dialogue datasets
- DREAM:AChallenge Data Set and Models for Dialogue-Based Reading Comprehension (2019, 301회 인용)
- DailyDialog: A Manually Labelled Multi-turn Dialogue Dataset(2017, 1332회 인용)
- CoQA: A Conversational Question Answering Challenge(2018, 1164회 인용)
- MuTual: A Dataset for Multi-Turn Dialogue Reasoning(2020, 132회 인용)
시간 순서대로 정리를 해봅시다.
1. DailyDialog: A Manually Labelled Multi-turn Dialogue Dataset
- 일상 생활에 관한 대화를 포함하는 고품질 다중 턴 대화 데이터셋

-> 이탤릭체로 된 단어들은 화자 B가 다른 화자 A에게 새롭게 제시하는 자신의 아이디어.
-> 보라색 밑줄이 그어진 단어들은 감정을 명확하게 나타냄.
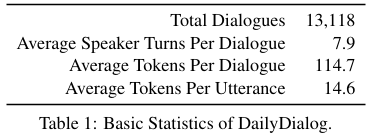
1-1. Basic Features and Statistics
영어 학습자가 일상 생활에서 영어 대화를 연습할 수 있는 다양한 웹사이트에서 원시 데이터를 크롤링함. 그래서 DailyDialog 데이터셋임.
- DailyDialog는 사람이 작성한 것이기 때문에 더 정형화되어 있다.
- DailyDialog의 대화는 종종 특정 주제와 물리적 맥락에 초점이 맞춰져 있다.
- 다른 데이터셋들은 하나의 대화에 1000개 이상의 턴을 포함하며, 3가지 이상 주제에 대해 이야기 하는 경우가 많지만, 이 데이터셋은 좀 더 간결하게 평균적으로 약 8개의 턴을 포함한다.
크롤링 -> 중복 제거 -> 두 명 이상의 참여자가 포함된 대화 필터링 -> 자동 교정 패키지
1-2. Annotation Criteria and Procedure
DailyDialog 는 특정한 소통 방식을 주로 따른다. 이 대화의 목적은 정보를 교환하고 사회적 유대를 강화하는 것이다. 일상적인 소통 행동에 대한 추가 연구를 위해, 데이터셋을 두 가지 목적으로 수동 라벨링하였다.
- 정보교환 소통
각 발화를 네 가지 대화 행위 클래스로 라벨링
- Inform : 화자가 정보를 제공하는 모든 진술과 질문
- Questions : 화자가 무언가를 알고 싶어하는 모든 진술과 질문
- Directives : 요청, 지시, 제안, 제안 수락/거절
- Commissive : 요청이나 제안의 수락/거절 및 제안
- 사회적 유대 강화
인간의 여섯가지 주요하고 보편적인 감정
- Anger, Disgust, Fear, Happiness, Sadness, Surprise.
1-3. 실제 데이터셋

<dialogues_test>
Hey man , you wanna buy some weed ? eou Some what ? eou Weed ! You know ? Pot , Ganja , Mary Jane some chronic ! eou Oh , umm , no thanks . eou I also have blow if you prefer to do a few lines . eou No , I am ok , really . eou Come on man ! I even got dope and acid ! Try some ! eou Do you really have all of these drugs ? Where do you get them from ? eou I got my connections ! Just tell me what you want and I ’ ll even give you one ounce for free . eou Sounds good ! Let ’ s see , I want . eou Yeah ? eou I want you to put your hands behind your head ! You are under arrest ! eou
<dialogue_emotion_test>
0 6 0 0 0 0 0 0 0 0 3 0
0 0 0 0
0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 4 0 0 4 4
0 0 0 0 0 0 0 4
<dialogue_acts_test>
3 2 3 4 3 4 3 2 3 4 2 3
1 2 1 1
1 2 1 2 1 2 1
1 1 1 1 2 2 2 2 1 1 1 3 4 3
2 1 2 1 2 1 2 1
2. CoQA: A Conversational Question Answering Challenge
이 데이터셋은 기계가 질문 응답 스타일의 대화에 참여할 수 있는 능력을 측정하기 위해 만들어졌다. CoQA는 세 가지 주요 목표가 있다.
