💛 자연어 처리(Natural Language Processing)
자연어(Natural Language)
자연어 혹은 자연 언어는 사람들이 일상적으로 쓰는 언어를 인공적으로 만들어진 언어인 인공어와 구분하여 부르는 개념이다. 인공어에는 세계 공용어로 만들어진 에스페란토나 프로그래밍 언어 등이 있다.
자연어 처리(Natural Language Processing,NLP)는 이러한 자연어를 컴퓨터로 처리하는 기술을 의미한다. 자연어를 분석하고 알맞게 사용하기 위해서는 여러 기술들을 알아야하는데 자연어 처리와 관련된 기술들은 아래의 다이어그램으로 표현할 수 있다.
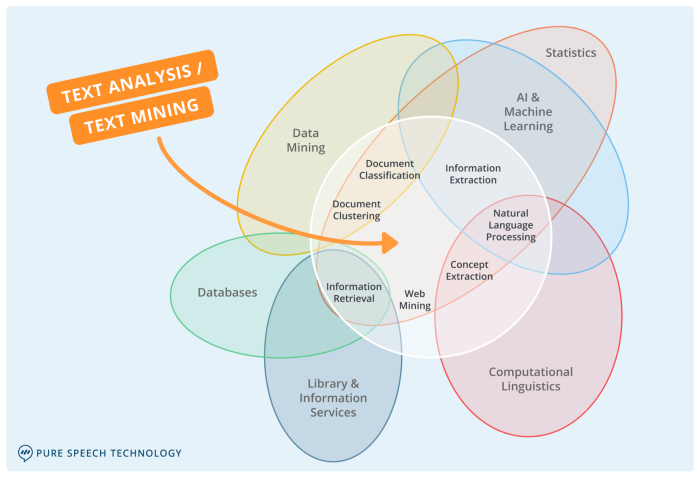
이렇게 다양한 기술을 사용하는만큼 자연어 처리로 할 수 있는 일들은 무수히 많다. 서비스 사레를 가지고 오자면 예전에 유행했던 일반대화 챗봇 심심이, 마인드로직도 있고 심리상담 챗봇인 트로스트, 아토머스부터 구글이나 카카오 번역기, TTS/STT(Text-To-Speech, Speech-To-Text)인 인공지능 스피커, 클로바 노트, kakao-i, 자막생성(보이저엑스-vrew,보이스루 등) 등 매우 다양하다. 이를 자연어 처리의 쓰임을 좀 더 기술적으로 분류해보자면 아래처럼 분류해볼 수 있다.
-
자연어 이해(NLU, Natural Language Understanding)
-- 분류(classification):뉴스 기사 분류, 감정 분석(Positive/Negative)
ex) 소니 XM3000헤드폰 정말 성능 좋은 것 같아! -> Positive/Negative 분류
-- 자연어 추론(NLI, Natural Language Inference)
ex) 전제:"A는 B에게 암살당했다.", 가설:"A는 죽었다." -> True/False
-- 기계 독해(MRC, Machine Reading Comprehension), 질의 응답(QA, Question&Answering)
ex) 비문학 문제 풀기
-- 품사 태깅(POS tagging), 개체명 인식(Named Entity Recognition) 등
ex) POS Tagging, NER -
자연어 생성(NLG, Natural Language Genergation)
-- 텍스트 생성(특정 도메인의 텍스트 생성)
ex) 뉴스 기사 생성하기, 가사 생성하기 -
NLU & NLG
-- 기계 번역(Machine Translation)
-- 요약(Summerization)
ex) 추출 요약(Extractive Summerization): 문서 내에서 해당 문서를 가장 잘 요약하는 부분을 찾아내는 task(NLU의 성격에 가까움)
ex) 생성 요약(Abstractive Summerization): 해당 문서를 요약하는 요약문 생성(NLG의 성격에 가까움)
-- 챗봇(Chatbot)
ex) 특정 테스크를 처리하기 위한 챗봇(Task Oriented Diaglog, TOD)
ex) 정해지지 않는 주제를 다루는 일반 대화 챗봇(Open Domain Dialog, ODD) -
기타
-- TTS(Text to Speech): 텍스트를 음성으로 읽기
-- STT(Speech to Text): 음성을 텍스트로 변환.
-- image captioning: 이미지를 설명하는 문장 생성
실제 자연어처리 task는 이보다 더 다양하다. 내가 해결하고자 하는 문제가 어떤 task인지 찾아보며 필요한 것을 익혀나가는 것이 필요할 것이다.
💛 벡터화(Vectorize)
벡터화는 자연어를 컴퓨터가 이해할 수 있도록 표현해주는 것이다. 컴퓨터는 가공되지 않은 자연어는 받아들일 수 없기 때문이다. 자연어를 어떻게 벡터로 표현할 것인지는 자연어 처리 모델의 성능에 지대한 영향을 미치므로 상당히 중요한 과정인데 이러한 벡터화 방법은 크게 두 가지로 나눠줄 수 있다.
