
원티드 온보딩 프로그램 2주차가 끝났다. 이번 주에 해결한 2개의 과제 중에 내가 구현하고 싶었지만, 팀원에게 기회를 양보한 기능이 있었다. 유튜브 등 많은 웹 페이지에서 무한 스크롤 기능을 레이지 로딩과 함께 구현하고 있는데 이 부분을 구현해보면 재밌겠다 싶어서 주말을 이용해서 기능을 구현해 보았다.
Infinity Scroll(무한 스크롤)
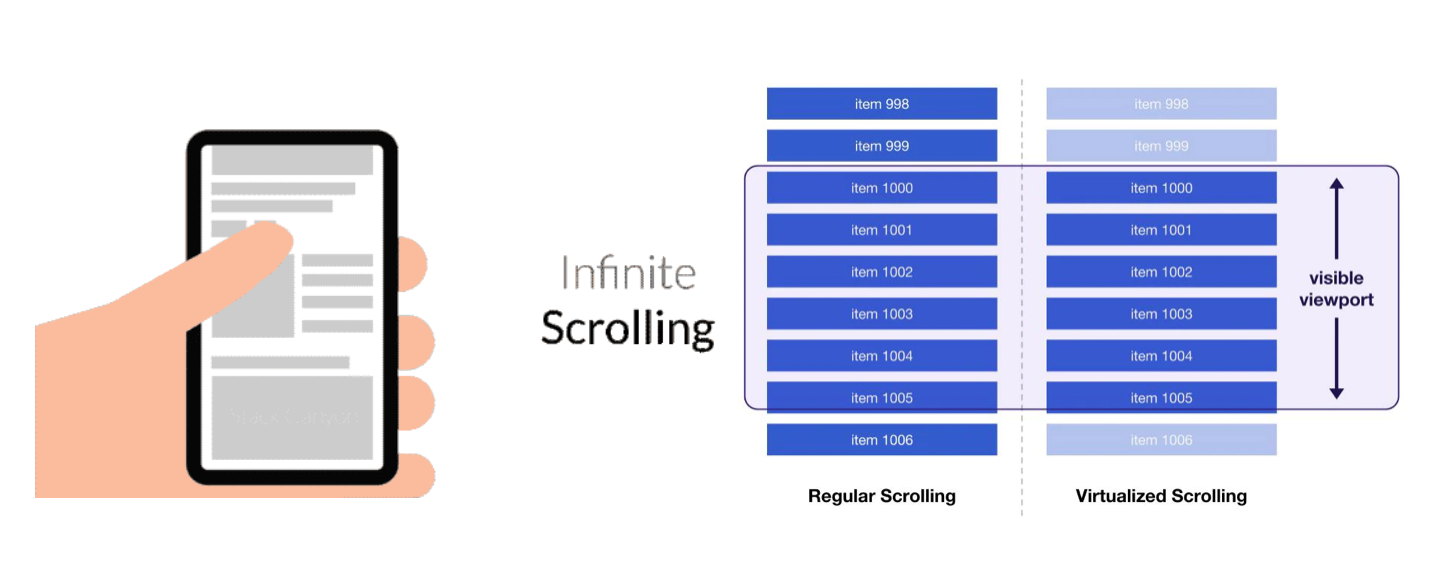
무한 스크롤은 말 그대로 무한히 스크롤링을 기능하는 기능을 말한다. 페이지를 클릭하면 다음 페이지 주소로 이동하는 pagenation과 달리 페이지 하단에 도달하면 새로운 컨텐츠가 한 화면에 추가로 로드된다.
이 무한스크롤링을 구현하기 위해 3가지 값을 비교하게 된다.
