플로우 생성과 최종 연산 사이의 연산들(곱하고, 변형하고, 합치는 등)을 플로우 처리라 한다.
이번엔 플로우 처리를 위해 사용하는 함수들을 정리해보겠다.
map
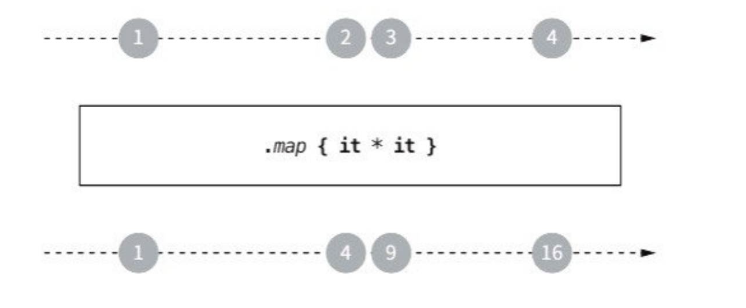
map은 플로우의 각 원소를 변환 함수에 따라 변환시키는 함수다.
suspend fun main() {
flowOf(1, 2, 3) // [1, 2, 3]
.map { it * it } // [1, 4, 9]
.collect { print(it) } // 149
}각 수의 제곱을 계산하는 연산이라면, 생성되는 플로우는 이 수들의 제곱을 값으로 갖게 된다.
fun <T, R> Flow<T>.map(
transform: suspend (value: T) -> R
): Flow<R> = flow { // 여기서 새로운 플로우를 만든다.
collect { value -> // 여기서 리시버를 통해 원소를 모은다.
emit(transform(value))
}
}위 코드는 map의 구현을 간단히 나타낸 코드이다.
위와 같이 값을 변형시키게 된다.
filter
filter는 플로우에서 주어진 조건에 맞는 값들만 가진 플로우를 반환한다.
suspend fun main() {
(1..10).asFlow() // [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
.filter { it <= 5 } // [1, 2, 3, 4, 5]
.filter { isEven(it) } // [2, 4]
.collect { print(it) } // 24
}
fun isEven(num: Int): Boolean = num % 2 == 0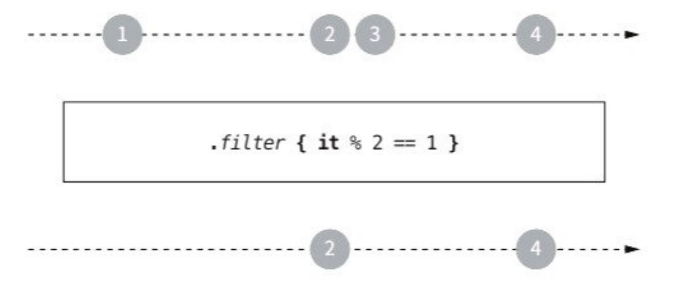
fun <T> Flow<T>.filter(
predicate: suspend (T) -> Boolean
): Flow<T> = flow { // 여기서 새로운 플로우를 만든다.
collect { value -> // 여기서 리시버를 통해 원소를 모은다.
if (predicate(value)) {
emit(value)
}
}
}filter 또한 플로우 빌더를 사용해 쉽게 구현할 수 있다.
조건이 있는 if문만 사용하면 된다.
// 필터를 사용해 유효하지 않은 액션을 버린다.
fun actionsFlow(): Flow<UserAction> =
observeInputEvents()
.filter { isValidAction(it.code) }
.map { toAction(it.code) }filter는 관심 없는 원소를 제거할 때 주로 사용된다.
take와 drop
take
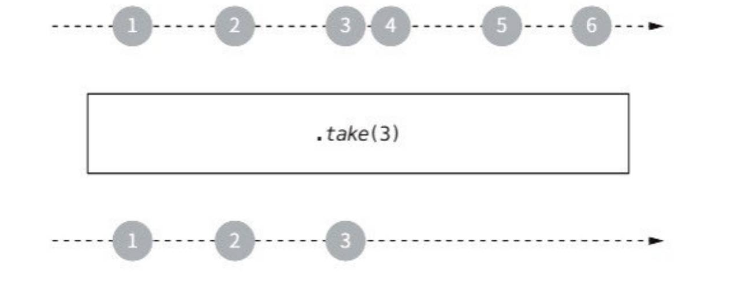
특정 수의 원소만 통과시키기 위해 take를 사용할 수 있다.
