마스터와 노드
쿠버네티스를 이해하기 위해서는 먼저 클러스터의 구조를 이해할 필요가 있는데, 구조는 매우 간단하다. 클러스터 전체를 관리하는 컨트롤러로써 마스터가 존재하고, 컨테이너가 배포되는 머신 (가상머신이나 물리적인 서버머신)인 노드가 존재한다.
https://img1.daumcdn.net/thumb/R720x0.q80/?scode=mtistory2&fname=http%3A%2F%2Fcfile9.uf.tistory.com%2Fimage%2F99172C485B02D9C82A439B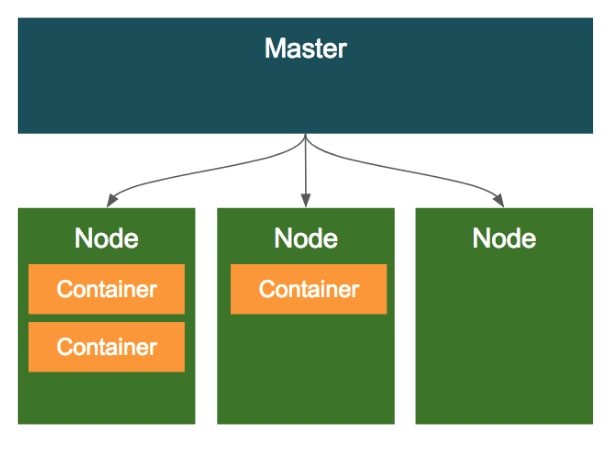
{kind=link}
오브젝트
쿠버네티스를 이해하기 위해서 가장 중요한 부분이 오브젝트이다. 가장 기본적인 구성단위가 되는 기본 오브젝트(Basic object)와, 이 기본 오브젝트(Basic object) 를 생성하고 관리하는 추가적인 기능을 가진 컨트롤러(Controller) 로 이루어진다. 그리고 이러한 오브젝트의 스펙(설정)이외에 추가정보인 메타 정보들로 구성이 된다고 보면 된다.
기본 오브젝트 (Basic Object)
쿠버네티스에 의해서 배포 및 관리되는 가장 기본적인 오브젝트는 컨테이너화되어 배포되는 애플리케이션의 워크로드를 기술하는 오브젝트로 Pod,Service,Volume,Namespace 4가지가 있다.
간단하게 설명 하자면 Pod는 컨테이너화된 애플리케이션, Volume은 디스크, Service는 로드밸런서 그리고 Namespace는 패키지명 정도로 생각하면 된다.
Pod
Pod 는 쿠버네티스에서 가장 기본적인 배포 단위로, 컨테이너를 포함하는 단위이다.
쿠버네티스의 특징중의 하나는 컨테이너를 개별적으로 하나씩 배포하는 것이 아니라 Pod 라는 단위로 배포하는데, Pod는 하나 이상의 컨테이너를 포함한다.
아래는 간단한 Pod를 정의한 오브젝트 스펙이다. 하나하나 살펴보면
apiVersion: v1 #스크립트를 실행하기 위한 쿠버네티스 API 버전이다 보통 v1을 사용
kind: Pod #리소스의 종류
metadata: #각 리소스의 이름, 라벨 등 메타데이터 기재
name: nginx
spec: #리소스 상세 스펙 정의
containers: #pod는 컨테이너를 갖고 있어 컨테이너 정의
- name: nginx #컨테이너 이름
image: nginx:1.7.9 #컨테이너에서 이용할 이미지
ports: #컨테이너 포트
- containerPort: 8090Pod 안에 한개 이상의 컨테이너를 가지고 있을 수 있다고 했는데 왜 개별적으로 하나씩 컨테이너를 배포하지 않고 여러개의 컨테이너를 Pod 단위로 묶어서 배포하는 것인가?
Pod는 다음과 같이 매우 재미있는 특징을 갖는다.
- Pod 내의 컨테이너는 IP와 Port를 공유한다.
두 개의 컨테이너가 하나의 Pod를 통해서 배포되었을때, localhost를 통해서 통신이 가능하다.
예를 들어 컨테이너 A가 8080, 컨테이너 B가 7001로 배포가 되었을 때, B에서 A를 호출할때는 localhost:8080 으로 호출하면 되고, 반대로 A에서 B를 호출할때에넌 localhost:7001로 호출하면 된다. - Pod 내에 배포된 컨테이너간에는 디스크 볼륨을 공유할 수 있다.