등장 횟수 기반의 단어 표현(Count-Based Representation)
단어가 문서(혹은 문장)에 등장하는 횟수를 기반으로 벡터화하는 방법
- Bag of Words(
CounterVectorizer)- TF-IDF(
TfidfVectorizer)
분포 기반의 단어 표현(Distributed Representation)
타겟 단어 주변에 있는 단어를 기반으로 벡터화하는 방법
- Word2Vec
- GloVe
- fastText
💛 텍스트 전처리(Text Preprocessing)
데이터 전처리가 데이터 분석 업무의 대부분을 차지하듯이 자연어 처리에서도 텍스트를 전처리하는 것은 매우 중요하다. 범용적으로 여러 데이터에 적용할 수 있는 데이터 전처리 방법은 아래와 같다.
- 내장 메소드를 사용한 전처리(
lower,replace등) - 정규 표현식(Regular expression, Regex)
- 불용어(Stop words) 처리
- 통계적 트리밍(Trimming)
- 어간 추출(Stemming) 혹은 표제어 추출(Lemmatization)
이 외에도 전처리 방법은 매우 다양하다.
차원의 저주(Curse of Dimensionality)
차원의 저주는 특성의 개수가 선형적으로 늘어날 때 동일한 설명력을 가지기 위해 필요한 instance의 수는 지속적으로 늘어나게 된다는 점에서 도일한 개수의 instance를 가지는 데이터셋의 차원이 늘어날수록 설명력이 떨어지게 된다는 것을 의미한다.
횟수 기반의 벡터 표현에서는 데이터셋의 feature 즉 차원은 전체 말뭉치에 존재하는단어의 종류가 된다.
따라서 단어의 종류를 줄여주어야 차원의 저주를 어느 정도 해결할 수 있다.
대소문자 통일
Amazonbasics와 AmazonBasics와 amazonbasics는 모두 같은 것을 지칭한다. 하지만 대소문자의 차이로 인해 컴퓨터가 다른 카테고리로 취급할 수 있다. 이렇게 같은 의미를 가진 단어의 대소문자를 통일시켜주어 같은 범주로 엮어주고 차원을 줄여줄 수 있다.
정규표현식(Regex)
정규표현식(Regular Expression, Regex)을 사용하면 구두점이나 특수문자 등 필요없는 문자를 제거하는 것이다. 이러한 불필요한 문자가 말뭉치 내에 있을 경우 토큰화가 제대로 이뤄지지 않기 때문에 불필요하다 판단되면 정규표현식으로 정리해주는 것으로 문자열을 다루기 위한 중요하고도 강력한 도구이지만 복잡하기 때문에 충분한 실습이 필요하다.
python regex 실습
정규표현식 시작하기
# 파이썬 정규표현식 패키지 이름은 re이다.
import re
# 정규식
# []: [] 사이 문자를 매치, ^: not
regex = r"[^a-zA-Z0-9 ]"
##a-z : 소문자
##A-Z : 대문자
##0-9 : 숫자
## ^: 뒤에 나온 것을 제외한 나머지
##를 regex에 할당한 후 .sub 메소드를 통해 공백문자열로 치환해준다.
# 정규식을 적용할 스트링
test_str = ("(Natural Language Processing) is easy!, AI!\n")
# 치환할 문자
subst = ""
result = re.sub(regex, subst, test_str)
result결과값은 'Natural Language Processing is easy AI'로 특수문자와 구두점이 없어진 것을 확인할 수 있다. .sub 메소드 외에도 다양한 메소드들을 사용할 수 있다.
SpaCy를 사용해서 쉽게 처리하기
SpaCy는 문서 구성요소를 다양한 구조에 나누어 저장하지 않고 요소를 색인화(index화)하여 검색 정보를 간단히 저장하는 라이브러리이다. 이러한 작동 빵식으로 실제 배포 단계에서 기존에 많이 사용하던 NLTK라이브러리보다 SpaCy가 더 빠르다. 이러한 장점으로 SpaCy를 사용하는 서비스들이 늘어나는만큼 SpaCy 라이브러리를 사용해서 토큰화 하는 방법에 대해서 정리해보고자 한다.
(모델을 불러올 수 있는 방식은 매우 다양하다.)
