외부 API 작업, RabbitMQ로 비동기 처리하기
실사용자가 이용하는 개발자 커뮤니티 홈페이지 프로젝트에서 구현한 기능과 개발 과정을 정리한 포스트입니다.
배경

이 프로젝트에서는 LLM 호출과 크롤링 같은 외부 API 작업이 핵심 기능에 포함되어 있다.
이런 작업들은 n초 이상 소요되는 I/O 바운드 작업이다.
문제 정의
- 스레드 고갈: 외부 API의 긴 응답 시간으로 스레드가 I/O 대기에 블로킹되고, 요청이 조금만 늘어도 스레드가 고갈되어 전체 요청 처리가 멈춘다.
- 장애 전파: 외부 API 장애 시 대기 중인 스레드가 풀리지 않아, 외부 문제가 우리 서비스 장애로 이어진다.
- 클라이언트 응답 지연: 외부 API 작업이 완료될 때까지 클라이언트가 동기적으로 대기해야 하므로, 외부 API가 정상이더라도 응답이 느리다.
결국, 서버가 먹통이 되고 다운까지 이어질 수 있는 상황이 된다.
이런 문제를 해결하기 위해 외부 API 작업을 별도 워커로 분리하고, 메시지 큐를 통해 비동기로 처리하는 구조를 도입하기로 했다. API 서버는 큐에 메시지만 넣고 즉시 응답하며, 실제 작업은 워커가 큐에서 메시지를 꺼내 독립적으로 처리하는 방식이다.
Queue 비교
Redis Queue (List/Stream)
- 메모리 기반 (빠른 속도)
- List 자료구조로 직접 큐를 구현하거나, Stream 사용
- 메모리 기반이라 Redis가 죽으면 데이터가 유실될 수 있다.
RabbitMQ
- 메시지 브로커
- Exchange → Binding → Queue 구조로, 유연한 라우팅 지원
- 다양한 Exchange 타입 지원 (Direct, Topic, Fanout, Headers)
- 메시지 단위로 ACK/NACK 처리, Dead Letter Queue 지원
- 메시지가 소비되면 큐에서 사라진다.
Kafka
- 분산 로그 시스템
- 토픽을 여러 파티션으로 나누어 클러스터 노드에 분산 저장
- 메시지를 소비해도 삭제하지 않고 일정 기간 디스크에 보존
- 같은 토픽을 여러 컨슈머 그룹이 읽을 수 있다.
Kafka는 홈페이지 수준의 트래픽과 소규모 팀 운영 부담이 크다. Redis Queue는 DLQ나 메시징 기능을 직접 구현해야 하는 점이 부담이었다. 따라서 메시지 영구 보존이 필요 없고, DLQ/라우팅 등을 지원해주는 RabbitMQ가 가장 적합하다고 판단했다.
구현
기능별 큐 타입
public enum QueueType {
CRAWL_QUEUE("crawl_queue"),
RESUME_QUEUE("resume_queue"),
CS_QUEUE("cs_queue"),
CRAWL_DEAD_LETTER_QUEUE("crawl_deadletter_queue"),
RESUME_DEAD_LETTER_QUEUE("resume_deadletter_queue"),
CS_DEAD_LETTER_QUEUE("cs_deadletter_queue");
private final String name;
// ...
}공통 전송 로직
/** 큐에 메시지 전송 */
public void sendToQueue(
QueueType queueType, Map<String, String> data, String taskId, String type) {
try {
rabbitTemplate.convertAndSend(
queueType.getName(),
data,
message -> {
message.getMessageProperties().setMessageId(taskId);
message.getMessageProperties().setType(type);
message.getMessageProperties().setContentType("application/json");
return message;
});
// ...
}
// 재시도 시 같은 큐로 다시 넣기
public void retryToQueue(QueueType queueType, Map<String, String> data, int nextRetryCount) {
rabbitTemplate.convertAndSend(queueType.getName(), data, message -> {
message.getMessageProperties().setContentType("application/json");
return message;
});
}
// 실패 메시지 → DLQ
public void sendToDeadLetterQueue(QueueType queueType, Map<String, String> data) {
rabbitTemplate.convertAndSend(queueType.getName(), data, ...);
}결과 분석
- Network I/O로 인한 스레드 블로킹이 해소되었다.