(1) scrollHeight : 화면에 보이지 않는 총 높이까지 포함된 페이지의 높이
(2) scrollTop : 이미 스크롤되어서 보이지 않는 구간의 높이
(3) clientHeight : 사용자에게 보여지는 페이지의 높이
위 값 중에서 (2)와 (3)을 합친 값이 (1) 보다 크거나 같다면,
스크롤이 페이지의 끝에 닿았다고 판단해 페이지에 새로운 데이터를 그려주는 원리로 구현한다.
이벤트를 감지하는 방식은 2가지로 나뉘는데,
- scroll 이벤트를 감지하는 event listener를 등록해, 스크롤 끝에 닿았을 때 추가 데이터를 가져오는 방식
- Intersection Observer API를 사용해 타깃으로 삼은 엘리먼트를 관찰해, 특정조건이 되면 데이터를 가져오는 방식
이렇게 두 가지로 살펴볼 수 있다.
🖱 scroll 이벤트를 감지해 구현한 인피니티 스크롤 예제
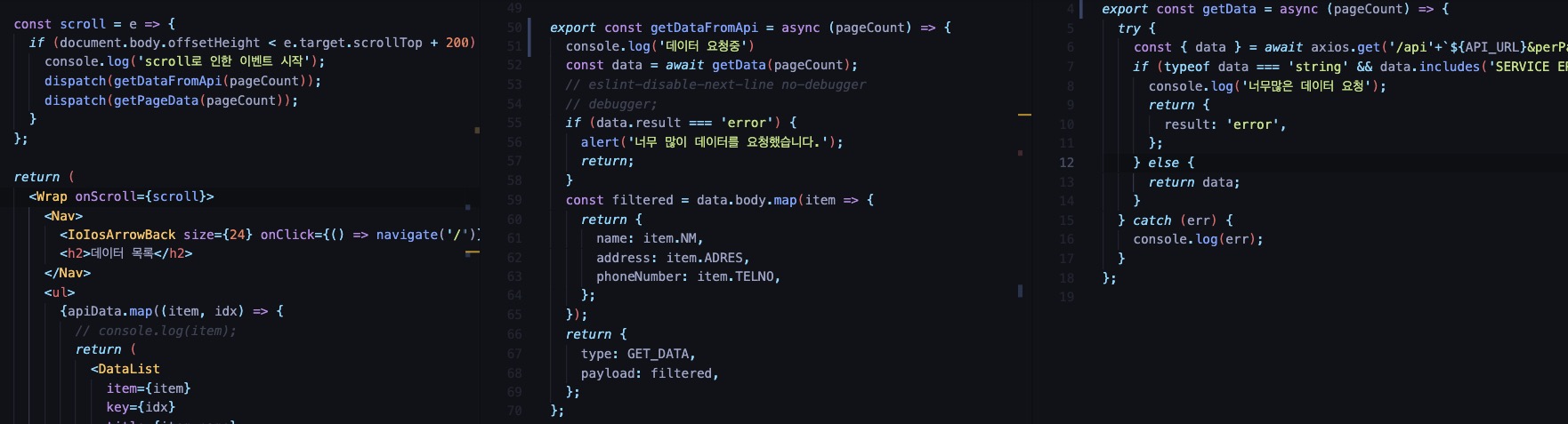
팀원들이 구현한 방식은 스크롤 이벤트가 발생할때 document.body.offsetTop 값과 e.target.scrollTop값에 엘리먼트의 높이를 더해진 값을 비교해 후자가 더 컸을 때 스크롤 이벤트를 발생시키는 방식으로 구현을 했다.
const scroll = (e) => {
if (document.body.offsetHeight < e.target.scrollTop + 700) {
console.log('scroll로 인한 이벤트 시작');
console.log('offsetHeight', document.body.offsetHeight);
console.log('scrollTop', e.target.scrollTop);
dispatch(getDataFromApi(pageCount)); // api로 데이터를 요청하는 리듀서 함수를 실행
dispatch(getPageData(pageCount)); // api의 옵션 * 1페이지 당 10개씩 데이터를 로드
}
};만일 이대로, 스크롤 이벤트를 동작시키게 된다면, 스크롤 이벤트가 발생할 때마다 API로 get요청을 보내게 될 것이다.