suspend fun main() {
('A'..'Z').asFlow()
.take(5) // [A, B, C, D, E]
.collect { print(it) } // ABCDE
}
drop
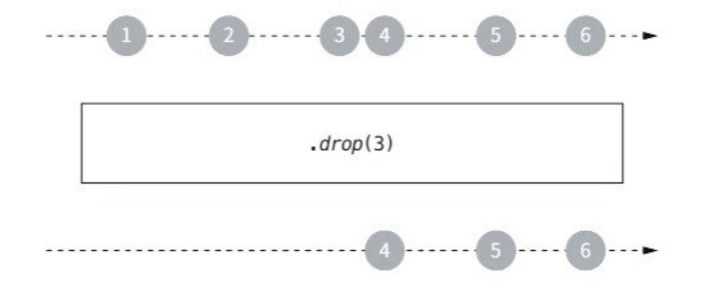
drop을 사용하면 특정 수의 원소를 무시할 수 있다.
suspend fun main() {
('A'..'Z').asFlow()
.drop(20) // [U, V, W, X, Y, Z]
.collect { print(it) } // UVWXYZ
}
merge, zip, combine
merge
merge를 사용해 두 개의 플로우에서 생성된 원소들을 하나로 합칠 수 있다.
suspend fun main() {
val ints: Flow<Int> = flowOf(1, 2, 3)
val doubles: Flow<Double> = flowOf(0.1, 0.2, 0.3)
val together: Flow<Number> = merge(ints, doubles)
print(together.toList())
// [1, 0.1, 0.2, 0.3, 2, 3]
// 또는 [1, 0.1, 0.2, 0.3, 2, 3]
// 또는 [0.1, 1, 2, 3, 0.2, 0.3]
// 또는 다른 가능한 조합 중 하나
}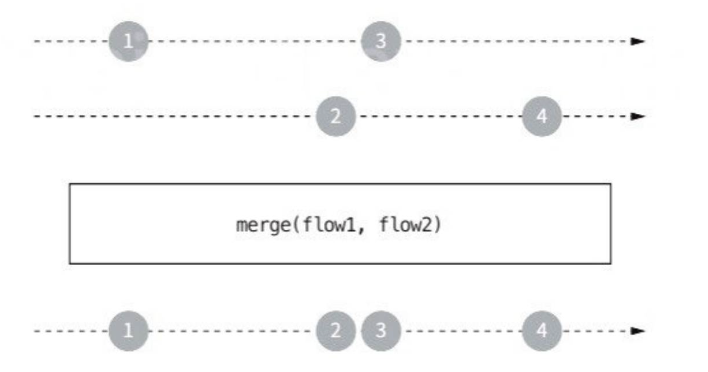
merge를 사용하면 한 플로우의 원소가 다른 플로우를 기다리지 않는다는 것이 중요하다.
suspend fun main() {
val ints: Flow<Int> = flowOf(1, 2, 3)
.onEach { delay(1000) }
val doubles: Flow<Double> = flowOf(0.1, 0.2, 0.3)
val together: Flow<Number> = merge(ints, doubles)
together.collect { println(it) }
}
// 0.1
// 0.2
// 0.3
// (1초 후)
// 1
// (1초 후)
// 2
// (1초 후)
// 3위 예제를 통해 첫 번째 플로우의 원소 생성이 지연된다고해서 두 번째 플로우의 원소 생성이 중단되지 않음을 볼 수 있다.
fun listenForMessages() {
merge(userSentMessages, messagesNotifications)
.onEach { displayMessage(it) }
.launchIn(scope)
}여러 개의 이벤트들을 똑같은 방법으로 처리할 때 merge를 사용한다.
zip
zip은 두 플로우로부터 쌍을 만든다.