- 인간 대화에서의 질문 특성

Q5는 who라는 짧은 단어로 이루어져 있으며, 이전에 어떤 말이 오갔는지 모르면 답할 수가 없다. 이런 대화는 인간에게는 효과적이지만, 기계가 해석하기는 어렵다. 대화 기록에 의존하는 질문을 포함하는 대규모 독해 데이터셋이 현재까지 없었고, 이것이 CoQA가 주로 개발된 이유임
-
대화에서 답변의 자연스러움 보장.
많은 QA 데이터셋은 주어진 단락에서 연속된 텍스트로 그대로 답변한다.
하지만 이런 답변은 자연스럽지 않다. CoQA는 답변이 자유형 텍스트가 될 수 있도록 제안하고, 각 답변에 대해 단락에서 텍스트 스팬을 근거로 제공한다. -
다양한 도메인에서 견고하게 작동하는 QA 시스템 구축.
어린이 이야기, 문학, 중고등학교 영어 시험, 뉴스, 위키피디아, Reddit, 과학 등 일곱 가지 다른 도메인에서 데이터셋을 수집
2-1. Task Definition

주어진 질문에 대해서 답변자는 단락의 연속적인 텍스트 스팬인 증거 R1을 기반으로 A1로 답한다.
또한 어떤 질문은 지난 대화 기록을 참조하지 않으면 옳은 답변을 고를 수 없을 수 있다. (질문의 대화적 특성에서 이유를 추론할수 있도록. 단일 질문이 여러 문장에 걸쳐 있는 근거를 필요로 하는 경우를 훈련)
테스트시에는 모델이 스스로 증거를 결정하고 최종 답변을 도출해야 한다.
2-2. Dataset Collection
질문자와 답변자에게 다른 인터페이스를 제공.
- 질문자는 질문을 하는 역할, 답변자의 역할은 질문에 답하고 근거를 강조하는 것.
- 질문자와 답변자 모두 지금까지 진행된 대화를 볼 수 있으나, 근거는 숨겨져 있다.
- 새로운 질문을 작성할 때, 우리는 질문자가 단락에 있는 정확한 단어를 사용하지 않도록 하여 어휘 다양성을 증가시킴.
- 그들이 단락에 이미 존재하는 단어를 입력할 때, 우리는 가능하다면 질문을 바꾸도록 경고.
- 답변할 때는 답변자가 가능한 한 단락에 있는 어휘를 사용하도록 하여 가능한 답변의 수를 제한하고자 함.
-> 답변자에게 먼저 근거(텍스트 스팬)를 강조하도록 요청하며, 이는 자동으로 답변 상자로 복사됨. 복사된 텍스트를 편집하여 자연스러운 답변을 생성하도록 요청함.
-> 78%의 답변이 적어도 한 번의 편집을 포함하며, 이는 단어의 대소문자를 변경하거나 구두점을 추가하는 것과 같은 편집을 포함함.
-> 질문에 여러가지 유효한 답변을 가질 수 있기 때문에 모든 질문에 대해 3개의 추가 답변을 수집한다.
2-3. 실제 데이터 셋
"data": [
{
"source": "mctest",
"id": "3dr23u6we5exclen4th8uq9rb42tel",
"filename": "mc160.test.41",
"story": "Once upon a time, in a barn near a farm house, there lived a little white kitten named Cotton. Cotton lived high up in a nice warm place above the barn where all of the farmer's horses slept..",
"questions": [
{
"input_text": "What color was Cotton?",
"turn_id": 1
},
{
"input_text": "Where did she live?",
"turn_id": 2
}...
],
"answers": [
{
"span_start": 59,
"span_end": 93,
"span_text": "a little white kitten named Cotton",
"input_text": "white",
"turn_id": 1
},
{
"span_start": 18,
"span_end": 80,
"span_text": "in a barn near a farm house, there lived a little white kitten",
"input_text": "in a barn",
"turn_id": 2
},...
