데이터베이스
데이터는 정보로서의 데이터를 말한다.
1. 통합된 데이터: 자료의 중복을 배제한 데이터의 모임
2. 저장된 데이터: 컴퓨터가 접근할 수 있는 저장매체에 저장된 자료
3. 운영 데이터: 조직의 고유한 업무를 수행하는데 존재가치가 확실하고 업서서는 안될 반드시 필요한 자료
4. 공용 데이터: 여러 응용 시스템들이 공동으로 소유하고 유지하는 자료
엑셀에 정리한 자료나 핸드폰의 연락처도 데이터베이스가 될 수 있다.
리소스와 데이터베이스의 개념을 분리해야한다.
API(Application Programming Interface)란?
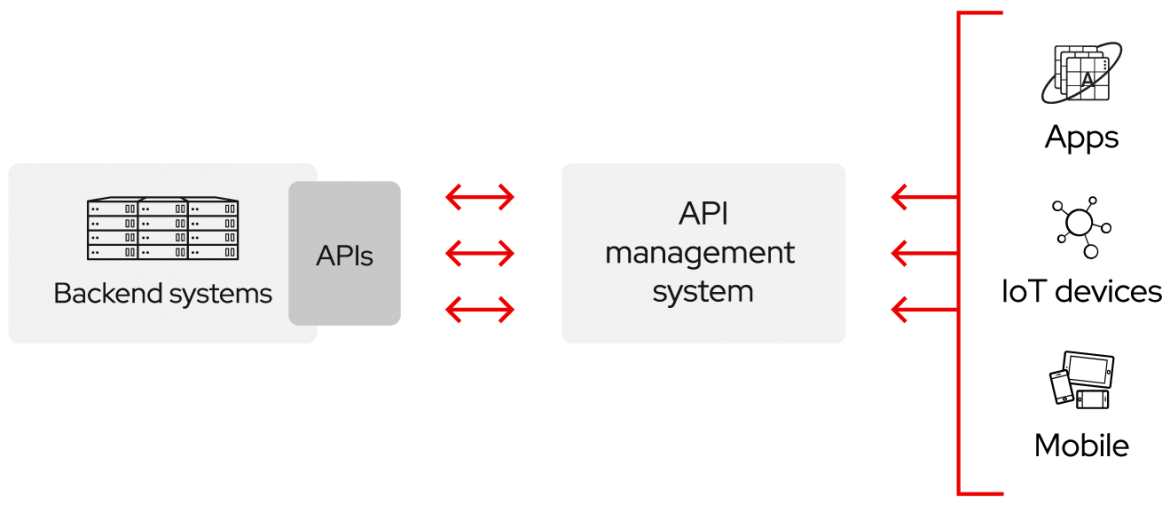
API(Application Programming Interface)는 응용 프로그램에서 사용할 수 있도록, 운영 체제나 프로그래밍 언어가 제공하는 기능을 제어할 수 있게 만든 인터페이스를 뜻한다.
예를 들어 음식 배달 서비스를 만든다고 하면 프로그래밍 언어가 제공하는 기능은 '지도정보'(지도API)라면 응용프로그램은 '지도정보를 통해 만든서비스'라고 볼수 있다. API가 없다면 응용프로그램에서 지도정보를 직접 만들고 정보가 바뀔 때마다 업데이트를 해주어야 한다.
API는 데이터베이스 개념을 중심으로 구축이 되어야 한다. 데이터베이스 스키마에 맞춰 API를 만든다면 시간이 지남에 따라 API를 유지하기 어려울 수 있다. 왜냐하면 API는 다양한 컨텐스트를 지원해야하고 이에 따라 결과는 다양하게 변형될 수 있기 때문이다.
한 리소스에 대해 요청된 명령들은 각기 다른 값을 전달받기를 원한다. 따라서 각기 다른 값을 전달할 API가 만들어져야 한다. 만약 너무 많은 엔드포인트가 필요하거나 컨텐스트를 확인하기 어렵다면 GraphQL과 같은 기술을 통해 API에게 요청하고 정보를 얻어갈 권한을 유저에게 주는 것도 좋은 방법이다.
클라이언트는 필요한데이터의 구조를 지정할 수 있으며 서버는 동일한 구조로 데이터를 반환하는데 GraphQL은 사용자가 어떤 데이터가 필요한 지 명시할 수 있게 해준다. 이러한 구조를 통해 불필요한 데이터를 받게 되거나 필요한 데이터를 받지 못하는 문제를 피할 수 있다.
Database API
파이썬에서 데이터베이스에 접근하기 위한 방법으로 python database API를 사용할 수 있다. python database API는 여러 데이터베이스에 접근하는 표준 API로서 여러 DB 엑세스 모듈에서 이 최소한의 API 인터페이스 표준을 따르고 있다. 표준 API는 크게 데이터베이스를 연결하고 SQL 문을 실행하고 연결을 닫는 등의 기본적인 DB 작업들과 관련된 기능들을 정의하고 있다.
데이터베이스와 작업하는 코드를 살펴보기 전에 먼저 볼 것은 파이썬의 PEP 249이다.
PEPES 249는 파이썬에서 명시하는 DBAPI v2.0에 대한 문서이다.
파이썬에서는 데이터베이스와 연결하는 파이썬 모듈들은 권장되는 가이드라인을 따라 제작되도록 안내한다. 어떤 함수, 메소드, 파라미터, 키워드 등을 어떻게 활용해야하는지 잘 나와있다. 이러한 명시적인 가이드라인 덕분에 파이썬에서 데이터베이스와 연결하는 작업은 다양한 데이터베이스라도 동일한 API를 이용해 데이터를 다룰 수 있다.