각 원소는 한 쌍의 일부가 되므로 쌍이 될 원소를 기다려야 한다. 쌍을 이루지 못하고 남은 원소는 유실되므로 한 플로우에서 지핑(zipping)이 완료되면 생성되는 플로우 또한 완료된다.
suspend fun main() {
val flow1 = flowOf("A", "B", "C")
.onEach { delay(400) }
val flow2 = flowOf(1, 2, 3, 4)
.onEach { delay(1000) }
flow1.zip(flow2) { f1, f2 -> "${f1}_${f2}" }
.collect { println(it) }
}
// (1초 후)
// A_1
// (1초 후)
// B_2
// (1초 후)
// C_3flow2의 4는 짝이 없어 유실되버렸다..
zip처럼 원소들로 쌍을 형성할 때, 첫 번째 쌍을 만들기 위해서는 느린 플로우를 기다려야 한다.
combine
combine을 사용하면 모든 새로운 원소가 전임자를 대체하게 된다. 첫 번째 쌍이 만들어 졌다면 다른 플로우의 이전 원소와 함께 새로운 쌍이 만들어진다.
suspend fun main() {
val flow1 = flowOf("A", "B", "C")
.onEach { delay(400) }
val flow2 = flowOf(1, 2, 3, 4)
.onEach { delay(1000) }
flow1.combine(flow2) { f1, f2 -> "${f1}_${f2}" }
.collect { println(it) }
}
// (1초 후)
// B_1
// (0.2초 후)
// C_1
// (0.8초 후)
// C_2
// (1초 후)
// C_3
// (1초 후)
// C_4zip은 쌍을 필요로 하기 때문에 첫 번째 플로우가 닫히면 함수 또한 끝나게 된다.
combine은 그런 제한이 없기에 두 플로우 모두 닫힐 때까지 원소를 내보낸다.
combine은 두 데이터 소스의 변화를 능동적으로 감지할 때 주로 사용된다. 변화가 발생할 때마다 원소가 내보내지길 원한다면 합쳐질 각 플로우에 초기 값을 더하면 된다.
또한, 뷰가 감지 가능한 원소 두 가지 중 하나라도 변경될 때 반응해야 하는 경우 combine을 주로 사용한다.
userStateFlow
.combine(notificationsFlow) { userState, notifications ->
updateNotificationBadge(userState, notifications)
}
.collect()fold와 scan
fold
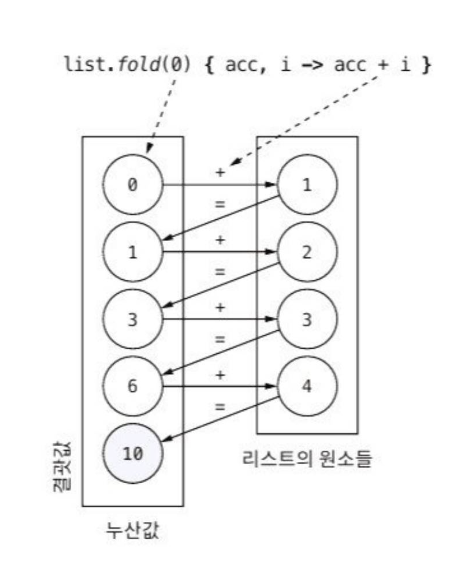
fold는 초기 값부터 시작해서 주어진 원소 각각에 대해 두 개의 값을 하나로 합치는 연산을 작용하여 컬렉션의 모든 값을 하나로 합친다.
fun main() {
val list = listOf(1, 2, 3, 4)
val res = list.fold(0) { acc, i -> acc + i }
println(res) // 10
val res2 = list.fold(1) { acc, i -> acc * i }
println(res2) // 24
}
suspend fun main() {
val list = flowOf(1, 2, 3, 4)
.onEach { delay(1000) }
val res = list.fold(0) { acc, i -> acc + i }
println(res)
}
// (4초 후)
// 10fold는 최종 연산이다. 플로우에서도 사용할 수 있으며, 플로우가 완료될 때까지 중단된다.