# 필요한 모듈 불러오기
import spacy
from spacy.tokenizer import Tokenizer
nlp = spacy.load("en_core_web_sm")
tokenizer = Tokenizer(nlp.vocab)
#토큰화를 위한 파이프라인 구성
tokens =[]
for doc in tokenizer.pipe(df['reviews.txt']):
doc_tokens =[re.sub(r"[^a-z0-9]","",token.text.lower()) for token in doc]
tokens.append(doc_tokens)
df['tokens'] = tokens
df['tokens'].head()word_count를 사용해서 단어의 분포를 나타낼 수 있다.
wc = word_count(df['tokens'])
wc.head()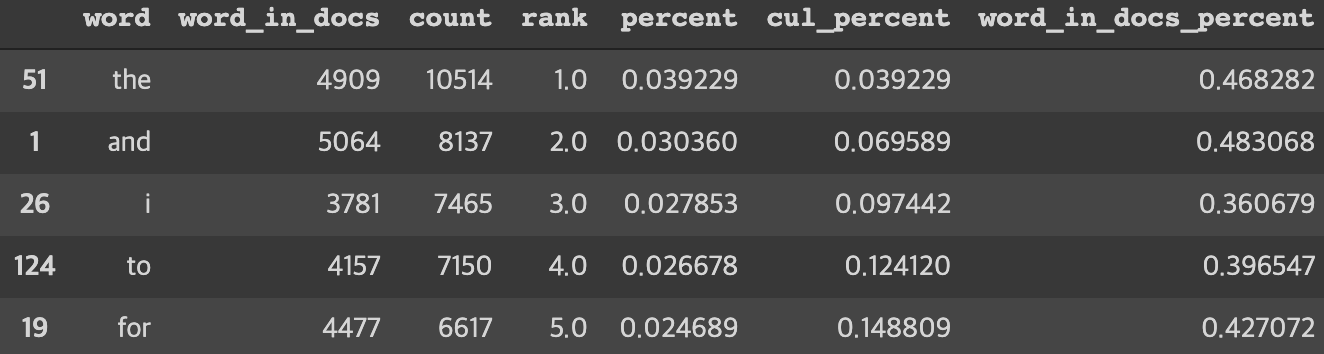
이러한 토큰들을 시각화할 수도 있다.
SpaCy로 토큰화한 문장에 대해 등장비율 상위 20개 단어를 시각화하면 아래처럼 코드를 짜서 나타낼 수 있다.
wc_top20 = wc[wc['rank']<=20]
squarify.plot(sizes=wc_top20['percent'], label=wc_top20['word'], alpha=0.6)
plt.axis('off')
plt.show()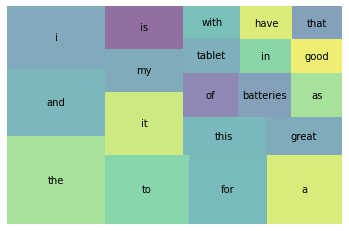
불용어(Stop Words)처리
불용어(Stop Words)를 처리하지 않으면 자주 나오지만 문맥 정보를 잘 전달하지 못하는 단어들이 많이 나온다. 예를들어 위의 리뷰들에서는 리뷰를 통해 사용자의 감정을 알 수 없는 i, and, the, to, for 등의 단어들이 상위를 차지하게 된다. 분석을 더 정확하게 하기 위해 제외하는 단어를 불용어라고 한다.
대부분의 NLP 라이브러리에는 접속사, 관사, 부사, 대명사, 일반동사 등을 포함한 일반적인 불용어를 내장하고 있다.
print(nlp.Defaults.stop_words)를 하면 SpaCy가 기본적으로 제공하는 불용어를 확인할 수 있다.
기본적인 불용어뿐만 아니라 구두점 등을 제외하고자하면 아래처럼 코드를 작성하여 실행시켜줄 수 있다.
tokens =[]
#토큰에서 불용어 제거, 소문자화하여 업데이트
for doc in tokenizer.pipe(df['reviews.txt']):
doc_tokens=[]
# A doc is a sequence of Token(<class 'spacy.tokens.doc.Doc'>)
for token in doc:
#토큰이 불용어와 구두점이 아니면 저장
if (token.is_stop==False)&(token.is_punct ==False):
doc_tokens.append(token.text_lower())
tokens.append(doc_tokens)
df['tokens'] = tokens
df.tokens.head()위의 불용어와 구두점을 처리해주고 난 뒤 상위 20개의 토큰을 시각화하면 아래와 같다.
wc = word_count(df['tokens'])
wc_top20 = wc[wc['rank']<=20]
squarify.plot(sizes=wc_top20['percent'], label=wc_top20['word'], alpha=0.6)
plt.axis('off')
plt.show()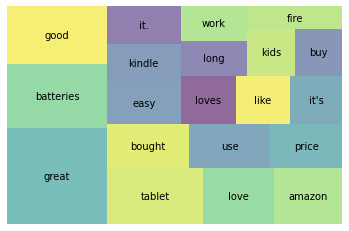
불용어 커스터마이징하기
도메인 지식 등으로 인해 불용어를 사용자가 설정해 줄 수도 있다.
불용어를 추가하거나 기존에 불용어로 취급되는 단어를 제거하여 불용어가 아니게 할 수도 있다.
