value에 휘둘리지 않기
데이터 분석 : 기초통계 with R(유의성 검정)
[그림출처](: http://epiville.ccnmtl.columbia.edu/popup/power_and_sample_size_introduction.html)
