안녕하세요. 😊 오늘은 JAVA의 String 클래스와 정규표현식에 대해 포스팅해보도록 하겠습니다.
String 클래스에 대해서는 예전 포스팅 중에 JAVA 자료형 : 문자와 문자열 포스팅에서 charAt와 length(), JAVA : equals, 정보의 불변성, StringBuffer.append() 포스팅에서는 equals, concat에 대해 다뤘었습니다.
String 클래스에는 이 외에도 다양한 함수들이 있는데, 이번 포스팅에서는 이에 대해 보다 자세히 알아보고, String 클래스 이외에도, 더 나아가 StringTokenizer 클래스의 메서드에 대해서도 알아보는 시간을 갖도록 하겠습니다.
String
Java™ Platform Standard Ed. 8에서 java.lang의 String 클래스를 보면, 다양한 메서드들이 있습니다.
- String 클래스
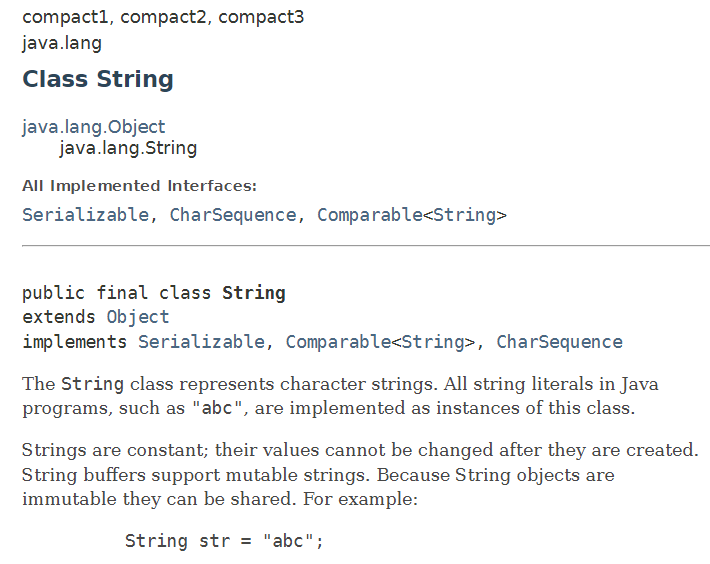
substring

substring 메서드는 String을 쪼개는 함수입니다. 인수로는 beginIndex, 혹은 beginIndex, endIndex가 있습니다.
public class String_velog {
public static void main(String[] args) {
String velog="";
String sub="";
velog="VelogPosting";
sub=velog.substring(0,5);
System.out.println("sub >>> : "+sub);
}
}다음과 같은 코드 있을 때 beginIndex는 0이며, endIndex는 5입니다.

공식 API를 보면 endIndex -1까지 출력이 된다고 나와 있습니다.
이에 따라 0번째인 V부터 5번째 P의 바로 앞 글자인 g까지가 출력됩니다.
출력 결과 : sub >>> : Velog만약, endIndex를 설정하지 않는다면, 어떤 결과가 나올까요?
// 앞뒤 생략
sub=velog.substring(5);5번째 인덱스인 P부터 끝까지 출력되는 것을 확인 할 수 있습니다.
출력 결과 : sub >>> : PostingindexOf
만약, 어느 구간의 글자를 보고 싶은 것이 아니라, 특정 글자를 찾고 싶은 경우에는 indexOf 메서드를 활용할 수 있습니다.

예시로, "VelogPosting"이라는 글자에서 P라는 글자를 찾고 싶을 때 다음과 같이 검색할 수 있습니다.
public class String_velog {
public static void main(String[] args) {
String velog="";
int idxOf=0;
velog="VelogPosting";
idxOf=velog.indexOf("P");
System.out.println("idxOf >>> : "+idxOf);
}
}P라는 글자의 위치는 출력 결과를 통해 알 수 있습니다.
출력 결과 : idxOf >>> : 5lastIndexOf
인덱스를 뒤에서 부터 탐색해서 위치를 찾고 싶을 때는 lastIndexOf를 활용할 수 있습니다.

// 앞뒤 생략
idxOf=velog.lastIndexOf("P");
출력 결과 : idxOf >>> : 5출력 결과는 5가 나옵니다.