STOP_WORDS = nlp.Defaults.stop_words.union(['batteries','I','amazon','i','Amazon', 'it', "it's", 'it.', 'the', 'this'])
tokens=[]
for doc in tokenizer.pipe(df['reviews.text']):
doc_tokens=[]
for token in doc:
if token.text.lower() not in STOP_WORDS:
doc_tokens.append(token.text.lower())
tokens.append(doc_tokens)이러한 불용어를 제외하고 난 뒤 상위 20개의 단어를 시각화하면 아래와 같다.
wc_top20 = wc[wc['rank'] <= 20]
squarify.plot(sizes=wc_top20['percent'], label=wc_top20['word'], alpha=0.6)
plt.axis('off')
plt.show()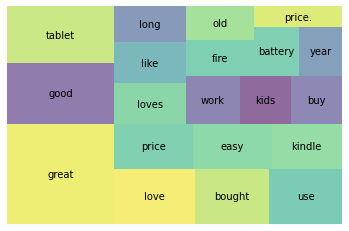
통계적 트리밍(Trimming)
위처럼 불용어를 직접적으로 제거하는 대신 통계적인 방법을 통해 말뭉치 내에서 너무 많거나 너무 적은 토큰을 제거하는 방법도 있다. 예를 들어 아래와 같은 단어 누적분포 그래프가 있다고 하자.
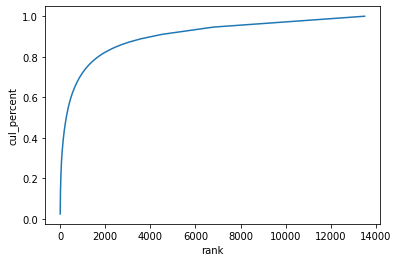
이 그래프에서 알 수 있는 것은 소수의 단어들이 전체 말뭉치(코퍼스)의 80%를 차지한다는 것이다.
그래프 결과에서 나타나는 단어의 중요도는 아래와 같은 두 가지로 해석해볼 수 있다.
- 자주 나타나는 단어들(그래프의 왼쪽, 랭크가 높은 것): 여러 문서에 두루 나타나기 때문에 문서 분류 단계에서 통찰력을 제공하지 않는다.
- 자주 나타나지 않는 단어들(그래프의 오른쪽, 랭크가 낮은 것): 너무 드물게 나타나므로 큰 의미가 없을 확률이 높다.
어간추출(stemming)과 표제어 추출(lemmatization)
토큰화된 단어들을 보면, 조금 더 수정이 필요한 부분이 보이다.
wolves의 원형이 wolf이며 이 둘은 어근이 같은 단어이다.
이렇게 단어들을 어간추출이나 표제어 추출을 하여 정규화(normalization)를 해줄 수 있다.
어간추출(stemming)
어간(stemming): 단어의 의미가 포함된 부분으로 접사 등이 제거된 형태.
어근이나 단어의 원형과 같지 않을 수 있다.
argue, argued, arguing, argues의 어간은 단어들의 뒷부분이 제거된 argu이다.
어간추출은 ing, ed, s 등과 같은 부분을 제거하게 된다.
stemming의 방법에는 porter, snowball, dawson 등의 알고리즘이 있다.
각 알고리즘에 대한 자세한 정보는 아래의 논문에서 살펴볼 수 있다.
A Comparative Study of Stemming Algorithms
# spacy는 stemming을 제공하지 않고 lemmatization만 제공한다.
# nltk를 사용하여 stemming 하기
from nltk.stem import PorterStemmer
ps = PorterStemmer
words = ['wolf', 'wolves']
for word in words:
print(ps.stem(word))
>>> wolf
>>> wolvstemming에서 해본 Porter알고리즘은 단지 단어의 끝부분을 자르는 역할을 한다.
그래서 사전에도 없는 단어가 많이 나오게 된다.
알고리즘이 간단하여 속도가 빠르다는 장점 덕분에 속도가 중요한 검색분야에서 많이 사용되고 있다.
표제어 추출(Lemmatization)
표제어 추출은 어간추출보다 체계적인 방법으로 진행된다.
단어들은 기본 사전형 단어 형태인 Lemma(표제어)로 변환된다.
명사의 복수형은 단수형으로, 동사는 모두 타동사로 변환된다.
이렇게 단어들로부터 표제어를 찾아가는 과ㅑ정은 stemming보다 더 많은 연산이 필요하다.
spacy는 lemmatization을 제공하므로 이를 통해 진행해보면 아래와 같이 구현할 수 있다.
lem = 'The social wolf. Wolves are complex'
nlp = spacy.load('en_core_web_sm')
doc = nlp(lem)
# 문장 요사가 어떤 표제어로 추출되는지 확인해보기
for token in doc:
print(token.text, ' ', token.lemma_)#원래 단어와 표제어
The the
social social
wolf wolf
. .