],
"additional_answers": {
"0": [
{
"span_start": 68,
"span_end": 93,
"span_text": "white kitten named Cotton",
"input_text": "white",
"turn_id": 1
},
{
"span_start": 17,
"span_end": 93,
"span_text": " in a barn near a farm house, there lived a little white kitten named Cotton",
"input_text": "in a barn",
"turn_id": 2
},
....
],
"1": [
{
"span_start": 68,
"span_end": 74,
"span_text": "white ",
"input_text": "white",
"turn_id": 1
},
{
"span_start": 18,
"span_end": 27,
"span_text": "in a barn",
"input_text": "in a barn",
"turn_id": 2
},
....
]
},
"name": "mc160.test.41"
},

3. The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems
이 데이터셋은
- 다수의 참여자가 아닌 두명(또는 세명) 간의 대화, 가능한 경우 인간 간의 대화
- 많은 수의 데이터셋
- 여러번 턴(3번 이상)이 있는 많은 대화
- 챗봇 시스템이 아닌 특정 작업 도메인
3-1.Ubuntu 채팅 로그
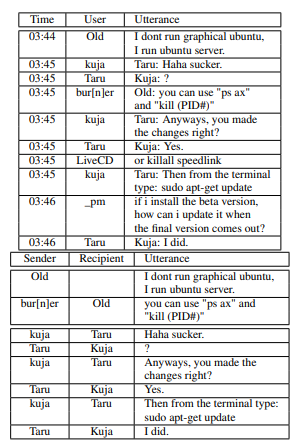
Ubuntu 채팅 로그는 Freenode 인터넷 릴레이 채팅(IRC) 네트워크의 Ubuntu 관련 채팅방에서 수집한 로그를 의미한다. 이 프로토콜은 다수의 참여자 간 실시간 채팅을 허용함. 각 채팅방 또는 채널은 특정 주제를 가지고 있고, 모든 채널 참여자는 주어진 채널에 게시된 모든 메세지를 볼 수 있음.
각 채널은 유사한 패턴을 따름
- 새로운 사용자가 채널에 들어와서 자신의 Ubuntu 문제에 대한 일반적인 질문
- 더 경험이 많은 사용자가 첫 번째 사용자의 유저네임을 먼저 언급하고 해결책 제시 : 이를 name mention이라고 하고, 채널에서 혼동을 막기 위해 수행.
- 시간 상관없이 한 채널에서 1에서 20개의 동시 대화 발생 가능
여러 메시지가 끊임없이 흐르지만, 메시지의 꽤 엄격한 구조를 통해 사용자 간의 대화를 추출할 수 있음.
- 사용자가 보통 답글을 작성하기 전에 의도된 메시지 수신자의 유저네임을 명시하는 방식을 사용함.
3-2. 데이터셋 생성
코퍼스를 생성하기 위해 먼저 채팅방의 다자간 대화에서 두명 간 대화를 추출하는 방법을 고안하는 것이 필요.
1단계 : 모든 메세지를 (시간, 발신자, 수신자, 발화)로 이루어진 4-튜플로 분리하는 것. 이런 4-튜플을 이용하면 발신자와 수신자가 일치하는 모든 튜플을 그룹화하는 것이 간단해진다. 하지만 이 튜플을 생성할 때 시간과 발신자를 나누는 것은 쉽지만, 메세지의 의도된 수신자를 찾는 것은 간단하지 않음
3-2-1. 수신자 식별
대부분 수신자는 발화의 첫 번째 단어이지만, 때로는 끝에 있거나, 초기 질문의 경우는 전혀 포함되지 않는다. 또한 이름이 'the' , 'stop' 처럼 일반적인 영어 단어인 사람도 있어서 많은 오류를 초래한다. 이를 해결하기 위해 현재와 이전 날의 사용자 이름 사전을 작성하고, 각 발화의 첫 번째 단어를 사전 항목화 비교한다. 일치할 때 그 단어가 매우 일반적인 영어 단어가 아니라면, 수신자로 간주한다. 일치하지 않으면 초기 질문으로 간주
3-2-2. 발화 생성
대화 추출 알고리즘은 첫 번째 응답에서 3분 내에 응답한 초기 질문을 찾는 방식으로 작동.