약간 의아해 할 수 있는 부분은 뒤에서 g를 0번째 인덱스라고 한다면 5번째 인덱스는 o인데, 왜 5라는 출력 결과가 나올 까요?
len=velog.length();
System.out.println("len >>> : "+len);
출력 결과 : len >>> : 12주석 처리 해놓은 String의 길이 len을 출력하면 12가 나옵니다. 마지막 글자까지의 길이가 12인데 12를 기준으로 하나씩 감소시켰을 때, 5번째에 P가 있다는 것을 의미합니다.
indexOf와 lastIndexOf 주의점
API에서 indexOf의 설명을 잘 보면 Returns에 다음과 같은 글이 있습니다.
Returns:
the index of the first occurrence of the specified substring, or -1 if there is no such occurrence.마찬가지로 lastindexOf의 설명을 잘 보면 Returns에 다음과 같은 글이 있습니다.
Returns:
the index of the last occurrence of the specified substring, or -1 if there is no such occurrence.만약, String 문자열에 없는 값을 찾게 하면 -1이라는 결과가 나온다는 의미입니다.
replace
replace는 특정 char를 새로운 char로 바꾸어 주는 것을 의미합니다.

public class String_velog {
public static void main(String[] args) {
String velog="";
String velog_24="";
velog="Velog@JAVA@Series@24@th@Posting";
velog_24=velog.replace('@','_');
System.out.println("velog_24 >>> : "+velog_24);
}
}다음과 같은 코드가 있을 때 '@'가 '_'로 바뀌어서 출력 됩니다.
출력결과 : velog_24 >>> : Velog_JAVA_Series_24_th_Postingcontains
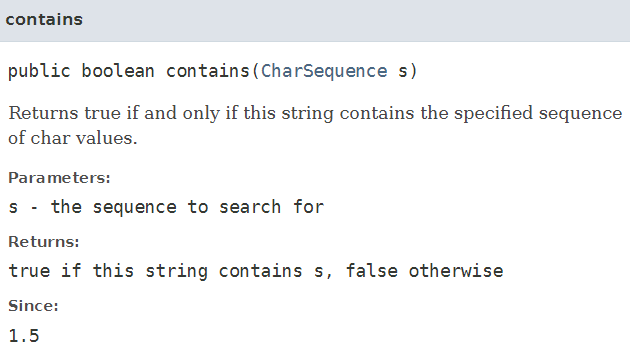
contains 함수는 CharSequence s로 인수를 입력받아 해당 char values의 specified sequence가 있는지를 확인하여 boolean 타입으로 출력시켜 줍니다.
public class String_velog {
public static void main(String[] args) {
String sVal = "Hello Java Testing !! ";
boolean bool = sVal.contains("Hello");
boolean bool_1 = sVal.equals("Hello");
System.out.println("sVal.contains >>> : " + bool);
System.out.println("sVal.equals >>> : "+bool_1);
String sVal1 = "학교종이 땡땡땡 어서 모이자";
bool = sVal1.contains("학교종");
System.out.println("bool >>> : " + bool);
bool = sVal1.contains("땡땡땡");
System.out.println("bool >>> : " + bool);
}
}출력 결과는 다음과 같습니다.
sVal.contains >>> : true
sVal.equals >>> : false
bool >>> : true
bool >>> : trueJAVA : equals, 정보의 불변성, StringBuffer.append() 포스팅에서는 equals를 잠시 다뤘었습니다.
equals는 문자열을 비교하는 함수로 "Hello Java Testing!!"과 "Hello"는 다르기 때문에 false로 결과를 출력하는 반면 contains는 Hello가 있기 때문에, true를 출력하는 것을 볼 수 있습니다.
compareTo

compareTo 메서드는 두 개의 문자열이 동일할 경우, 0을 출력하고,
compareTo()를 호출하는 객체가 인자보다 사전적으로 순서가 앞설 때, 양수를 출력하며,
그 반대의 경우 음수를 출력합니다.
public class String_velog {
public static void main(String[] args) {
String s1 = "a";
String s2 = "a";
String s3 = "z";
System.out.println("s1.compareTo(s1) >>> : " + s1.compareTo(s2));
System.out.println("s1.compareTo(s3) >>> : " + s1.compareTo(s3));
System.out.println("s3.compareTo(s1) >>> : " + s3.compareTo(s1));
}
}출력 결과는 다음과 같습니다.
s1.compareTo(s1) >>> : 0
z보다 a가 사전적으로 순서가 앞 >> 음수
s1.compareTo(s3) >>> : -25
z가 a보다 사전적으로 순서가 앞 >> 양수
s3.compareTo(s1) >>> : 25split
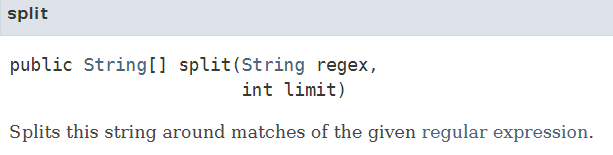
split 함수는 특정 글자를 기준으로 문자열을 쪼개어 배열에 입력하는 함수 입니다.
public class String_velog {
public static void main(String[] args) {
String velog="";
String[] velog_24=null;
velog="Velog@JAVA@Series@24@th@Posting";
velog_24=velog.split("@");
System.out.println("velog_24 >>> : "+velog_24);
for (int i=0; i<6; i++) {
System.out.println("velog_24["+i+"] >>> : "+velog_24[i]);
}
}String 배열로 저장되어, 각 원소를 출력하면 다음과 같이 출력됩니다.
velog_24 >>> : [Ljava.lang.String;@7852e922
velog_24[0] >>> : Velog
velog_24[1] >>> : JAVA
velog_24[2] >>> : Series
velog_24[3] >>> : 24
velog_24[4] >>> : th
velog_24[5] >>> : Postingsplit메서드를 보면 regular expression이 적혀있는 것을 볼 수 있습니다.