Wolves wolf
are be
complex complex
. .표제어 추출과정을 함수로 표현하면 아래와 같다.
def get_lemmas(text):
lemmas = []
doc = nlp(text)
for token in doc:
if ((token.is_stop == False) and (token.is_punct == False)) and (token.pos_ !='PRON'):
lemmas.append(token.lemma_)
return lemmas💛 등장 횟수 기반의 단어표현(Count-based Representation)
벡터화
머신러닝 모델에서 텍스트를 분석하기 위해서는 베겉화하는 과정이 필요하다.
벡터화는 텍스트를 컴퓨터가 계산할 수 있도록 수치정보로 변환하는 과정이다.
등장 횟수기반의 단어표현은 단어가 특정 문서(혹은 문장)에 들어있는 횟수를 바탕으로 해당 문서를 벡터화한다.
대표적인 방법으로는 bag-of-words(TF, TF-IDF) 방법이 있다.,
문서-단어 행렬(Document-Term Matrix, DTM)
벡터화된 문서는 문서-단어 행렬의 형태로 나타내어 진다.
문서-단어 행렬이란 각 행에는 문서(Document)가, 각 열에는 단어(term)이 있는 행렬이다.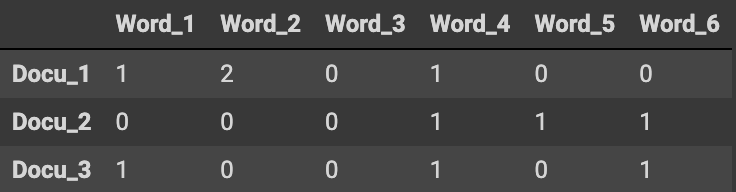
Bag-of-Words(BoW): TF(Term Frequency)
bag-of-words는 가장 단순한 벡터화 방법 중 하나이다.
문서 혹은 문장에서 문법이나 단어의 순서 등을 무시하고 단순히 단어들의 빈도만 고려하여 벡터화한다.
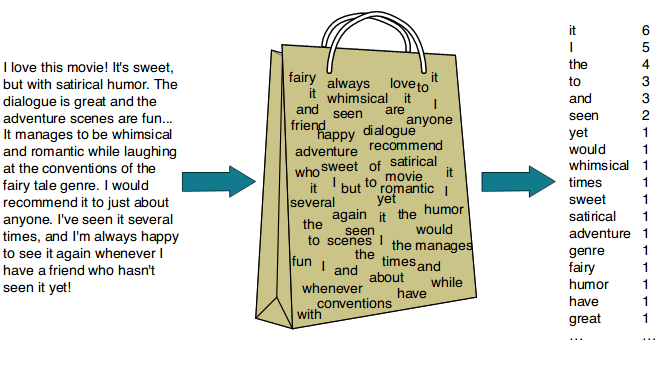
위와 같이 단어를 넣어놓은 가방을 두고 가방안에 무엇이 있는지 꺼내면서
각 문장에 어떤 단어가 몇 번 나오니는 지 세면서 해당 값을 문장의 벡터로 사용한다.
scikit-learn(sklearn)의 CounterVectorizer를 사용하면 bag-of-words 방식의 벡터화를 사용할 수 있다.
CountVectorizer 적용하기
# 모듈에서 사용할 라이브러리와 spacy 모델을 불러오기
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.neighbors import NearestNeighbors
from sklearn.decomposition import PCA
import spacy
nlp = spacy.load("en_core_web_sm")
#CounterVectorizer를 사용한 Bag-of-Words 예제
text = """In information retrieval, tf–idf or TFIDF, short for term frequency–inverse document frequency, is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus.
It is often used as a weighting factor in searches of information retrieval, text mining, and user modeling.
The tf–idf value increases proportionally to the number of times a word appears in the document and is offset by the number of documents in the corpus that contain the word,
which helps to adjust for the fact that some words appear more frequently in general.
tf–idf is one of the most popular term-weighting schemes today.
A survey conducted in 2015 showed that 83% of text-based recommender systems in digital libraries use tf–idf."""