- 외부 API 응답 대기 중 해당 서버 장애가 우리 서비스 전체로 전파되는 문제가 해결되었다.
- 클라이언트에게 대기 시간 없이 즉시 응답이 가능해졌다.
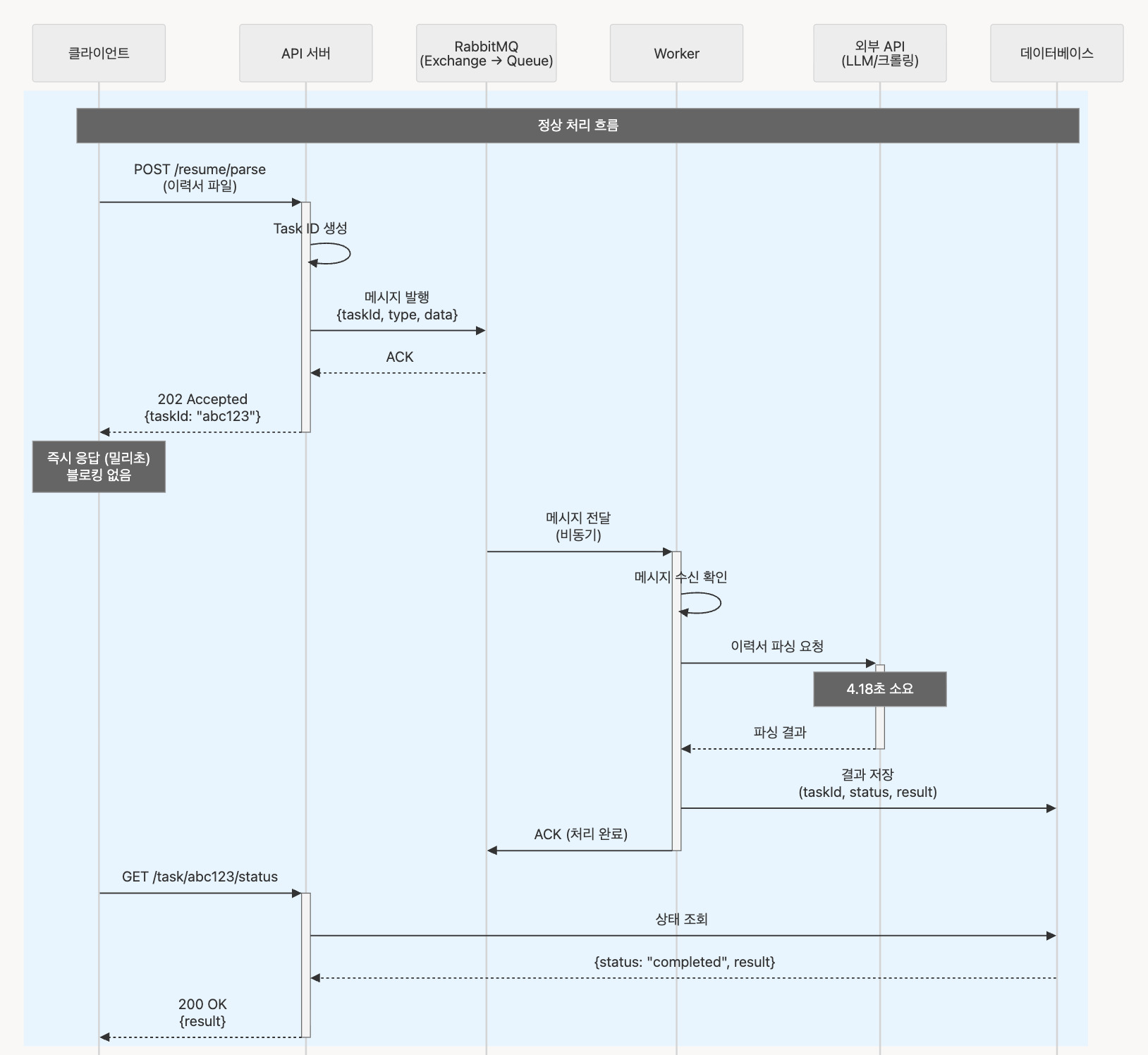
아래는 AI가 이력서를 파싱하는 시간을 Jaeger 트레이스로 확인한 결과다.