정규표현식은 Class Pattern에서 작성되었습니다.

정규표현식은 특정 글자들을 걸러내거나 추출하는 것을 도와줍니다.

유의할 점은 Since 1.4이므로, 1.3 이하 버전에서는 사용을 하지 못합니다.
StringTokenizer
Java™ Platform Standard Ed. 8의java.util에서 StringTokenizer를 검색하면 다음과 같은 화면을 볼 수 있습니다.

Constructor
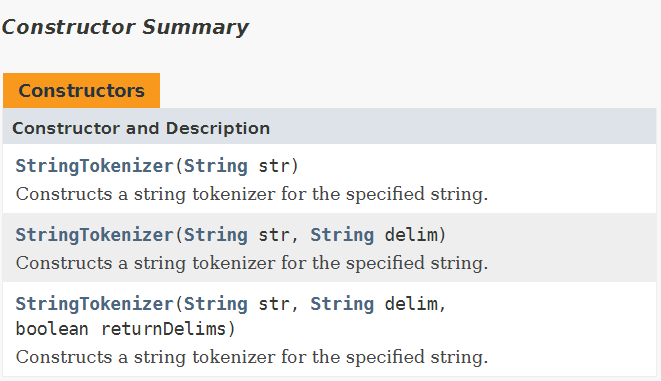
3가지의 생성자가 있는 것을 확인 할 수 있습니다.
Method
hasMoreTokens
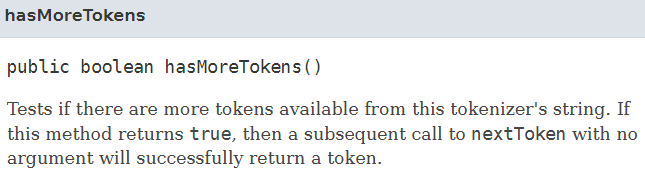
hasMoreTokens는 사용가능한 토큰이 있는지 확인하는 함수입니다.
nextToken
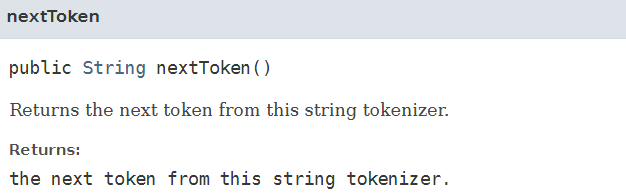
hasMoreTokens와 함께 쓰는 함수로 다음 토큰으로 넘겨주는 함수 입니다.
countTokens

토큰의 개수를 세는 함수입니다.
코드로 살펴보는 StringTokenizer
import java.util.StringTokenizer;
public class String_velog {
public int workToken(String str) {
int tCnt = 0;
if (str !=null && str.length() > 0 ) {
StringTokenizer st = new StringTokenizer(str, " ");
tCnt = st.countTokens();
}
return tCnt;
}
public int charToken(String str){
int cCnt = 0;
if (str !=null && str.length() > 0){
StringTokenizer st = new StringTokenizer(str, " ");
while (st.hasMoreTokens()) {
System.out.println(">>> : " + st.nextToken());
cCnt++;
}
}
return cCnt;
}
public static void main(String[] args) {
String str = "The Curious Case of Benjamin Button";
String_velog sv = new String_velog();
int tCnt = sv.workToken(str);
System.out.println("tCnt >>> : " + tCnt);
int cCnt =sv.charToken(str);
System.out.println("cCnt >>> : "+cCnt);
}
}"The Curious Case of Benjamin Button"라는 문장을 입력한 뒤, 이를 해당 클래스의 workToken 메서드와 charToken 메서드에 보냈을 때 결과를 보는 코드입니다.
위의 코드에서 wordToken 메서드에서 StringTokenizer(String str, String delim) 생성자를 생성하였습니다. 이후, countTokens 메서드를 통해 구분자로 구분 된 토큰의 개수를 구하고, 이를 리턴하였습니다.
한 편, charToken 메서드에서는 StringTokenizer(String str, String delim) 생성자를 생성하였습니다. 이후, 구분자로 구분 된 토큰들을 토큰이 없을 때까지 반복하여 출력시킴과 동시에 반복되는 횟수를 계산하여 이를 리턴하였습니다.
출력결과
tCnt >>> : 6
>>> : The
>>> : Curious
>>> : Case
>>> : of
>>> : Benjamin
>>> : Button
cCnt >>> : 6이상으로 JAVA : String, StringTokenizer 포스팅을 마치도록 하겠습니다. 😊