#spacy의 언어모델을 이용하여 token화된 단어들을 확인하기
doc = nlp(text)
print([token.lemma_ for token in doc if (token.is_stop != True) and (token.is_punct != True)])['information', 'retrieval', 'tf', 'idf', 'TFIDF', 'short', 'term', 'frequency', 'inverse', 'document', 'frequency', 'numerical', 'statistic', 'intend', 'reflect', 'important', 'word', 'document', 'collection', 'corpus', '\n', 'weight', 'factor', 'search', 'information', 'retrieval', 'text', 'mining', 'user', 'modeling', '\n', 'tf', 'idf', 'value', 'increase', 'proportionally', 'number', 'time', 'word', 'appear', 'document', 'offset', 'number', 'document', 'corpus', 'contain', 'word', '\n', 'help', 'adjust', 'fact', 'word', 'appear', 'frequently', 'general', '\n', 'tf', 'idf', 'popular', 'term', 'weight', 'scheme', 'today', '\n', 'survey', 'conduct', '2015', 'show', '83', 'text', 'base', 'recommender', 'system', 'digital', 'library', 'use', 'tf', 'idf']
from sklearn.feature_extraction.text import CountVectorizer
#문장으로 이루어진 리스트를 저장하기
sentences_lst = text.split('\n')
#countvectorizer를 변수에 저장하기
vect = CountVectorizer()
#어휘 사전을 생성하기
vect.fit(sentences_lst)CountVectorizer(analyzer='word', binary=False, decode_error='strict', dtype=<class 'numpy.int64'>, encoding='utf-8', input='content', lowercase=True, max_df=1.0, max_features=None, min_df=1, ngram_range=(1, 1), preprocessor=None, stop_words=None, strip_accents=None, token_pattern='(?u)\\b\\w\\w+\\b', tokenizer=None, vocabulary=None)
#text를 DTM(Document-Term matrix)로 변환(transform)
dtm_count = vect.transform(sentences_lst)
dtm_count.shape
>>> (6, 75)
# CountVectorizer 로 제작한 dtm을 분석해 본다.
print(type(dtm_count))
print(dtm_count)
>>> <class 'scipy.sparse.csr.csr_matrix'>
>>> (0, 9) 1
>>> (0, 12) 1
>>> ....vocabulary_ method를 사용하면 vocabulary(모든 토큰)와 맵핑된 인덱스 정보를 확인할 수 있다.
dtm_count의 타입을 보면 CSR(Compressed Sparse Row Matrix)로 나오게 된다.
해당 타입은 행렬(matrix)에서 0을 표현하지 않는 타입이다.
dtm_count를 출력한 결과에서도 (row, column) count 형태로 출력된다.
# .todense() 메소드를 사용하여 Numpy.matrix 타입으로 돌려줄 수 있다.
# DataFrame으로 변환한 후에 결과값을 확인해봅니다.
dtm_count = pd.DataFrame(dtm_count.todense(), columns=vect.get_feature_names())
print(type(dtm_count))
dtm_count
Bag-of-Words(BoW): TF-IDF(Term Frequency-Inverse Document Frequency)
각 문서마다 중요한 단어와 그렇지 못한 단어가 있다.
급식표에서 항상 있는 밥과 김치보다 매일 다르게 나오는 반찬이 그 날의 대표 메뉴로서 더 좋은 답이 될 것이다.
단어를 벡터화할 때에도 마찬가지이다.
다른 문서에 잘 등장하지 않는 단어라면 해당 문서를 대표할 수 있는 단어가 될 수 있다.
이렇게 다른 문서에 등장하지 않는 단어, 즉 특정 문서에만 등장하는 단어에 가중치를 두는 방법이
TF-IDF(Term Frequency - Inverse Document Frequency)이다.
TF-IDF의 수식
각 항이 어떻게 구해졌는지 살펴보면 아래와 같다.
🍎 = 특정 문서 내 단어 w의 수
TF(Term-Frequency)는 특정 문서에서 단어 w가 쓰인 빈도이다.
분석할 문서에서 단어 w가 등장하는 횟수를 구하게 된다.
🍎 =
IDF(Inverse Document Frequency)는 분류대상이 되는 모든 문서의 수를 단어 w가 들어있는 문서의 수로 나누어준 뒤 로그를 취해준 값이다.
실제 계산에서는 단어 w가 0번인 경우를 고려하여 0으로 나누는 것을 방지하기 위해 분모에 1을 더해준 값을 사용한다.
- 분류 대상이 되는 모든 문서의 수 =
- 단어 w가 들어있는 문서의 수 =
위의 식에 따르면 자주 사용하는 단어라도 많은 문서에 나오는 단어들은 IDF가 낮아지기 때문에 TF-IDF로 벡터화했을 때 작은 값을 가지게 된다.
❗️ 지프의 법칙(Zipf's law)에 대해 알아보기
사이킷런(scikit-learn, skleanr)의 TfidfVectorizer를 사용하면 TF-IDF 벡터화도 사용할 수 있다.
실습: TfidfVectorizer를 사용한 TF-IDF 예제
간단한 텍스트에 CounterVectorizer를 적용하여 문서-단어 행렬을 만들어볼 수 있다.