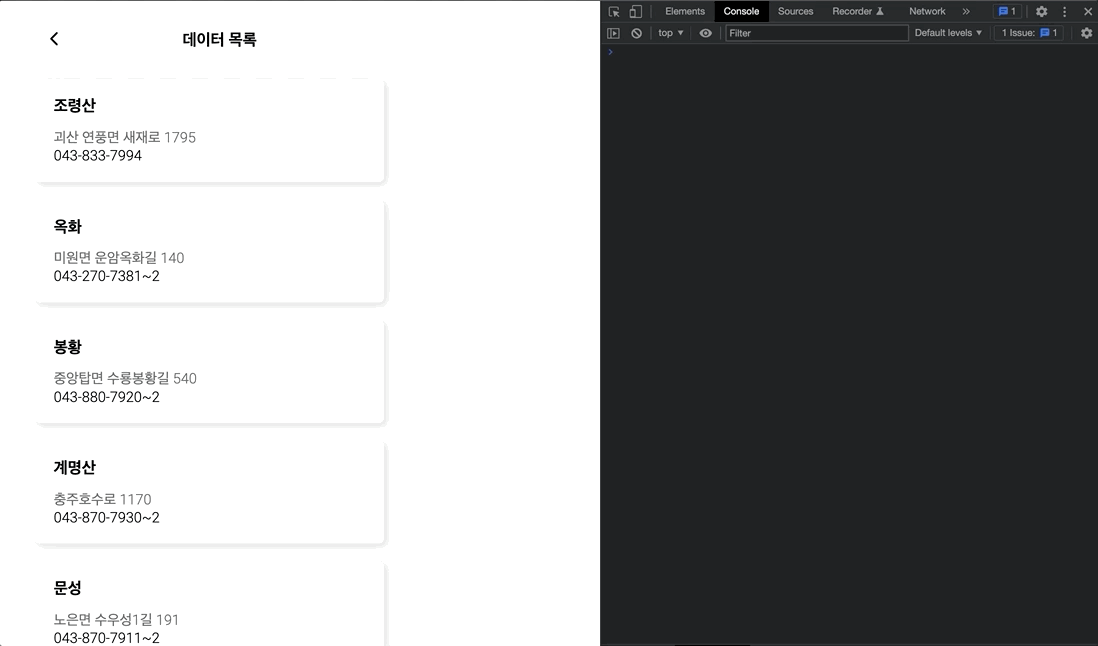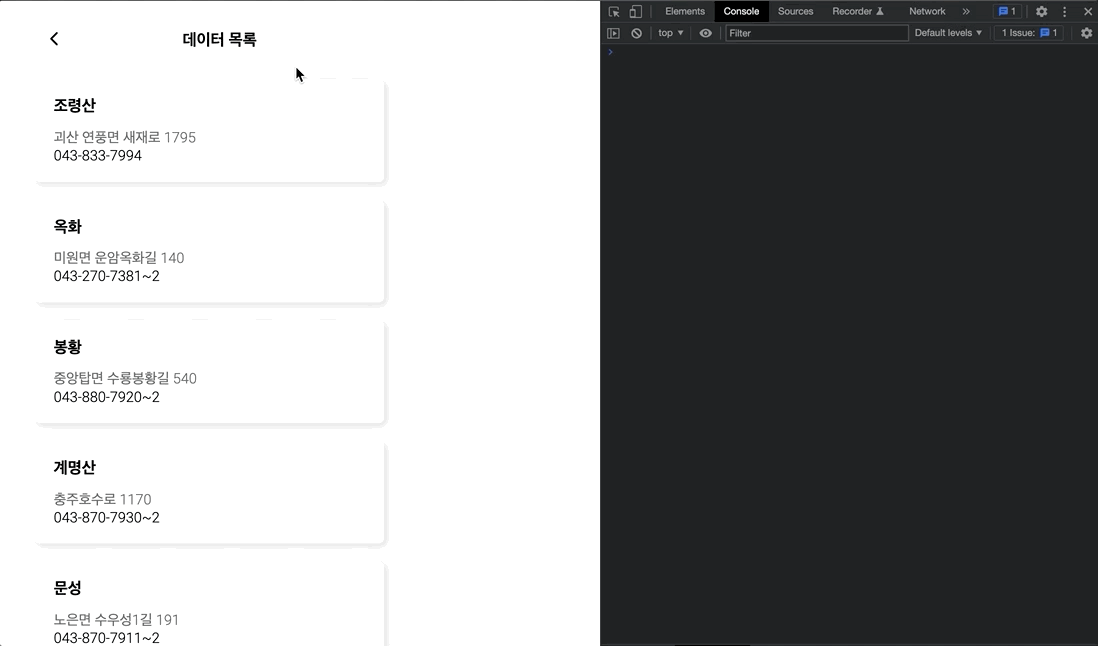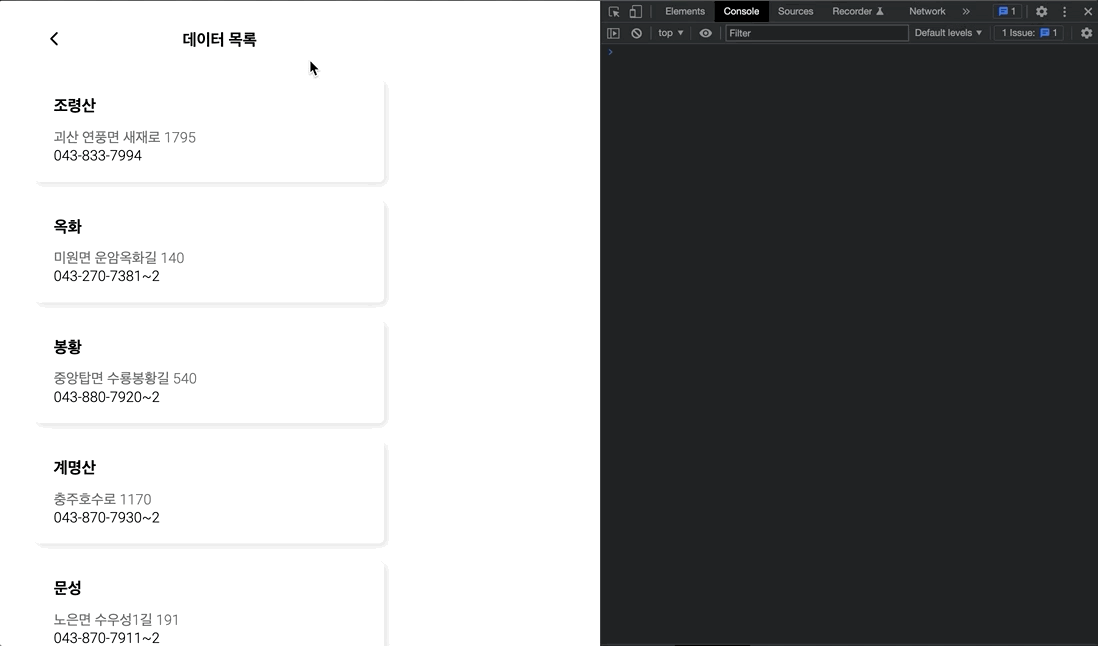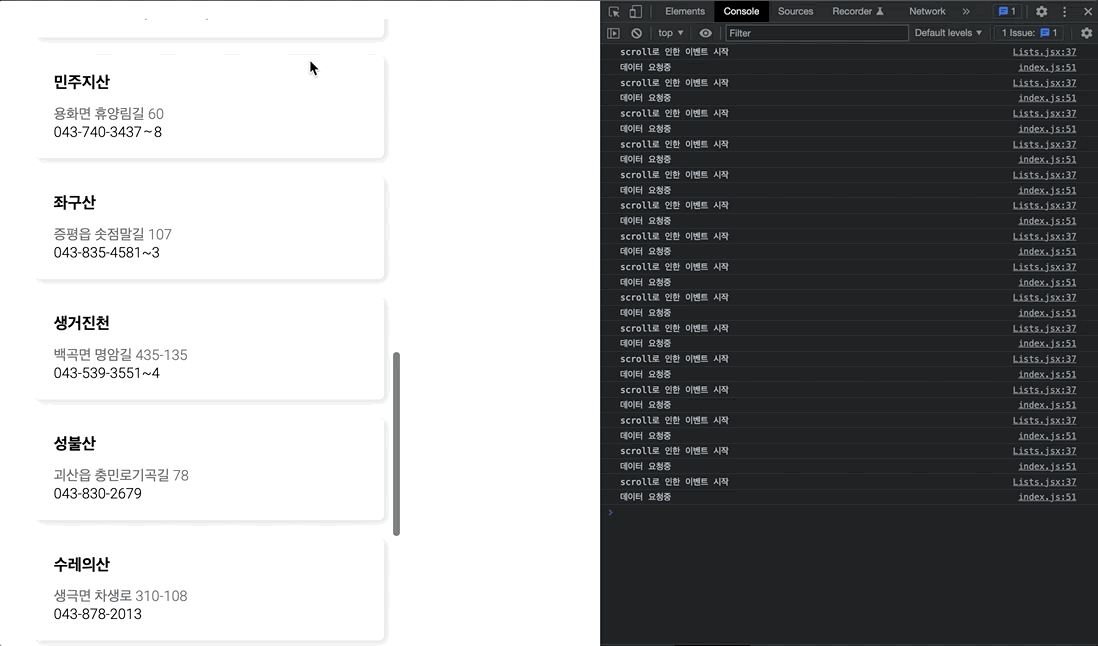
2초도 안되는 짧은 시간동안, 엄청나게 많은 요청이 발생하는 것을 볼 수 있다.
리소스 낭비를 막고자, 조원들이 최적화 방법은 쓰로틀링 함수를 사용하는 것이었다.
const throttle = (callback, delay) => {
let timer = null;
return arg => {
if (timer === null) {
timer = setTimeout(() => {
callback(arg);
timer = null;
}, delay);
}
};
};언더스코어 라이브러리를 사용하지 않고, JS로 구현한 코드는 위와 같은데, throttle 함수를 사용해서 스크롤 이벤트가 트리거되는 ‘정도’를 조절할 것이다.
<Wrap onScroll={throttle(scroll , 400)}>쓰로틀링을 구현하고자 scroll 함수와 딜레이를 매개 변수로 전달해, 딜레이(300ms)동안 scroll 이벤트를 1번만 호출되도록 딜레이를 주었다.
