Top K Elements in List
문제 
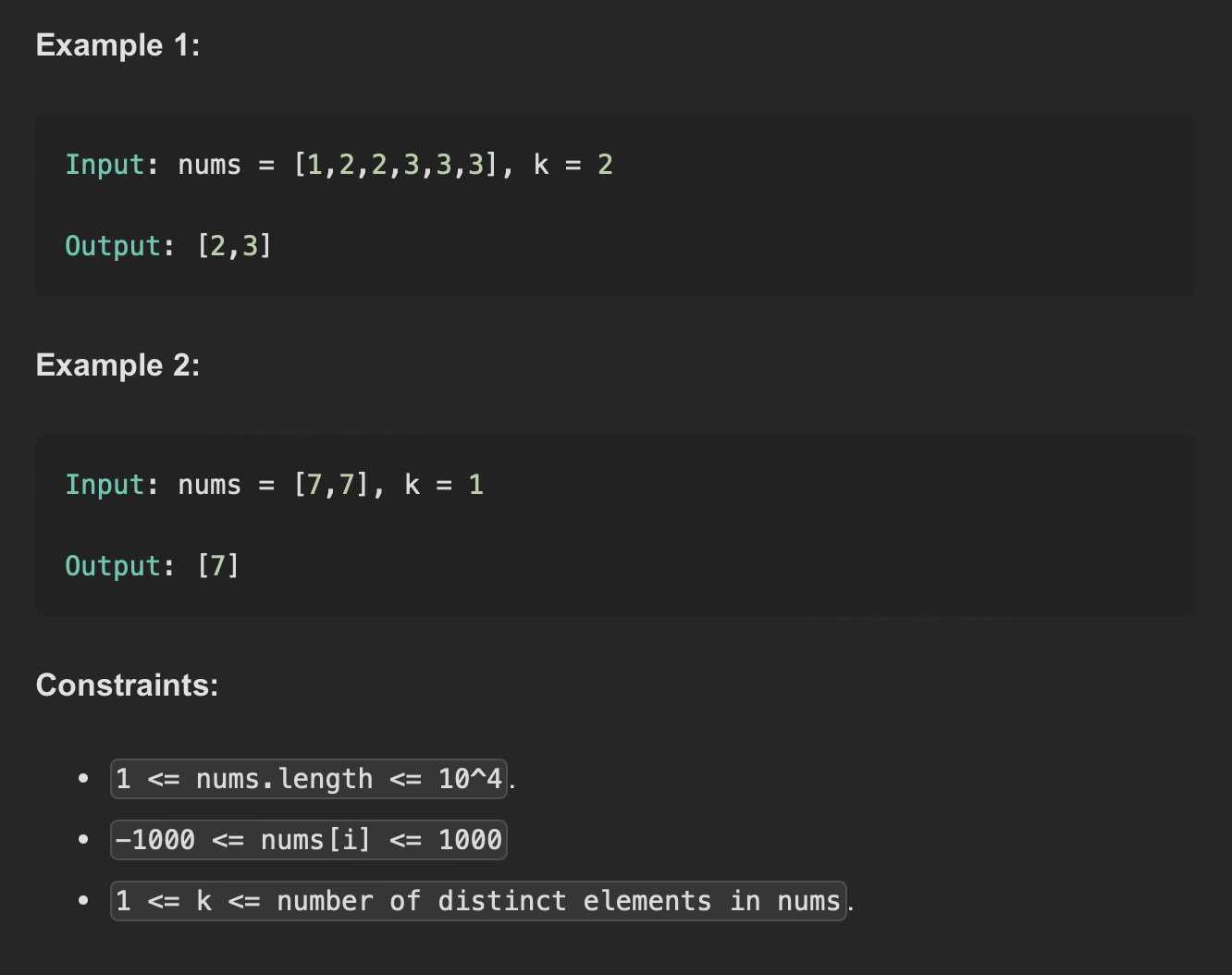
- 정수 배열 번호와 정수 k가 주어지면 배열 내에서 가장 빈번한 k개의 원소를 반환합니다.
- 테스트 사례는 항상 답이 고유하도록 생성됩니다.
- 어떤 순서로든 출력을 반환할 수 있습니다.
해답 참조함
Leet Code Answer
1. Sorting
- Time complexity:
O( n log n )
Space complexity:O(n)
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
count = {}
for num in nums:
count[num] = 1 + count.get(num, 0)
arr = []
for num, cnt in count.items():
arr.append([cnt, num])
arr.sort() #빈도(cnt)를 기준으로 리스트를 오름차순으로 정렬
res = []
while len(res) < k:
res.append(arr.pop()[1])
return rescount.get(num, 0): 딕셔너리의get()메서드를 사용하여, 숫자 num이 딕셔너리에 있으면 그 값(빈도)을 가져오고, 없으면 기본값 0을 사용합니다. 즉, 숫자가 처음 등장하면 0에서 1로, 그 이후에는 기존 빈도에 1을 더해가며 빈도를 기록합니다.count.items(): count 딕셔너리의 키(숫자)와 값(빈도)을 (키, 값) 형태로 반환합니다.items()는 딕셔너리 메서드로, 딕셔너리의 키와 값을 쌍으로(튜플형태로) 반환하는 함수입니다.