#tf-idf vectorizer, 테이블의 크기를 제한하기 위해 max_features를 제한했다.
tfidf = TfidfVectorizer(stop_words='english', max_features=15)
#fit 후 dtm을 만든다.(문서, 단어마다 tf-idf 값을 계산한다.)
dtm_tfidf = pd.DataFrame(dtm_tfidf.todense(), columns=tfidf.get_feature_names())
dtm_tfidf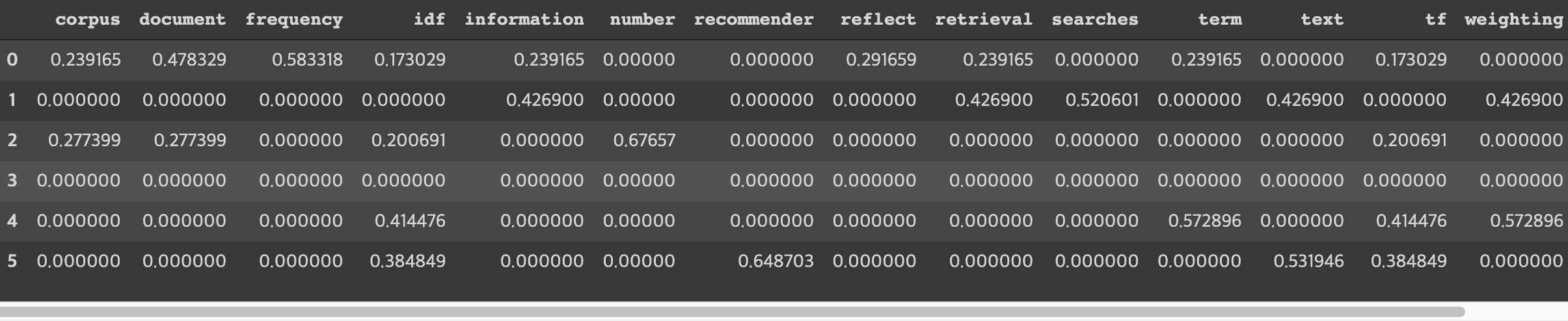
TfidfVectorizer를 사용하여 생성한 문서-단어 행렬(DTM)의 값을 CountVectorizer를 사용하여 생성한 DTM의 값과 비교해볼 수 있다.
vect = CountVectorizer(stop_words='english', max_features=15)
dtm_count_vs_tfidf = vect.fit_transform(sentences_lst)
dtm_count_vs_tfidf = pd.DataFrame(dtm_count_vs_tfidf.todense(), columns=vect.get_feature_names())
dtm_count_vs_tfidf
파라미터 튜닝
❗️ n-gram은 무엇인가? 왜 n-gram이라는 방법론이 등장했을지에 대해 생각해볼 수 있다.
❗️ CountVectorizer와 TfidfVectorizer의 차이는 무엇이며 각각의 장단점은 무엇일지에 대해 생각해볼 수 있다.
유사도를 이용하여 문서를 검색해볼 수 있다.
네이버나 구글과 같은 검색엔진의 원리를 유사도를 통해 이해할 수 있다.
검색엔진은 검색어(query, 쿼리)와 문서에 있는 단어(key, 키)를 매칭(matching)하여 결과를 보여준다.
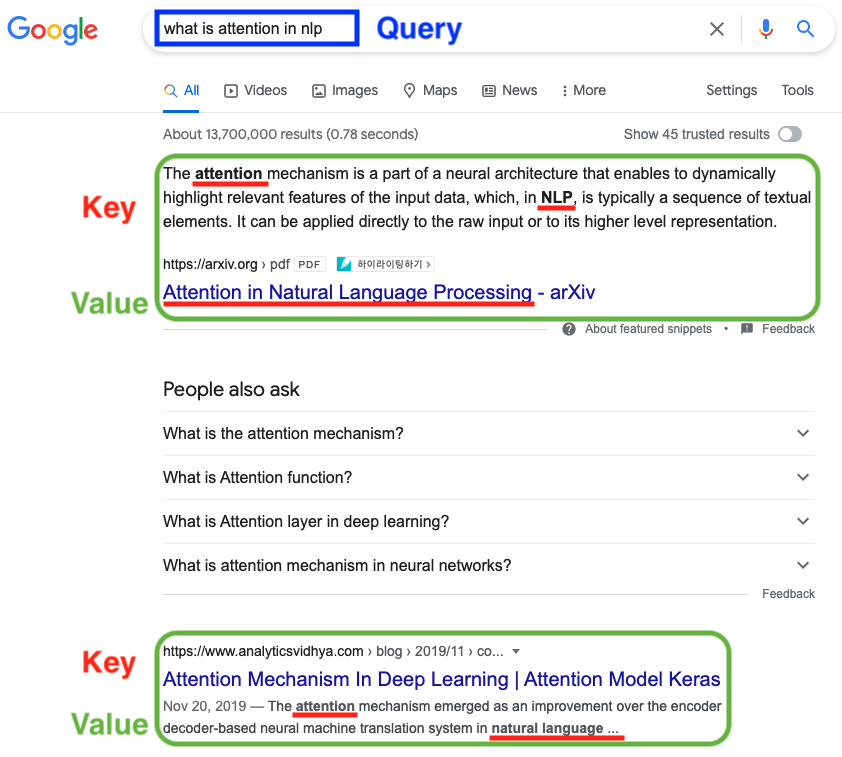
쿼리와 키의 관계를 계산하여 matching하는 데에는 여러 방법들이 있으나 가장 고전적인 방법으로는 유사도 측정 방법이 있다.