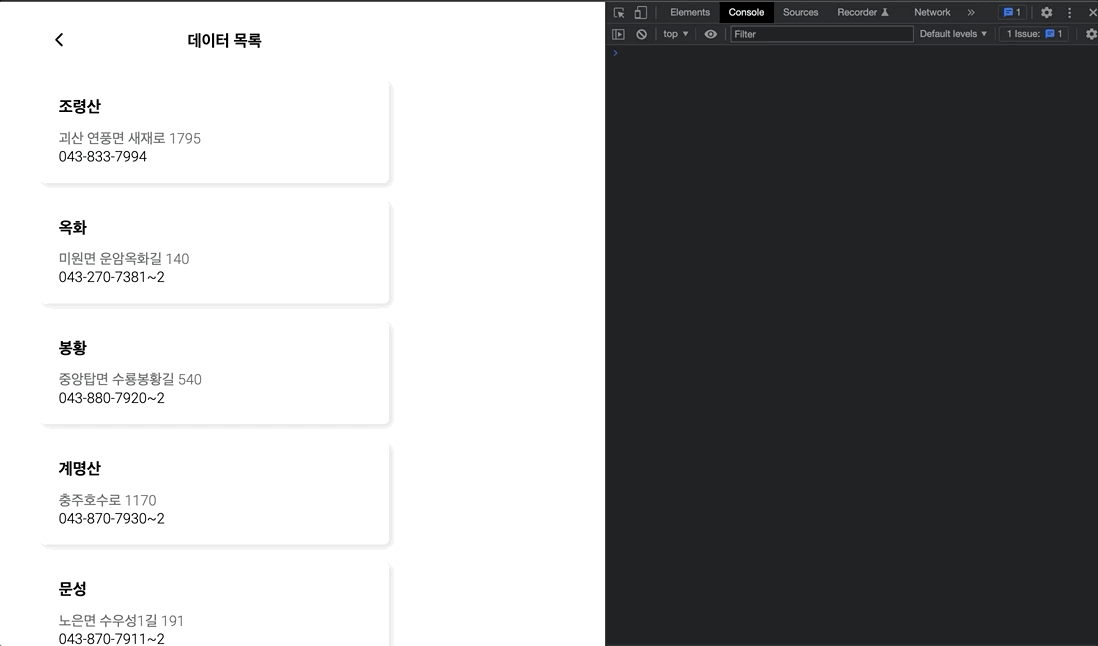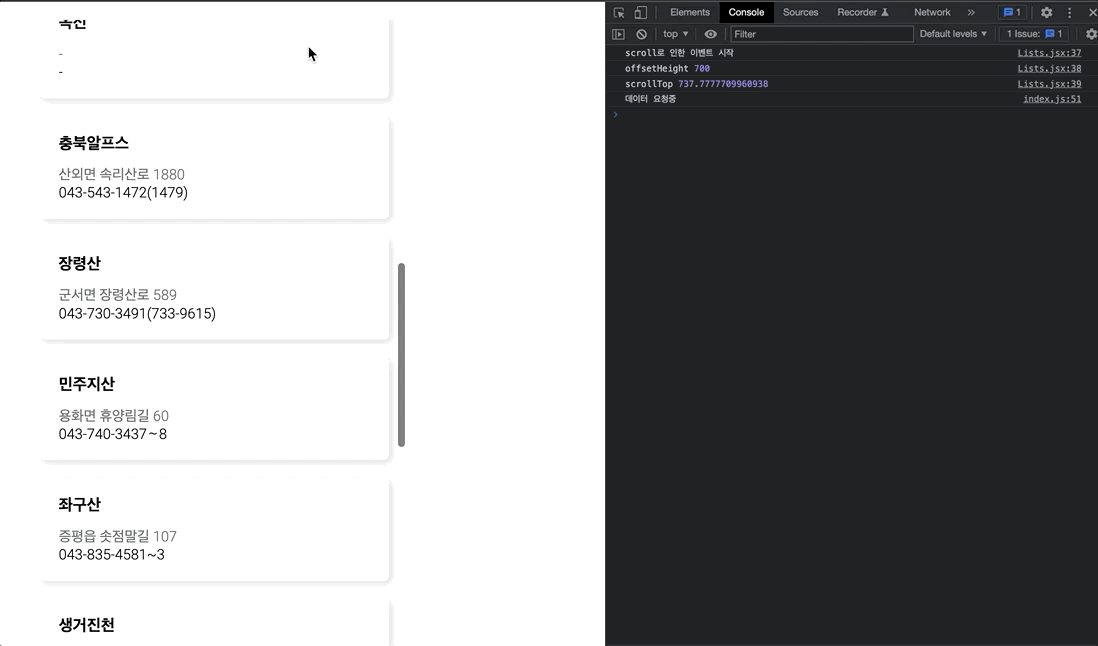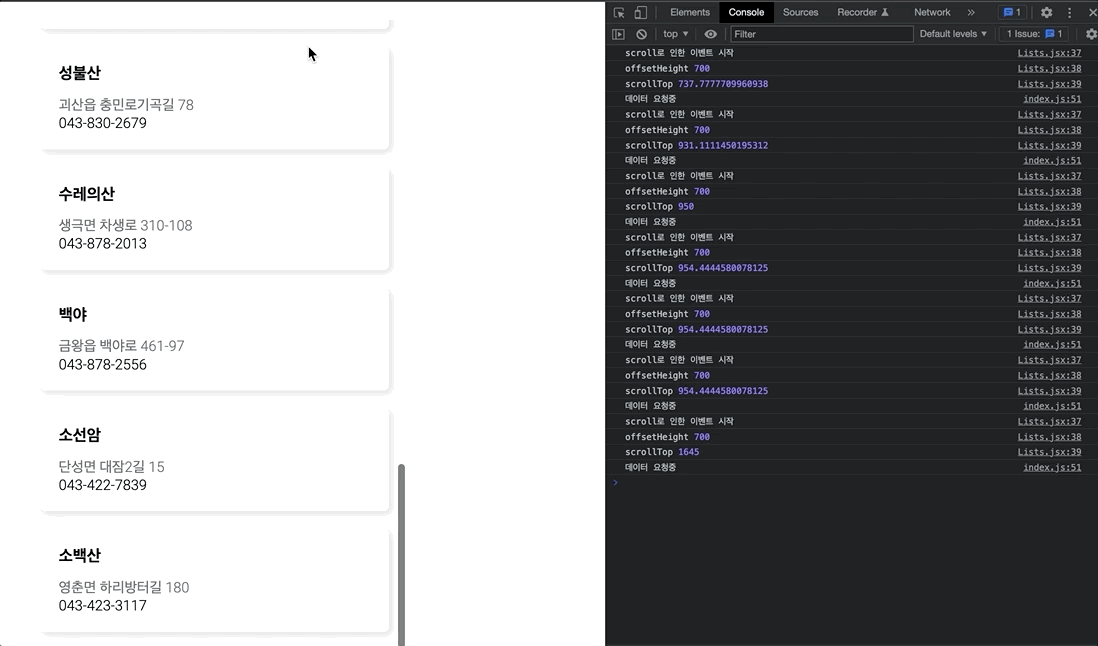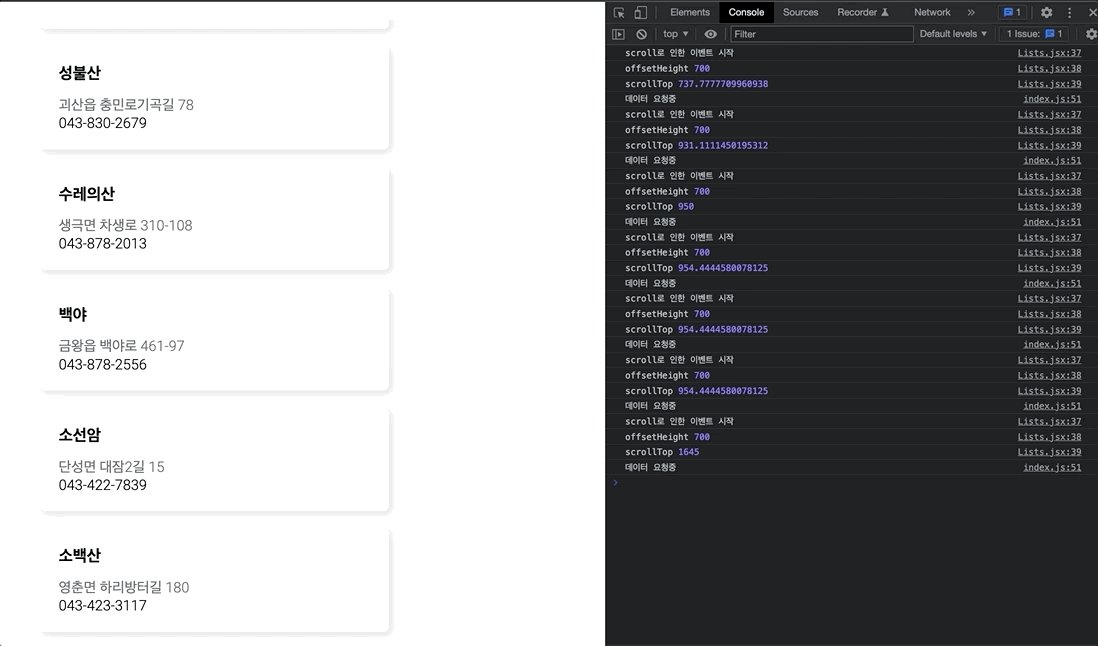
그 결과, 아까와는 다르게 훨씬 부드러운(?) 결과를 얻을 수 있다. 하지만, 기대와는 조금 다르게 동작하고 있는데 그 이유는 이래와 같다.
❗️ 대부분의 경우 이 정도로 최적화가 가능하지만, 때때로는 기대한대로 동작하지 않을 수도 있다. throttle은 debounce를 기반으로 동작하고, 두 함수 모두 작동 원리는
setTimeout를 사용하고 있다. 이setTimeout이 기대한대로 동작하지 않을 수 있기 때문이다.
싱글스레드로 동작하는 JavaScript는 setTimeoutAPI 비동기 작업들을 Task Queue에 넣어둔 후 순차적으로 처리한다. 