총 4.18s가 소요되는 작업을 비동기로 처리하여 클라이언트는 큐에 메시지를 넣는 시간(ms)만 기다리면 된다.
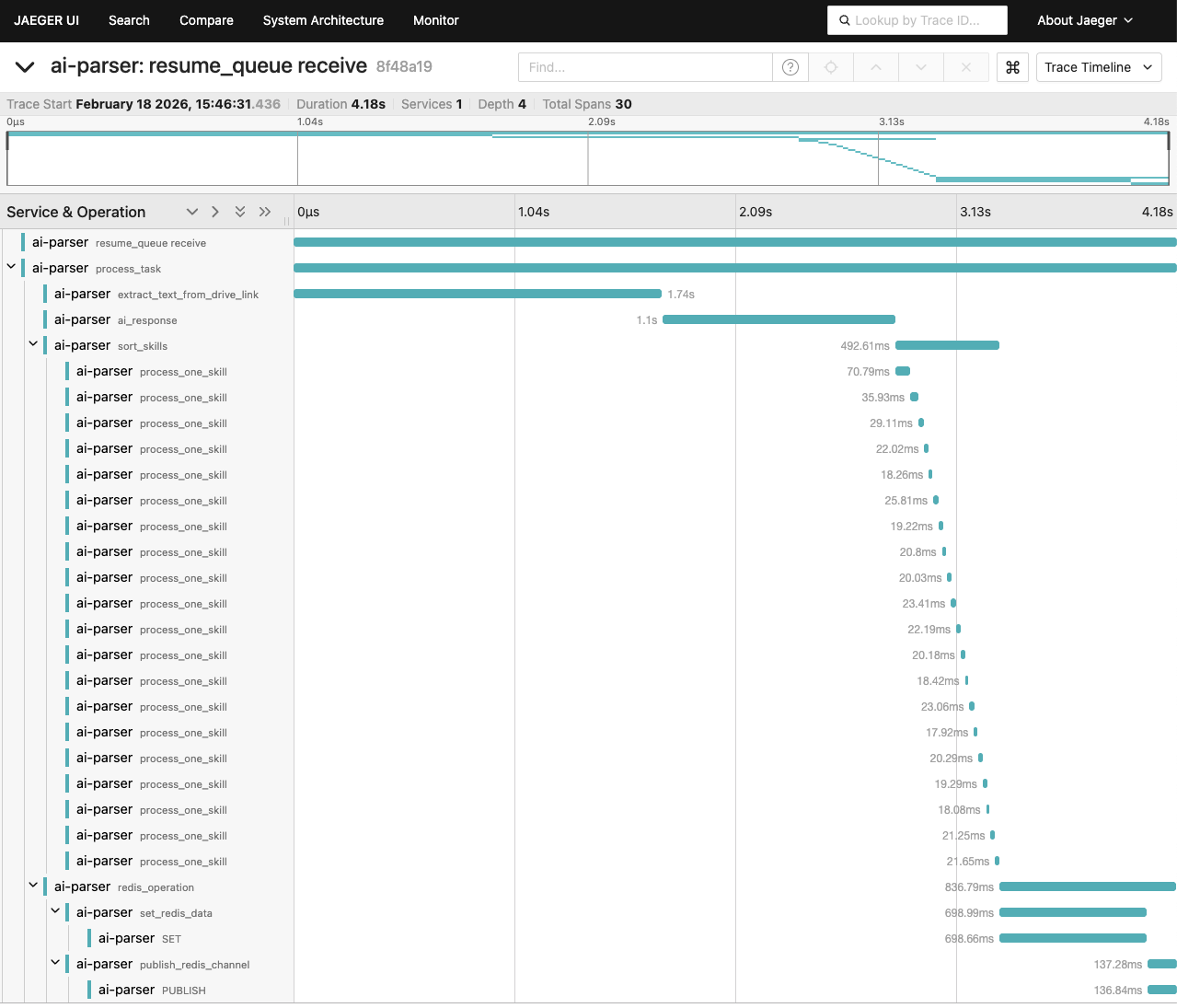
비동기 처리 로직 시퀀스 다이어그램