통계의 두 가지 방법론
통계의 종류
통계는 데이터를 다루고자하는 목적에 따라 크게 기술 통계치(Descriptive Statistics)와 추리 통계치(Inferential Statistics)로 구분할 수 있다.
❤️ 기술 통계치 (Descriptive Statistics)
수집한 데이터를 요약 및 묘사하고 설명하는 통계 기법들
mean, standard dev, min, 1Q, median, 3Q, max 등의 데이터를 설명하는 값(혹은 통계치)들.
import pandas as pd
df = pd.DataFrame({'a': [1,2,3,4,5], 'b': [2,4,6,8,10]})
#summary statistics구하기
df.describe()집중화 경향 (Central Tendency)
⭐️ 수집한 데이터가 어디쯤에 몰려있는가? ⭐️
예) 평균, 중앙값, 최빈값
분산도 (Variation)
⭐️ 수집한 데이터가 어떻게 퍼져있는가? ⭐️
예) 표준편차, 사분위(1Q, 2Q, 3Q)
기술 통계치의 시각화
boxplot
bagplot
violin plot (boxplot로 데이터의 분포까지 표현한 것)
용어 정리
Mean : 평균
Median : 중앙값 (Median = 2Q)
Mode : 최빈값
Range : 범위(max ~ min)
Var : 분산
SD : 표준편차
Kurtosis: 첨도 (데이터가 어디에 많이 분포되어 있는가?)
Skewness : 외도 (데이터가 끝부분에 많이 분포되어 있는가?)
❤️ 추리 통계치(Inferential Statistics)
수집한 데이터를 기반으로 어떠한 것을 추론하고 예측하는 데에 사용하는 통계 기법.
제한된 데이터, 즉 표본을 사용하기 때문에 명확하게 참/거짓으로 표현하기 어렵다.
추리 통계는 그 결과가 정확하게 실제와 맞다고 할 수는 없지만 우리가 아는 것(수집된 데이터, 표본)을 활용해서 모르는 것(모집단)의 특성을 추론하는 것이기 때문에 중요하다.
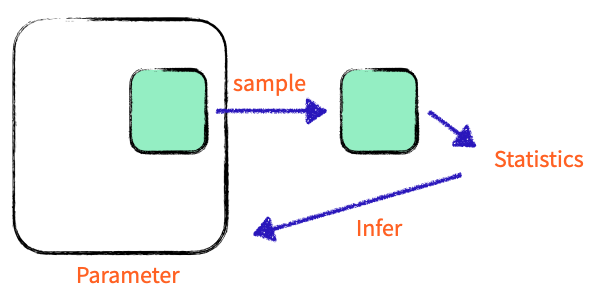
population = 전체 집단 (모집단)
parameter = population에서 구하고 싶은 것
sample = 전체 집단의 일부
statistic = sample을 계산하는 것
estimator = 추정량
standard deviation = 표준편차
standard error = 표준오차
예) t-test, chi-square test 등을 사용한다.