scan
fold 대신 scan을 사용할 수도 있다. scan은 누적되는 과정의 모든 값을 생성하는 중간연산이다.
fun main() {
val list = listOf(1, 2, 3, 4)
val res = list.scan(0) { acc, i -> acc + i }
println(res) // [0, 1, 3, 6, 10]
}
scan은 이전 단계에서 값을 받은 즉시 새로운 값을 만들기 때문에 Flow에서 유용하게 사용된다.
suspend fun main() {
flowOf(1, 2, 3, 4)
.onEach { delay(1000) }
.scan(0) { acc, v -> acc + v }
.collect { println(it) }
}
// 0
// (1초 후)
// 1
// (1초 후)
// 3
// (1초 후)
// 6
// (1초 후)
// 10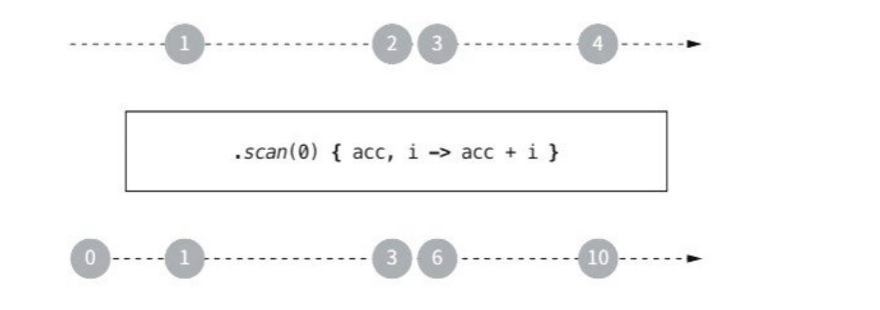
scan은 변경해야 할 사항을 플로우로 가지고 있으며, 변경 내역에 대한 객체가 필요할 때 주로 사용한다.
val userStateFlow: Flow<User> = userChangesFlow
.scan(user) { acc, change -> user.withChange(change) }
val messagesListFlow: Flow<List<Message>> = messagesFlow
.scan(messages) { acc, message -> acc + message }flatMapConcat, flatMapMerge, flatMapLatest
컬렉션에서 flatMap은 map과 비슷하지만 변환 함수가 평탄화된 컬렉션을 반환해야 한다는 점이 다른다.
val allEmployees: List<Employee> = departments
.flatMap { department -> department.employees }
// 맵을 사용하면 리스트의 리스트를 대신 얻게 됩니다.
val listOfListsOfEmployee: List<List<Employee>> = departments
.map { department -> department.employees }예를 들어 부서 목록을 가지고 있고, 각 부서가 사원 목록을 가지고 있다면 flatMap을 사용해 전체 부서의 사원 목록 전부를 만들 수 있다.
플로우에서 flatMap은 변환 함수가 평탄화된 플로우를 반환한다고 생각하는 것이 직관적이다.
문제는 플로우 원소가 나오는 시간이 다르다는 것이다. 두 번째 원소에서 만들어진 플로우가 첫 번째 플로우에서 만들어진 원소를 기다려야 할까? 아니면 동시에 처리해야 할까?
이러한 이유 때문에 플로우에는 flatMap 함수가 없으며, flatMapConcat, flatMapMerge, flatMapLatest와 같은 다양한 함수가 있다.
flatMapConcat
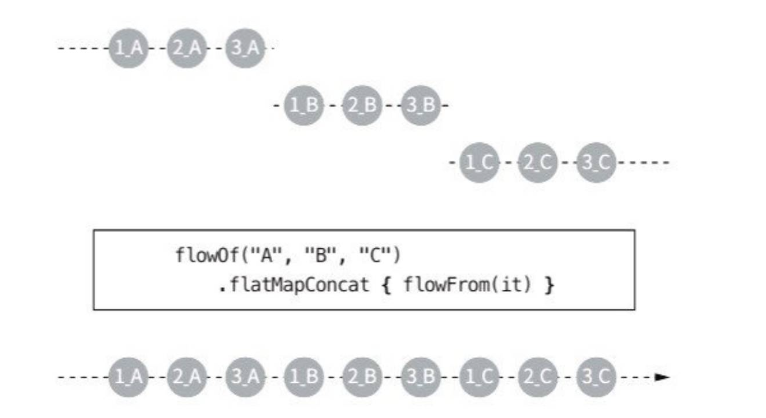
flatMapConcat 함수는 생성된 플로우를 하나씩 처리한다.