SQLite
SQLite 데이터베이스는 기본적으로 파이썬과 함께 설치되는 가벼운 관계형 데이터베이스이다. 여기에서 가볍다라는 의미는 다른 데이터베이스 서버를 사용한 관계형 데이터베이스에 비해 기능이 제한적이라는 것을 의미한다. PostgreSQL과 같이 데이터베이스 서버를 띄우고 작업하지 않고 SQL을 사용할 때 기능적 제한으로 복잡하거나 고급 쿼리 등은 실행하기 어렵다.
또한 파일형 데이터베이스이며 메모리에 상주할 수 있기 때문에 파일을 삭제하거나 프로세스 종료 등으로 인한 데이터 손실도 주의해야 한다. 이러한 단점들이 장점이 되는 상황들도 있다고 한다.
SQLite는 간단하고 빠르게 데이터베이스를 구축하거나 개발 단계에서 단순한 실험 등을 진행하기에는 큰 무리가 없다.
sqlite3으로 데이터베이스와 소통하는 과정을 요약하자면 일단 Connection을 얻고, Cursor 객체를 만들고 execute() 메서드를 호출하여 SQL 명령을 수행하는 것이다.
connect method : 데이터베이스 연결

위의 노란 형광펜으로 표시한 것은 사용자가 만들어야하는 것이다.
데이터베이스에게 바로 명령어를 입력하는 것은 아니고 connection에서 cursor를 통해 데이터베이스에 있는 데이터들을 활용할 수 있다. sqlite3의 connect 메소드를 활용해서 데이터베이스 파일의 위치를 알려주면 된다.
파이썬으로 test.db라는 데이터베이스를 연결해보자.
import sqlite3
conn = sqlite3.connect('test.db')데이터베이스 파일이 없으면 그 이름으로 만들어진 새로운 데이터베이스를 만들어 서 연결하고, 데이터베이스가 있으면 그 데이터베이스에 연결한다. sqlite는 아래와 같이 메모리에서도 실행될 수 있다.
import sqlite3
conn = sqlite3.connect(':memory:')이 때 사용하게 되는 파일명의 확장자는 .db, .sqlite3 등의 옵션들이 있다.
이렇게 연결하게 되면 conn은 데이터베이스와 연결된 하나의 세션을 보관하게 된다. 이제는 다음처럼 해당 세션을 통해 데이터베이스와 소통하기 위한 cursor를 만들어 준다.
cur = conn.cursor()cursor method
cursor.execute
가장 기본적인 데이터베이스 소통방식은 커서의 execute 메소드를 사용하는 것이다. 이 메소드의 인수로 SQL 쿼리문을 바로 넘겨줄 수 있다.
테이블을 만들어보자.
테이블 만들기
cur.execute("""CREATE TABLE test_table(
name VARCHAR (32),
age INT);
""")위의 코드에서는 파이썬 코드 내에서 SQL 쿼리로 test_table을 바로 만들었다. 이처럼 데이터베이스와의 소통의 기본인 커서의 execute 메소드를 활용할 수 있다.
데이터 넣기
이번에는 위의 테이블에 데이터를 추가해보자.
# 방법 1: 하나하나 추가하기
cur.execute("INSERT INTO test_table (name, age) VALUES ('spongebob',12);")또는 아래와 같은 방법도 있다.
# 방법 2: 한 번에 추가하기
name = 'spongebob'
age =12
cur.execute("INSERT INTO test_table(name, age) VALUES (?, ?)", (name,age))위의 코드에서 데이터를 더 추가해보자.
# 방법 1로 데이터 더 추가하기
cur.execute("INSERT INTO test_table (name, age) VALUES ('patrick', 13);")
cur.execute("INSERT INTO test_table (name, age) VALUES ('squidward', 14);")
# 방법 2로 데이터 더 추가하기 (리스트를 넣기)
users = [('patrick', 13), ('squidward',14)]
for user in users:
cur.execute("INSERT INTO test_table (name, age) VALUES (?, ?);", user)이렇게 데이터를 입력하는 것을 한 뒤 데이터베이스 연결 어플리케이션을 통해 확인해보면 아직 데이터가 입력되지 않은 상태이다. 위에는 데이터를 넣는 작업을 한 것이라면 이 작업한 것을 반영해주는 과정을 거쳐야 한다.
con.commit
sqlite3의 commit 함수에 대한 설명은 아래와 같다.
이 method는 현재 트랜잭션을 커밋한다. 이 method를 호출하지 않으면 마지막 commit() 호출 이후에 수행한 작업은 다른 데이터베이스 연결에서 볼 수 없다. 데이터베이스에 기록한 데이터가 보이지 않는다면 이 메소드를 호출하는 것을 잊지 않았나 확인하세요.
commit은 데이터베이스 연결에 대한 connection 객체를 통해 사용가능하다. 우리는 위에서 connection 객체인 conn을 만들었기 때문에 commit을 수행할 수 있다.
conn.commit()추가한 데이터 조회하기
cursor.fetchone 그리고 cursor.fetchall
cur.execute를 실행할 때마다 사용되고 있는 cursor 객체와 관련된 정보를 확인할 수 있다. 리턴되는 문구들은 아래와 같다면 커서 객체에 대한 정보를 알려주는 것이다.
<sqlite3.Cursor object at 0x7fb026aacb20>그렇다면 데이터베이스에서 보내는 결과들은 fetchone, fetchmany, fetchall 등을 활용하면 가져올 수 있다.
cur.fetchall()fetchall을 하게 되면 리스트 형식으로 쿼리를 통해 실행된 결과를 리턴한다.
fetchone은 데이터베이스에서 전달하는 결과에서 첫 번째 결과만을 리턴한다.