코사인 유사도(cosine similarity)
코사인 유사도는 가장 많이 쓰이는 유사도 측정 방법이다.
코사인 유사도를 구하는 공식은 아래와 같다.
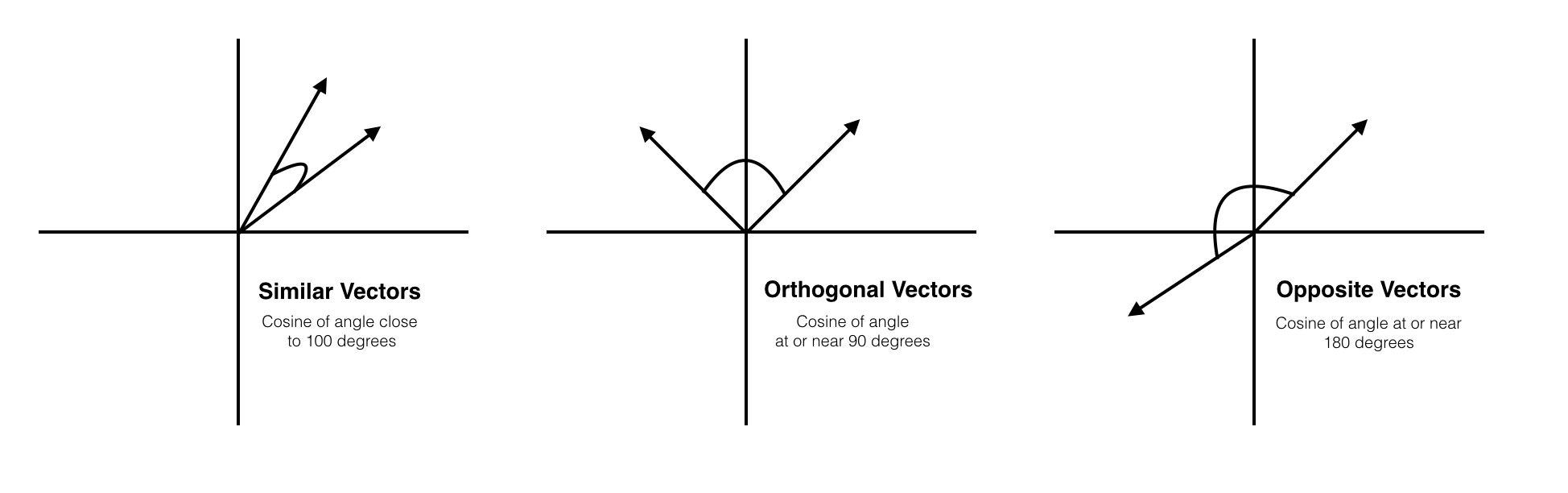
코사인 유사도는 두 벡터가 이루는 각의 코사인 값을 이용하여 구할 수 있는 유사도이다.
두 벡터(문서)가
- 완전히 같을 경우, 1
- 90도의 각을 이루는 경우, 0
- 완전히 반대 방향을 이루는 경우, -1 이다.
실제로 사용되는 유사도 측정방법은 코사인 유사도 말고도 다양하다.
NearestNeighbor(K-NN, K-최근접 이웃)
K-NN은 쿼리와 가장 가까운 상위 K개의 근접한 데이터를 찾아 K개 데이터의 유사성을 기반으로 점을 추정하거나 분류하는 예측 분석에 사용된다.
사이킷런(sklearn)의 NearestNeighbors를 사용하면 K-최근접이웃 알고리즘을 사용할 수 있다.
from sklearn.neighbors import NearestNeighbors
#dtm을 사용하여 NN모델을 학습시킬 수 있다,
#최근접 이웃의 디폴트값은 5이다.
nn = NearestNeighbors(n_neighbors=5, algorithm='kd_tree')
nn.fit(dtm_tfidf)
#dtm_tfidf는 tf-idf를 적용한 데이터의 데이터프레임
nn.kneighbors([dtm_tfidf_amazon.iloc[2]])
## 2번째 인덱스에 해당하는 문서와 가장 가까운 문서(0포함) 5개의 거리(값이 작을수록 유사하다)와 문서의 인덱스를 알 수 있다.(array([[0. , 0.64660432, 0.73047367, 0.76161463, 0.76161463]]), array([[ 2, 7278, 6021, 1528, 4947]]))
두 번째 인덱스 문서의 이웃은 7278, 6021, 1528, 4947이다.
입력 데이터와 유사한 문서가 출력되는지 확인해볼 때 다른 데이터셋에 적용해 볼 때에도 실제로 데이터를 넣어보는 추론(inference)과정을 거치면서 모델이 예상대로 잘 동작하는 지를 관찰하는 습관을 들여보는 것이 좋다.