선입선출의 원리로 작동하는 Task Queue에 저장된 비동기 작업을 처리하려는 시점에서 Call Stack은 비어져 있을 수 있다. 이 시점이 setTimeout에 할당해준 delay와 맟지 않는다면 매개변수 Call back은 작동하지 않을 수도 있는 것이다.
🖱 무한 스크롤 기능 구현하기 : used by Intersection Observer
⭐️ Intersection Observer
The Intersection Observer API provides a way to asynchronously observe changes in the intersection of a target element with an ancestor element or with a top-level document's viewport.
MDN
MDN을 살펴보니, Intersection Observer에 대해서 "타겟으로 관찰하고 있는 엘리먼트와 그 엘리먼트의 부모 혹은 상위 엘리먼트의 뷰포트가 교차되는 부분을 비동기적으로 관찰하는 API"라고 정의하고 있다.
viewport(뷰포트)란 현재 화면에 보여지고 있는 영역을 말한다.
뷰포트 바깥에 위치한 콘텐츠는 스크롤 이벤트를 통해서 볼 수 있다.
위 내용을 종합하면, Intersection Observer란 화면 상에 내가 지정한 타깃이 보이고 있는지를 관찰할 수 있도록 기능을 제공하는 API이다.
😇 Intersection Observer를 사용했을 때 장점
위에서 살펴본 것과 같이, 스크롤을 진행하는 순간마다 이벤트가 호출되어 API에 데이터를 요청하는 작업이 동반된다면 굉장히 많은 메모리 낭비가 일어날 수 있고 이는 메인스레드에 큰 부담을 준다.
-
Intersection Observer는 Scroll 이벤트와 달리 비동기적으로 실행되기 때문에, 디바운스나 쓰로틀을 구현하지 않아도 되어서 훨씬 나은 퍼포먼스를 보여준다. -
또한 매번 화면을 계산해서 그리는 reflow 현상을 일으키지 않기 때문에, 메인스레드에 주는 부담을 줄일 수 있다.
2편에서 이어집니다.
참조