2. Heap (우선순위 큐)
- Time complexity: O(nlogk)
Space complexity: O(n)
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
count = {}
for num in nums:
count[num] = 1 + count.get(num, 0)
heap = []
for num in keys():
heapq.heappush(heap, (count[num], num))
if len(heap) > k:
heapq.heappop(heap)
res = []
for i in range(k):
res.append(heapq.heappop(heap)[1])
return res-
get()함수의 의미 :get()함수는 딕셔너리에서 키에 해당하는 값을 가져오는 함수입니다. 하지만 이 함수는 두 번째 인자를 통해 키가 딕셔너리에 없을 때 반환할 기본값을 지정할 수 있습니다.
[dictionary 이름].get(key, default_value)- dict: 딕셔너리 이름
- key: 찾고자 하는 키
- default_value: (선택 사항) 만약 키가 딕셔너리에 없을 경우 반환할 기본값 (기본값은 생략할 수 있으며, 생략 시 None이 반환됨)
- 반환값:
- key가 딕셔너리에 존재하면 해당 값을 반환.
- key가 존재하지 않으면 default_value를 반환.
- default_value를 지정하지 않으면 기본적으로 None을 반환.
-
keys()는 파이썬 딕셔너리 메서드로, 딕셔너리의 모든 키(key)들을 반환하는 함수입니다. 이 함수는 딕셔너리의 키들만을 추출하여 dict_keys 객체로 반환합니다. 이 dict_keys 객체는 반복 가능한(iterable) 객체이기 때문에, for 루프나 다른 반복문에서 사용할 수 있습니다. -
if len(heap) > k: 힙의 크기가 k를 초과할 때
힙에 요소를 계속 삽입하다 보면, 힙의 크기가 k를 초과할 수 있습니다. 즉, 상위 k개의 요소를 유지하려면, 크기가 k를 넘는 순간에는 가장 작은 요소(빈도 기준)를 제거해야 합니다. -
heapq.heappop()은 최소 힙에서 가장 작은 값(즉, 빈도가 가장 작은 요소)을 제거합니다.
3. Bucket Sort
- Time complexity: O(n)
Space complexity: O(n)
- Time complexity: O(n)
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
count = {}
freq = [[] for i in range(len(nums) + 1)]
for num in nums:
count[num] = 1 + count.get(num, 0)
for num, cnt in count.items():
freq[cnt].append(num)
res = []
for i in range(len(freq) - 1, 0, -1):
for num in freq[i]:
res.append(num)
if len(res) == k:
return res- freq = [[] for i in range(len(nums) + 1)] = [ [], [], [], [] ]
for i in range(len(freq) - 1, 0, -1)
이 구문은 빈도가 높은 숫자들부터 탐색하기 위해 freq 리스트를 역순으로 순회합니다.- len(freq) - 1: freq 리스트의 마지막 인덱스부터 시작합니다. 이 인덱스는 가장 큰 빈도를 의미합니다.
- 0 : 0까지 탐색합니다 (빈도 0은 포함하지 않습니다).
- -1: 역순으로 순회하는 것을 의미합니다. 즉, 빈도가 높은 것부터 낮은 것까지 탐색합니다.
range(start, stop, step):- start (선택적): 시퀀스가 시작하는 값입니다. 기본값은 0입니다.
- stop (필수): 시퀀스가 종료되는 값입니다. 이 값은 포함되지 않습니다 (즉, stop 직전까지 숫자들이 생성됩니다).
- step (선택적): 시퀀스에서 숫자가 증가하는 간격을 나타냅니다. 기본값은 1입니다. 양수와 음수 모두 가능합니다.
Chat GPT Answer
1. dictionary와 sort 사용
- O(N log N) — 정렬하는 데 필요한 시간 때문에 O(N log N) 복잡도를 가집니다.
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
frequency_map = {}
for num in nums:
if num in frequency_map:
frequency_map[num] +=1
else:
frequency_map[num] = 1
sorted_items=sorted(frequency_map.items(),
key=lambda item:item[1], reverse=True)
top_k_frequent = [item[0] for item in sorted_items[:k]]
return top_k_frequent- { }는 딕셔너리, [ ]는 배열, 리스트
- nums는 리스트니까 num에 하나씩 들어감. 그래서 if문으로 frequency_map에 num이 있으면 frequency[num]에 1을 더함. 아니면 1로 지정.
