키워드로 공부하는 데이터 분석 첫 번째 포스팅은 경사하강법입니다.
Gradient Descent 간단한 설명
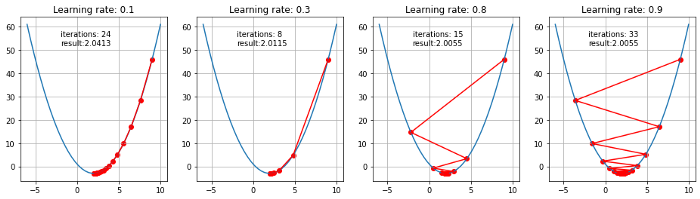
경사하강법이란 함수의 기울기(경사)를 구하여 기울기가 낮은 쪽으로 계속 이동시켜서 극값에 이를때까지 반복시키는 기법입니다.
- 사진 출처 : Gradient Descent Algorithm
데이터 분석을 진행할 때, 실제 정답과 예측값의 오차를 줄이는 것은 중요합니다. 이 때, 실제 값과 예측 값의 차이를 도출하기 위해 사용하는 함수를 비용함수라고 합니다.
비용함수 예시 : RMSE
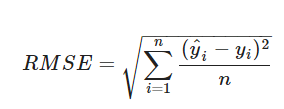
경사하강법은 비용함수를 최소화시키기 위해 함수의 기울기를 이용하는 과정이라고 할 수 있습니다.
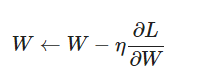

다음과 같은 식이 있을 때, 경사하강법은 미분을 통해 기울기를 구한 방향으로 이동하는 과정을 반복하여 비용함수를 최소화 시키기 위한 함수의 기울기를 찾습니다.
회귀분석을 공부하셨다면, 최소제곱법을 이용하여 모델의 파라미터를 계산할 수 있는데, 경사하강법을 사용하는 이유가 궁금할 수 있습니다. 최소제곱법의 경우, 데이터의 양이 늘어나고 복잡해질수록 계산이 어려워 지고, 계산 시간이 오래 걸리기 때문에, 경사하강법을 사용하여 계산합니다.
경사하강법에 대한 자세한 설명이 필요할 경우
- 두 블로그에 자세하게 설명되어 있으니, 참고하시면 좋을 듯 합니다!
데이터 분석에서의 Gradient Descent 활용 사례
딥러닝에서 Oprimizer에 있어서, Gradient Descent Algorithm을 이용하여 cost function을 최소화 시키기 위해 학습에 이용하기도 하는데요.
Gradient Descent를 활용한 Optimizer
Stochastic Gradient Descent(SGD)
Gradient Descent의 경우 full-batch로 학습하나, SGD의 경우 mini batch로 학습을 진행합니다.

- 공식자체는 Gradient Descent와 같지만, batch 방법에 대한 차이가 존재합니다.
Momentum
SGD에 momentum 개념이 추가 된 것으로, 이전 학습 결과도 반영합니다.
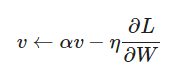
- SGD 공식에서 W가 αv로 바뀐 것을 볼 수 있습니다.
- Momentum의 경우, Gradient Descent의 local minmum(지역최소해) 문제에 빠지는 Gradient Descent의 한계를 보완한 방법이기도 합니다.
AdaGrad
parameter에 대해 동일한 learning rate를 적용하지 않고 각 parameter에 서로 다른 learning rate를 적용시키는 방법입니다.
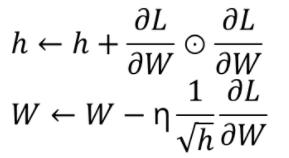
RMSProp
RMSProp는 기울기를 단순 누적하지 않고 지수 가중 이동 평균을 사용하여 최신 기울기들이 더 크게 반영되도록 한 기법 입니다.

Adam
Adam은 AdaGrad + Momentum을 융합한 방법입니다.

- 사진 출처 : Develop PAPER
Gradient Descent를 활용한 Boosting 모델
데이터 분석에서 여러가지 동일한 종류 또는 서로 상이한 모형들의 예측 및 분류 결과를 종합하여 최종적인 의사결정에 활용하는 기법을 앙상블 기법이라고 합니다.
앙상블 기법에는 배깅, 부스팅 등이 있는데, 부스팅 기법은 여러 개의 약한 학습기를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치를 부여를 통해 오류를 개선해 나가면서 학습하는 방식을 의미합니다.
Gradient Descent는 다음과 같은 부스팅 계열 모델에 활용되기도 합니다.
Gradient Boosting
Adaboost는 약한 분류기 들이 상호보완하도록 군차적으로 학습하고, 이들을 조합하여 최종으로 강한 분류기의 성능을 향상시키는 부스팅 계열 모델입니다. Gradient Boosting은 Adaboost와 거의 비슷한 메카니즘을 갖고 있으나, 가중치를 부여하는 과정에서 Gradient Descent를 사용합니다.
XGBoost(eXtreme Gradient Boosting)
XGBoost는 확장가능한 End-to-End Tree Boosting System을 설명합니다.
이는 처음부터 끝까지 데이터의 입력에서 목표한 결과를 출력하는 과정까지 사람 개입 없이 얻는 것을 의미합니다. XGBoost 또한 Gradient Boosting 알고리즘을 기반으로 하고 있습니다. 그러나, Gradient Boosting에 비해 Training Algorithm이 개선 되었고, Optimization Technique가 추가 되었습니다. (Over-fitting을 예방하기 위해 Shrinkage, Column(Feature) Subsampling이 사용되었습니다.)
LightGBM
기존의 모델들의 정보획득을 평가하기 위해 오래 걸리는 시간문제를 보완한 모델입니다. GBM계열의 트리가 level-wise(균형트리 분할)을 채택한 반면, LightGBM은 leaf-wise(리프중심 트리 분할)을 통해 트리가 깊어지며 발생하는 시간과 메모리 모두 절약합니다.
CatBoost(Categorical Boosting)
기존 GBM 기반 알고리즘들이 가지고 있는 target leakage 문제와 범주형 변수 처리 문제를 Ordered Boosting과 Categorical features로 보완하여 나온 모델입니다. CatBoost도 결정 트리에서의 Gradient Boosting Algorithm 기반으로 하는 모델입니다.
XGBoost, LightGBM, CatBoost는 Kaggle이나, DACON과 같은 대회에서도 자주 사용되는 모델입니다. 세 모델에 대해 비교하여 더 자세히 알고 싶으신 분은 하고싶은거하는사람 : XGBoost, LightGBM, CatBoost님의 블로그를 참고하셔도 좋을 것 같습니다!!
마치며..
키워드로 공부하는 데이터 분석의 첫 키워드를 Gradient Boost로 정한 이유는 데이터 분석을 공부함에 있어서 Gradient Boost가 많이 쓰이기 때문에 꼭 알아야 하는 키워드라고 생각했기 때문입니다. 이상으로 첫 포스트를 마치도록 하겠습니다.