근래 애플리케이션들은 실행할때 애플리케이션만 올라가는것이 아니라 Reverse proxy, 로그 수집기등 다양한 주변 솔루션이 같이 배포 되는 경우가 많고, 특히 로그 수집기의 경우에는 애플리케이션 로그 파일을 읽어서 수집한다. 애플리케이션 (Tomcat, node.js)와 로그 수집기를 다른 컨테이너로 배포할 경우, 일반적인 경우에는 컨테이너에 의해서 파일 시스템이 분리되기 때문에, 로그 수집기가 애플리케이션이 배포된 컨테이너의 로그파일을 읽는 것이 불가능 하지만, 쿠버네티스의 경우 하나의 Pod 내에서는 컨테이너들끼리 볼륨을 공유할 수 있기 때문에 다른 컨테이너의 파일을 읽어올 수 있다.
https://img1.daumcdn.net/thumb/R720x0.q80/?scode=mtistory2&fname=http%3A%2F%2Fcfile22.uf.tistory.com%2Fimage%2F9913C64D5B02D9C8264D8A
{kind=link}
Volume
Pod가 기동할때 디폴트로, 컨테이너마다 로컬 디스크를 생성해서 기동되는데, 이 로컬 디스크의 경우에는 영구적이지 못하다. 즉 컨테이너가 리스타트 되거나 새로 배포될때 마다 로컬 디스크는 Pod 설정에 따라서 새롭게 정의되서 배포되기 때문에, 디스크에 기록된 내용이 유실된다.
데이타 베이스와 같이 영구적으로 파일을 저장해야 하는 경우에는 컨테이너 리스타트에 상관 없이 파일을 영속적으로 저장애햐 하는데, 이러한 형태의 스토리지를 볼륨이라고 한다.
볼륨은 컨테이너의 외장 디스크로 생각하면 된다. Pod가 기동할때 컨테이너에 마운트해서 사용한다.
앞에서 언급한것과 같이 쿠버네티스의 볼륨은 Pod내의 컨테이너간의 공유가 가능하다.
https://img1.daumcdn.net/thumb/R720x0.q80/?scode=mtistory2&fname=http%3A%2F%2Fcfile9.uf.tistory.com%2Fimage%2F99FC343C5B02D9C8108AAE
{kind=link}
웹 서버를 배포하는 Pod가 있을때, 웹서비스를 서비스하는 Web server 컨테이너, 그리고 컨텐츠의 내용 (/htdocs)를 업데이트하고 관리하는 Content mgmt 컨테이너, 그리고 로그 메세지를 관리하는 Logger라는 컨테이너이가 있다고 하자
WebServer 컨테이너는 htdocs 디렉토리의 컨테이너를 서비스하고, /logs 디렉토리에 웹 억세스 기록을 기록한다.
Content 컨테이너는 htdocs 디렉토리의 컨텐트를 업데이트하고 관리한다.
Logger 컨테이너는 logs 디렉토리의 로그를 수집한다.
이 경우 htdocs 컨텐츠 디렉토리는 WebServer와 Content 컨테이너가 공유해야 하고 logs 디렉토리는 Webserver 와 Logger 컨테이너가 공유해야 한다. 이러한 시나리오에서 볼륨을 사용할 수 있다.
아래와 같이 htdocs와 logs 볼륨을 각각 생성한 후에, htdocs는 WebServer와, Contents management 컨테이너에 마운트 해서 공유하고, logs볼륨은 Logger와 WebServer 컨테이너에서 공유하도록 하면된다.
{kind=link}
쿠버네티스는 다양한 외장 디스크를 추상화된 형태로 제공한다. iSCSI나 NFS와 같은 온프렘 기반의 일반적인 외장 스토리지 이외에도, 클라우드의 외장 스토리지인 AWS EBS, Google PD,에서 부터 github, glusterfs와 같은 다양한 오픈소스 기반의 외장 스토리지나 스토리지 서비스를 지원하여, 스토리지 아키텍처 설계에 다양한 옵션을 제공한다.
Service
Pod와 볼륨을 이용하여, 컨테이너들을 정의한 후에, Pod 를 서비스로 제공할때, 일반적인 분산환경에서는 하나의 Pod로 서비스 하는 경우는 드물고, 여러개의 Pod를 서비스하면서, 이를 로드밸런서를 이용해서 하나의 IP와 포트로 묶어서 서비스를 제공한다.
Pod의 경우에는 동적으로 생성이 되고, 장애가 생기면 자동으로 리스타트 되면서 그 IP가 바뀌기 때문에, 로드밸런서에서 Pod의 목록을 지정할 때는 IP주소를 이용하는 것은 어렵다. 또한 오토 스케일링으로 인하여 Pod 가 동적으로 추가 또는 삭제되기 때문에, 이렇게 추가/삭제된 Pod 목록을 로드밸런서가 유연하게 선택해 줘야 한다.
그래서 사용하는 것이 라벨(label)과 라벨 셀렉터(label selector) 라는 개념이다.
서비스를 정의할때, 어떤 Pod를 서비스로 묶을 것인지를 정의하는데, 이를 라벨 셀렉터라고 한다. 각 Pod를 생성할때 메타데이타 정보 부분에 라벨을 정의할 수 있다. 서비스는 라벨 셀렉터에서 특정 라벨을 가지고 있는 Pod만 선택하여 서비스에 묶게 된다.
