
Bidirectional Encoder Representation Transformers (BERT)
BERT는 NLP에서 광범위하게 사용되는 사전 훈련된 모델로, 주로 텍스트 분류, 문장 유사도, 문장 생성 등 다양한 작업에 적용됩니다. BERT 모델은 입력 텍스트 시퀀스를 인코딩하고 해당 시퀀스를 통해 여러 다운스트림 작업에 사용할 수 있는 특징을 추출합니다.
✅ 본 포스트는 Huggingface의 transformers 라이브러리에 기반합니다.
Transformers 인코더 구조
BERT의 전체적인 구조는 크게 Embedding 파트, Encoder 파트, Classifier 파트로 나뉩니다.
1. Embedding part
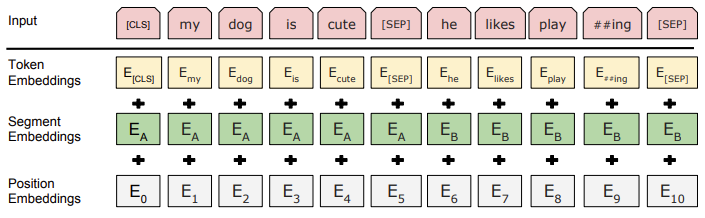
입력 텍스트 시퀀스를 토큰화하고, 각 토큰에 대해 다음 세 가지 임베딩을 더해 하나의 벡터로 만듭니다:
- Token Embeddings (word_embeddings): 단어의 고유한 벡터 표현
- Segment Embeddings (token_type_embeddings): 문장 구분을 위한 임베딩
- Position Embeddings (position_embeddings): 각 토큰의 순서를 나타내는 임베딩
class BertEmbeddings(nn.Module):
"""Construct the embeddings from word, position and token_type embeddings."""
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)토크나이저로 부터 세 가지 ids(input_ids, token_type_ids, position_ids)를 받아 임베딩 후, 세 가지 임베딩을 더해서 최종적인 임베딩 벡터를 반환합니다.
def forward(input_ids, token_type_ids, position_ids, ...) -> torch.Tensor:
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = inputs_embeds + token_type_embeddings
if self.position_embedding_type == "absolute":
position_embeddings = self.position_embeddings(position_ids)
embeddings += position_embeddings
return embeddings2. Encoder part
인코더는 입력된 임베딩 벡터를 여러 계층의 어텐션 메커니즘을 통해 처리하여 더 높은 수준의 표현을 추출합니다. BERT는 Transformer 구조의 인코더만을 사용하며, 이 인코더는 여러 층으로 구성되어 있습니다. 각 층은 어텐션과 피드포워드 네트워크로 구성됩니다.
BertEncoder의 구성
- BertLayer
- BertAttention
- BertSelfAttention
- BertSelfOutput
- BertIntermediate (Feed-forward)
- BertOutput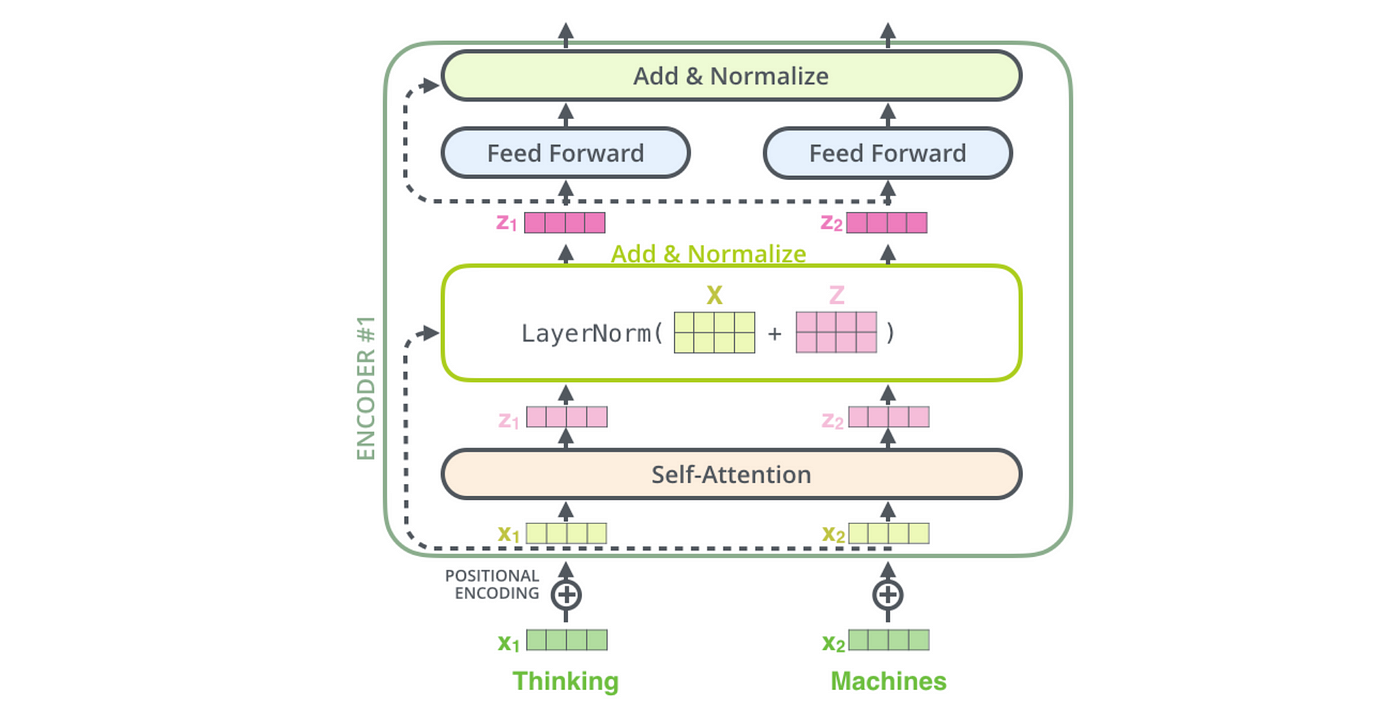
BertLayer
하나의 BERT Layer는 어텐션과 Feed-forward (BertIntermediate) 계층을 포함합니다.
class BertLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.attention = BertAttention(config)
self.add_cross_attention = config.add_cross_attention
if self.add_cross_attention:
self.crossattention = BertAttention(config, position_embedding_type="absolute")
self.intermediate = BertIntermediate(config)
self.output = BertOutput(config)BertAttention
BertAttention은 셀프 어텐션과 출력 레이어로 구성됩니다.
class BertAttention(nn.Module):