(ex. {1:1, 2:2, 3:3} 이런식으로 저장됨. frequency[1]은 1번나왔고, frequency[2]는 2번나오고 이런식이니까)if in구문은 어떤 요소가 리스트나 문자열 같은 시퀀스 자료형에 포함되어 있는지를 확인하는 데 사용됩니다. 즉, 특정 값이 시퀀스 안에 있는지 여부를 확인하는 조건문입니다.
#리스트에서 값이 있는지 확인
my_list = [1, 2, 3, 4, 5]
if 3 in my_list:
print("3은 리스트에 있습니다.")
else:
print("3은 리스트에 없습니다.")
# 결과 : 3은 리스트에 있습니다.- sorted( ) :
sorted(iterable, key=None, reverse=False)- iterable: 정렬할 반복 가능한 객체(리스트, 튜플, 문자열 등).
- key: 정렬 기준을 제공하는 함수. 기본적으로는 None이며, 요소 자체로 정렬합니다.
- reverse: True로 설정하면 내림차순으로 정렬됩니다. 기본값은 False(오름차순).
- Example!!
sorted_items=sorted(frequency_map.items(),key=lambda item:item[1], reverse=True)
--> frequency_map.items()의 튜플들을 key=item[1]을 기준으로 item을 정렬해라. (item[0]은 item이름임.) 그리고 오름차순으로 정렬해라.
- 애로우 함수 대신.. lambda 함수 :
lambda 인자들: 표현식- lambda: 키워드, 익명 함수를 정의합니다.
- 인자들: 함수가 받을 입력값(매개변수).
- 표현식: 입력값을 처리할 연산 또는 반환할 값. 함수의 반환값 역할을 하며, 반드시 하나여야 합니다.
lambda 함수는 여러 줄로 작성할 수 없고, 한 줄만 작성할 수 있습니다. 그 한 줄이 결과적으로 반환되는 값입니다. - Example!!
add = lambda x, y: x + y print(add(3, 5)) # 출력: 8
- 리스트 컴프리헨션
2. collections.Counter와 most_common 사용
: 파이썬의 collections.Counter는 리스트에서 각 요소의 빈도를 쉽게 계산할 수 있습니다. 또한 most_common(k) 메서드를 사용하면 빈도가 높은 상위 k개의 요소를 바로 추출할 수 있습니다.
from collections import Counter
def topKFrequent(nums, k):
# 1. nums의 요소 빈도 계산
count = Counter(nums)
# 2. 빈도가 높은 k개의 요소 반환
return [item for item, freq in count.most_common(k)]- O(N log k) (N은 nums 리스트의 길이) — 빈도 계산과 상위 k개의 요소를 추출하는 데 필요한 복잡도.
3. heapq 모듈을 사용한 우선순위 큐
: 파이썬의 heapq 모듈을 사용하여 상위 k개의 요소를 추출하는 방법입니다. 최소 힙(min heap)을 사용해 빈도가 높은 요소들을 관리할 수 있습니다.
import heapq
from collections import Counter
def topKFrequent(nums, k):
# 1. nums의 요소 빈도 계산
count = Counter(nums)
# 2. 우선순위 큐를 사용해 상위 k개의 요소 추출
return heapq.nlargest(k, count.keys(), key=count.get)- O(N log k) — 상위 k개의 요소만 큐에 저장하므로 효율적입니다.
4. 버킷 정렬 (Bucket Sort)
: 이 방법은 빈도별로 버킷을 만들어, 빈도가 같은 요소들을 그룹화하고, 빈도가 높은 순서대로 상위 k개의 요소를 반환하는 방식입니다
from collections import defaultdict
def topKFrequent(nums, k):
# 1. nums의 요소 빈도 계산
count = defaultdict(int)
for num in nums:
count[num] += 1
# 2. 버킷을 사용해 빈도에 따른 요소들을 그룹화
bucket = [[] for _ in range(len(nums) + 1)]
for num, freq in count.items():
bucket[freq].append(num)
# 3. 빈도가 높은 요소부터 추출
result = []
for i in range(len(bucket) - 1, 0, -1):
for num in bucket[i]:
result.append(num)
if len(result) == k:
return result
- O(N) — 빈도 계산과 버킷 정렬을 수행하는데 모두 O(N) 시간이 소요됩니다.
5. 정렬 후 슬라이싱 방법 (간단한 방식)
: 간단한 방법으로, 직관적이지만 성능이 다소 떨어질 수 있습니다.
from collections import Counter
def topKFrequent(nums, k):
count = Counter(nums)
sorted_items = sorted(count.items(), key=lambda x: x[1], reverse=True)
return [x[0] for x in sorted_items[:k]]
- O(N log N) — 정렬하는 데 필요한 시간이 가장 큽니다.