그래서 두 번째 플로우는 첫 번째 플로우가 완료되었을 때 처리할 수 있다.
fun flowFrom(elem: String) = flowOf(1, 2, 3)
.onEach { delay(1000) }
.map { "${it}_${elem}" }
suspend fun main() {
flowOf("A", "B", "C")
.flatMapConcat { flowFrom(it) }
.collect { println(it) }
}
// (1초 후)
// 1_A
// (1초 후)
// 2_A
// (1초 후)
// 3_A
// (1초 후)
// 1_B
// (1초 후)
// 2_B
// (1초 후)
// 3_B
// (1초 후)
// 1_C
// (1초 후)
// 2_C
// (1초 후)
// 3_C위 예제는 알파벳 플로우를 만들고, 각 알파벳이 만드는 플로우는 알파벳과 함께 숫자 1, 2, 3을 가지며, 만들어지는 주기는 1초이다.
실행 순서:
- "A" → flowFrom("A") 실행
- 1초마다 "1_A", "2_A", "3_A" 출력
- 다 끝날 때까지 "B"는 시작 안 함
- "B" → flowFrom("B") 실행
- "1_B", "2_B", "3_B" 출력
- 다 끝날 때까지 "C"는 시작 안 함
- "C" → flowFrom("C") 실행
- "1_C", "2_C", "3_C" 출력
flatMapMerge
flatMapMerge는 만들어진 플로우를 동시에 처리한다.
fun flowFrom(elem: String) = flowOf(1, 2, 3)
.onEach { delay(1000) }
.map { "${it}_${elem}" }
suspend fun main() {
flowOf("A", "B", "C")
.flatMapMerge { flowFrom(it) }
.collect { println(it) }
}
// (1초 후)
// 1_A
// 1_B
// 1_C
// (1초 후)
// 2_A
// 2_B
// 2_C
// (1초 후)
// 3_A
// 3_B
// 3_C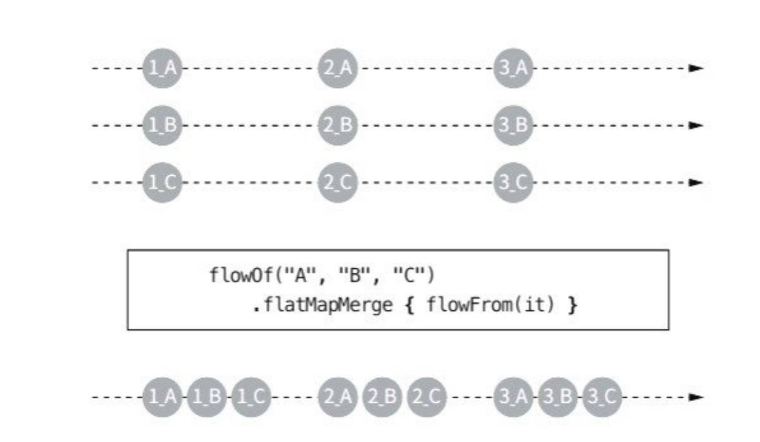
suspend fun main() {
flowOf("A", "B", "C")
.flatMapMerge(concurrency = 2) { flowFrom(it) }
.collect { println(it) }
}
// (1초 후)
// 1_A
// 1_B
// (1초 후)
// 2_A
// 2_B
// (1초 후)
// 3_A
// 3_B
// (1초 후)
// 1_C
// (1초 후)
// 2_C
// (1초 후)
// 3_Cconcurrency 인자를 사용해 동시에 처리할 수 있는 플로우의 수를 설정할 수 있다.