def __init__(self, config, position_embedding_type=None):
super().__init__()
self.self = BertSelfAttention(config, position_embedding_type=position_embedding_type)
self.output = BertSelfOutput(config)BertSelfAttention
BertSelfAttention은 Query, Key, Value 벡터를 생성하여 어텐션 점수를 계산합니다.
class BertSelfAttention(nn.Module):
def __init__(self, config, position_embedding_type=None):
super().__init__()
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
attention_probs = nn.functional.softmax(attention_scores, dim=-1)BertSelfOutput
BertSelfOutput은 어텐션 결과를 처리하고, 원래의 입력 값과 결합한 후 정규화합니다.
class BertSelfOutput(nn.Module):
def forward(self, hidden_states, input_tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_statesBertIntermediate
BertIntermediate는 Feed-forward 네트워크를 정의합니다.
class BertIntermediate(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states✅ ACT2FN: Activation functions
BertOutput
BertOutput은 피드포워드 네트워크의 마지막 출력을 담당합니다.
class BertOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states3. Classifier part
BERT의 마지막 부분은 다운스트림 작업에 맞춰 결과를 도출하는 분류기입니다. 예를 들어, 문장 분류 작업에서는 시퀀스의 벡터를 하나의 예측 값으로 변환합니다.
class BertForSequenceClassification(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.config = config
self.bert = BertModel(config)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()Linear 변환
(시퀀스 길이, hidden_size)와 (hidden_size, num_labels)의 행렬 곱(시퀀스 길이, num_labels)을 통해 최종 분류 결과를 생성합니다.
✅ 각 시퀀스에 따른 분류결과로 나타난다.
- num_labels = 1 (ReLU): 단일 값 출력, 예시: 2.6
- num_labels = 1 (Sigmoid): 0과 1 사이의 값 출력
- num_labels = 3 (Sigmoid & Softmax): 예시: (0.2, 0.3, 0.5)
활용 방법
BERT 모델에 추가적인 임베딩을 삽입하여 학습에 활용할 수 있습니다. 예를 들어, 감정 표현 처리나 새로운 형태의 토크나이징 작업을 위한 임베딩을 추가할 수 있습니다.
class BertEmbeddings(nn.Module):
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
# 감정 표현을 처리하는 임베딩 추가
self.emotion_embeddings = nn.Embedding(config.emotion_vocab_size, config.hidden_size)
# 다른 토크나이징 방식 처리를 위한 임베딩 추가
self.word_embeddings_syllable = nn.Embedding(config.syllable_vocab_size, config.hidden_size)그림 출처: 모두의 연구소, by Sarthak Vajpayee in Towards Data Science