아래 그림은 서비스가 라벨이 “myapp”인 서비스만 골라내서 서비스에 넣고, 그 Pod간에만 로드밸런싱을 통하여 외부로 서비스를 제공하는 형태이다.
{kind=link}
이를 스펙으로 정의해보면 대략 다음과 같다.
kind: Service # 리소스 종류가 svc
apiVersion:
metadata:
name: my-service #서비스 이름
spec:
selector: # app:myapp인 파드만 아래 포트요처으로 서비스를 제공
app: myapp
ports:
- protocol: TCP
port: 80
targetPort: 9376Name space
네임스페이스는 한 쿠버네티스 클러스터내의 논리적인 분리단위라고 보면 된다.
Pod,Service 등은 네임 스페이스 별로 생성이나 관리가 될 수 있고, 사용자의 권한 역시 이 네임 스페이스 별로 나눠서 부여할 수 있다.
즉 하나의 클러스터 내에, 개발/운영/테스트 환경이 있을때, 클러스터를 개발/운영/테스트 3개의 네임 스페이스로 나눠서 운영할 수 있다. 네임스페이스로 할 수 있는 것은
사용자별로 네임스페이스별 접근 권한을 다르게 운영할 수 있다.
네임스페이스별로 리소스의 쿼타 (할당량) 을 지정할 수 있다. 개발계에는 CPU 100, 운영계에는 CPU 400과 GPU 100개 식으로, 사용 가능한 리소스의 수를 지정할 수 있다.
네임 스페이스별로 리소스를 나눠서 관리할 수 있다. (Pod, Service 등)
주의할점은 네임 스페이스는 논리적인 분리 단위이지 물리적이나 기타 장치를 통해서 환경을 분리(Isolation)한것이 아니다. 다른 네임 스페이스간의 pod 라도 통신은 가능하다.
물론 네트워크 정책을 이용하여, 네임 스페이스간의 통신을 막을 수 있지만 높은 수준의 분리 정책을 원하는 경우에는 쿠버네티스 클러스터 자체를 분리하는 것을 권장한다.
라벨
앞에서 잠깐 언급했던 것 중의 하나가 label 인데, 라벨은 쿠버네티스의 리소스를 선택하는데 사용이 된다. 각 리소스는 라벨을 가질 수 있고, 라벨 검색 조건에 따라서 특정 라벨을 가지고 있는 리소스만을 선택할 수 있다.
이렇게 라벨을 선택하여 특정 리소스만 배포하거나 업데이트할 수 있고 또는 라벨로 선택된 리소스만 Service에 연결하거나 특정 라벨로 선택된 리소스에만 네트워크 접근 권한을 부여하는 등의 행위를 할 수 있다.
라벨은 metadata 섹션에 키/값 쌍으로 정의가 가능하며, 하나의 리소스에는 하나의 라벨이 아니라 여러 라벨을 동시에 적용할 수 있다.
"metadata": {
"labels": {
"key1" : "value1",
"key2" : "value2"
}
}
셀렉터를 사용하는 방법은 오브젝트 스펙에서 selector 라고 정의하고 라벨 조건을 적어 놓으면 된다.
쿠버네티스에서는 두 가지 셀렉터를 제공하는데, 기본적으로 Equaility based selector와, Set based selector 가 있다.
Equality based selector는 같냐, 다르냐와 같은 조건을 이용하여, 리소스를 선택하는 방법으로
environment = dev
tier != frontend
식으로, 등가 조건에 따라서 리소스를 선택한다.
이보다 향상된 셀렉터는 set based selector로, 집합의 개념을 사용한다.
environment in (production,qa) 는 environment가 production 또는 qa 인 경우이고,
tier notin (frontend,backend)는 environment가 frontend도 아니고 backend도 아닌 리소스를 선택하는 방법이다.
다음 예제는 my-service 라는 이름의 서비스를 정의한것으로 셀렉터에서 app: myapp 정의해서 Pod의 라벨 app이 myapp 것만 골라서 이 서비스에 바인딩해서 9376 포트로 서비스 하는 예제이다.
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
selector:
app: myapp
ports:
- protocol: TCP
port: 80
targetPort: 9376컨트롤러
앞에서 소개한 4개의 기본 오브젝트로, 애플리케이션을 설정하고 배포하는 것이 가능한데 이를 조금 더 편리하게 관리하기 위해서 쿠버네티스는 컨트롤러라는 개념을 사용한다.
컨트롤러는 기본 오브젝트들을 생성하고 이를 관리하는 역할을 해준다. 컨트롤러는 Replication Controller (aka RC), Replication Set, DaemonSet, Job, StatefulSet, Deployment 들이 있다. 각자의 개념에 대해서 살펴보도록 하자.
-- 본 포스팅은 조대협님의 블로그를 기반으로 작성하였습니다