첫번째 응답은 수신자 이름을 포함하고 있는지로 식별.
초기 질문은 첫번째 응답에서 식별된 수신자의 가장 최근 발화로 식별.
첫번째 응답이나 초기 질문으로 간주되지 않는 모든 발화는 폐기. 응답이 생성되지 않는 초기 질문도 폐기.
한 사용자가 80% 이상의 발화를 차지하는 5회 이상 발화 대화도 폐기.
3턴 이상의 발화로 구성된 대화만 고려하여 더 장기적인 의존성을 모델링할 수 있도록.
3-2-3. 대화 추출 시 고려 사항
-
초기 질문의 중복
: 사용자들이 초기 질문을 게시하고, 여러 사람이 서로 다른 답변을 다는 경우가 자주 발생한다. 이때 답한 사용자 간의 대화를 별도의 대화로 처리한다. 그래서 초기 질문이 여러 대화에서 반복되는 부작용이 발생하지만, 적은 수라고 함. -
발화 시간의 고려
: 발화 게시 시간을 기준으로 두 사용자 간의 대화를 구분하지 않음. 심지어 며칠 동안 대화하는 경우에도 이를 단일 대화로 간주.
3-4. 실제 데이터 셋
너무 용량이 커서 열어보지는 못함.
- folder: The folder that a dialogue comes from. Each file contains dialogues from one folder .
- dialogueID: An ID number for a specific dialogue. Dialogue ID’s are reused across folders.
- date: A timestamp of the time this line of dialogue was sent.
- from: The user who sent that line of dialogue.
- to: The user to whom they were replying. On the first turn of a dialogue, this field is blank.
- text: The text of that turn of dialogue, separated by double quotes (“). Line breaks (\n) have been removed.
4. Personalizing Dialogue Agents: I have a dog, do you have pets too?
페르소나를 도입. 페르소나가 없는 모델보다 더 개인적이고, 구체적이며, 일관성있고, 매력적인 응답을 생성하는데 사용될 수 있다.
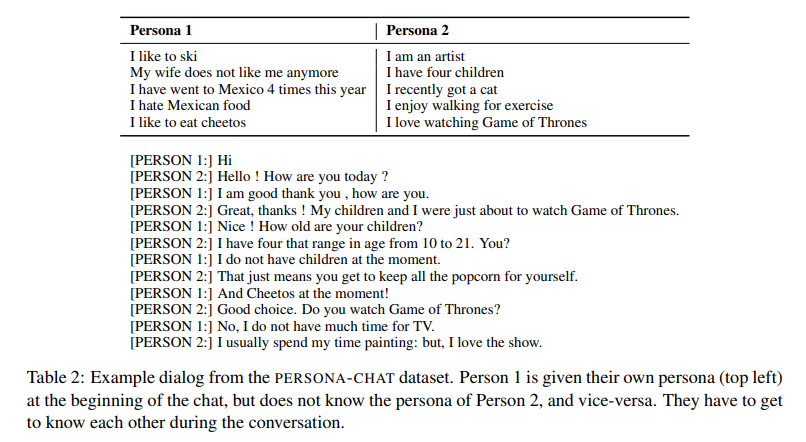
4-1. The PERSONA-CHAT Dataset
Amazon Mechanical Turk을 통해 크라우드소싱된 데이터셋으로, 각 대화 쌍의 화자가 제공된 프로필에 따라 대화를 조건화한다.
1. 페르소나(Personas)
- 1155개의 페르소나 세트를 크라우드소싱.