flatMapMerge는 각 플로우의 각 원소에 대한 데이터를 요청할 때 주로 사용된다.
suspend fun getOffers(
categories: List<Category>
): List<Offer> = coroutineScope {
categories
.map { async { api.requestOffers(it) } }
.flatMap { it.await() }
}
// 더 나은 방법이다.
suspend fun getOffers(
categories: List<Category>
): Flow<Offer> = categories
.asFlow()
.flatMapMerge(concurrency = 20) {
suspend { api.requestOffers(it) }.asFlow()
// 또는 flow { emit(api.requestOffers(it)) }
}예를 들어 종류를 목록으로 가지고 있다면 종류별로 요청을 보내야 한다. async 함수를 사용해 이런 처리를 할 수도 있지만, 플로우와 함께 flatMapMerge를 사용하면 두 가지 이점이 있다.
- 동시성 인자를 제어하고 같은 시간에 얼마만큼의 종류를 처리할지 결정할 수 있다.
- Flow를 반환하여 데이터가 생성될 때마다 다음 원소를 보낼 수 있다.
flatMapLatest
flatMapLatest는 새로운 플로우가 나타나면 이전에 처리하던 플로우를 잊어버린다.
새로운 값이 나올 때마다 이전 플로우 처리는 사라져버린다.
fun flowFrom(elem: String) = flowOf(1, 2, 3)
.onEach { delay(1000) }
.map { "${it}_${elem}" }
suspend fun main() {
flowOf("A", "B", "C")
.flatMapLatest { flowFrom(it) }
.collect { println(it) }
}
// (1초 후)
// 1_C
// (1초 후)
// 2_C
// (1초 후)
// 3_C
재시도(retry)
예외는 플로우를 따라 흐르면서 각 단계를 하나씩 종료한다.
종료된 단계는 비활성화되기에 예외가 발생한 뒤 메시지를 보내는 건 불가능하지만, 각 단계가 이전 단계에 대한 참조를 가지고 있어 플로우를 다시 시작하기 위해 참조를 사용할 수 있다.
이 원리를 기반으로 코틀린은 retry 함수를 제공한다.
retry(retries: Long, predicate: suspend (cause: Throwable) -> Boolean)
- predicate 블록이 실행되고, 거기서 Boolean 값을 반환해야 한다.
- true → "예외가 발생했지만 다시 시도하겠다" → Flow 재시작
- false → "재시도하지 않겠다" → 예외를 밖으로 던진다.
suspend fun main() {
flow {
emit(1)
emit(2)
error("E")
emit(3)
}.retry(3) {
print(it.message)
true
}.collect { print(it) }
// 12E12E12E12 (예외가 발생)
}위 코드는 최대 3번까지 예외가 발생하면 재시도 가능하고, 항상 true를 반환하니 예외가 나와도 3번 모두 재시도를 진행한다.
최종 연산
최종 연산은 플로우 처리를 끝내는 연산이다.
지금까지는 collect만 사용했지만 아래와 같은 최종연산들이 있다.
- 플로우에서 원소의 수를 세는
count,first - 플로우가 내보낸 첫 번째 원소를 얻는
firstOrNull,fold - 원소들을 누적 계산하여 하나의 객체를 만드는
reduce
최종 연산은 중단 가능하며 플로우가 완료되었을 때 값을 반환한다.
suspend fun main() {
val flow = flowOf(1, 2, 3, 4) // [1, 2, 3, 4]
.map { it * it } // [1, 4, 9, 16]
println(flow.first()) // 1
println(flow.count()) // 4
println(flow.reduce { acc, value -> acc * value }) // 576
println(flow.fold(0) { acc, value -> acc + value }) // 30
}플로우에서 제공하는 최종 연산 외, 다른 연산이 필요하다면 직접 구현할 수 있다.
suspend fun Flow<Int>.sum(): Int {
var sum = 0
collect { value ->
sum += value
}
return sum
}위 예제처럼 collect 메서드만 사용해서 또 다른 최종연산을 구현할 수도 있다.