- 각 페르소나는 최소한 5개의 프로필 문장으로 구성, 검증과 테스트를 위해 각각 100개씩 남겨둠
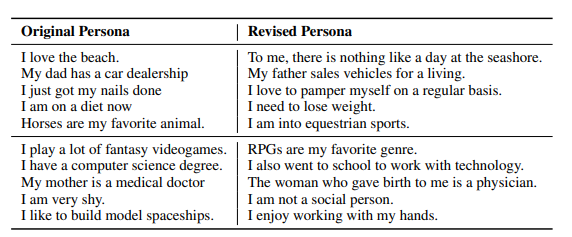
- 수정된 페르소나(Revised Personas)
- 단순한 단어 중복을 이용한 모델링을 방지하기 위해, 동일한 1155개의 페르소나에 대한 추가 수정된 세트를 크라우드소싱.
- 문장을 바꾸거나 일반화하거나 특화하여 태스크를 더 도전적으로 생성
- 페르소나 챗(Persona Chat)
- 두명의 Turker를 짝지어, 각각 풀에서 무작위로 선택된 (원래) 페르소나를 할당하고, 그들에게 대화를 나누도록 요청함
- 이로 인해 10,981개의 대화에서 164,356개의 발화가 생성됨.
- 이중 15,705개의 발화는 검증, 15,119개의 발화는 테스트용입니다.
4-1-1. Personas
크라우드소싱된 작업자들에게 5개의 문장을 사용하여 캐릭터(페르소나) 설명을 작성하도록 요청.
“I am a vegetarian. I like swimming. My father
used to work for Ford. My favorite band is Maroon5. I got a new job last month, which is about
advertising design.”
- 우리의 목표는 대화 중에 화자가 자연스럽게 언급할 수 있는 일반적인 인간의 관심사를 포함하는 자연스럽고 묘사적인 프로필을 만드는 것.
- 페르소나는 실제 프로필이 아님으로 개인정보는 포함 안되어있음
- 각 문장을 최대 15단어 이내로 짧게 작성할 것
4-1-2. Revised Personas
텍스트 페르소나의 문제 중 하나는, 사람들이 요청받지 않아도 프로필 정보를 문자 그대로 반복하거나 상당한 단어 중복을 무의식적으로 반복할 위험이 있다는 것이다.
이를 완하하기 위해, 수집한 원본 페르소나를 새로운 크라우드 작업자들에게 제시하고 문장을 "같은 사람이 가질 수 있는 관련 특성"에 대해 다시 쓰도록 요청.
-> 개정된 문장은 재표현, 일반화 또는 특수화
-> 개정 작업에서 작업자들에게는 원본 단어를 복사하여 문장을 단순히 재표현하지 않도록 지시. 입력 단계에서 불용어가 복사되면 경고를 발령하고 재표현하도록.
4-1-3. Persona Chat
페르소나를 수집한 후, 우리는 페르소나를 조건으로 대화를 수집함.
- 각 대화마다 두 명의 무작위 크라우드 작업자를 짝지어 주고, 주어진 캐릭터 역할을 수행하면서 다른 작업자와 잡담을 나누도록 지시함.
- 그들에게 파트너와 다른, 우리의 풀에서 무작위로 선택된 페르소나를 제공
- 대화는 턴 방식으로 진행되며, 메시지당 최대 15단어로 제한됨.
- 캐릭터 설명을 메시지에 그대로 복사하지 않도록 지시함.
4-2. 실제 데이터셋
csv파일. persona / chat 으로 구분
persona
i like to remodel homes. i like to go hunting. i like to shoot a bow. my favorite holiday is halloween.
chat
hi , how are you doing ? i am getting ready to do some cheetah chasing to stay in shape .
you must be very fast . hunting is one of my favorite hobbies .
i am ! for my hobby i like to do canning or some whittling .
i also remodel homes when i am not out bow hunting .
that is neat . when i was in high school i placed 6th in 100m dash !
that is awesome . do you have a favorite season or time of year ?
i do not . but i do have a favorite meat since that is all i eat exclusively .
what is your favorite meat to eat ?
i would have to say its prime rib . do you have any favorite foods ?
i like chicken or macaroni and cheese .
do you have anything planned for today ? i think i am going to do some canning .
i am going to watch football . what are you canning ?
i think i will can some jam . do you also play footfall for fun ?
if i have time outside of hunting and remodeling homes . which is not much !
