🧠 JPA (Java Persistence API)란?
- Java에서 객체와 관계형 데이터베이스(RDB)의 패러다임 불일치 문제를 해결해 주는 ORM(Object-Relational Mapping) 기술의 표준 인터페이스
-
☑️ Java 진영의
ORM(Object-Relational Mapping)표준 -
☑️ 대표 구현체:
Hibernate -
☑️ Java 객체를 RDB 테이블에 자동 매핑함 → SQL 작성 없이 DB 작업 가능
🖼️ 작동 구조
개발자 ↔ JPA(인터페이스) ↔ 구현체(Hibernate) ↔ DB→ JDBC처럼 직접 SQL 작성할 필요 없음
→ 다양한 DB에 이식성 확보 (MySQL ↔ Oracle도 쉽게 전환 가능)
✨ JPA를 사용하는 이유
🚀 1. 생산성 (개발 속도 향상)
// 저장 → persist: 영구히 저장
jpa.persist(tutor);
// 조회
Tutor tutor = jpa.find(Tutor.class, tutorId);
// 수정
tutor.setName("수정할 이름");
// 삭제
jpa.remove(tutor);→ 마치 List<T>에 저장하듯 편리하게 사용
→ 복잡한 SQL 없이 메서드로 간단히 조작 가능
🔧 2. 유지 보수성 (코드 변경에 유연)
// 기존
public class Tutor {
private String id;
private String name;
}
// 필드 수정
public class Tutor {
private String id;
private String name;
private Integer age;
}→ 필드가 바뀌어도 SQL 수정 불필요
→ JPA가 자동으로 적절한 SQL 생성
🧩 3. 패러다임 불일치 문제 해결
🧬 상속 매핑
jpa.persist(tutor);→ 상속된 객체도 JPA가 자동으로 슈퍼타입/서브타입 나누어 INSERT/SELECT 수행
🔗 연관관계 매핑
tutor.setCompany(company);
jpa.persist(company); // 자동으로 연관관계도 저장→ 객체 참조 기반 관계도 마치 컬렉션 다루듯 편리하게 처리
🕸️ 객체 그래프 탐색
Tutor tutor = jpa.find(Tutor.class, tutorId);
Company company = tutor.getCompany();→ 연관된 객체도 get()만 하면 끝 → 신뢰성 높은 계층 코드 가능
⚖️ 객체 비교
Tutor t1 = jpa.find(Tutor.class, id);
Tutor t2 = jpa.find(Tutor.class, id);
t1 == t2; // true (같은 트랜잭션 내에서는 동일 객체 보장)→ 같은 데이터를 여러 번 불러와도 동일한 인스턴스 보장 (트랜잭션 내)
⚡ 4. 성능 최적화
🗃️ 1차 캐시
Tutor t1 = jpa.find(Tutor.class, id); // DB 조회
Tutor t2 = jpa.find(Tutor.class, id); // 캐시에서 조회
t1 == t2; // true→ 한 트랜잭션 내에서는 동일 ID로 다시 조회해도 SQL 실행 안 함
📦 쓰기 지연 (Write-Behind)
transaction.begin();
jpa.persist(company);
jpa.persist(tutor1);
jpa.persist(tutor2);
transaction.commit(); // 한번에 JDBC batch 전송→ 여러 INSERT를 하나의 트랜잭션으로 묶어 한 번에 DB로 전송 → 네트워크 비용 절감
⏳ 지연 로딩 vs 즉시 로딩
// 지연 로딩
Tutor tutor = jpa.find(Tutor.class, id); // SELECT * FROM tutor
Company company = tutor.getCompany(); // SELECT * FROM company
// 즉시 로딩
Tutor tutor = jpa.findWithJoin(id); // JOIN으로 한번에 조회→ 지연 로딩: 필요한 순간 조회 → 효율적
→ 즉시 로딩: 미리 JOIN → 응답 시간 줄이기
🛠️ Hibernate Dialect란?
- Hibernate가 사용하는 데이터베이스 방언(dialect)을 지정하는 설정
- 각 DBMS의 SQL 문법 차이를 자동으로 보정하여 동작
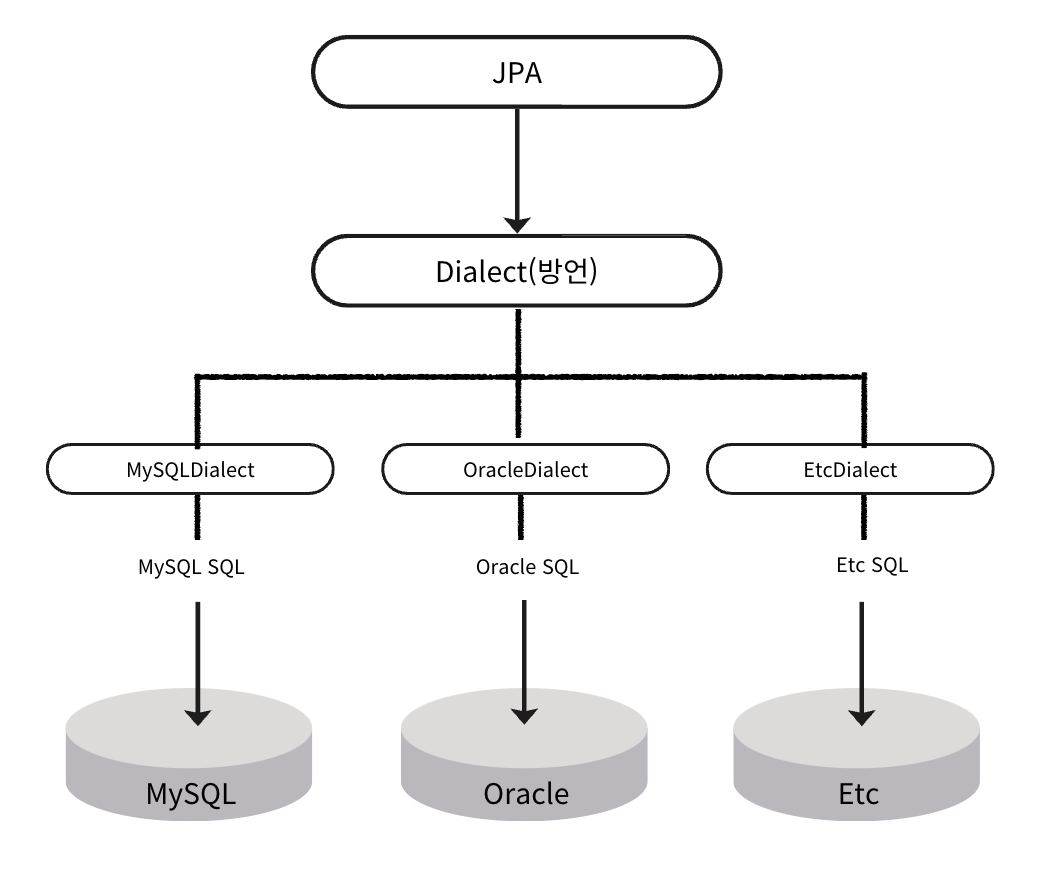
MySQL,Oracle,PostgreSQL등 DB는 SQL 문법이 미세하게 다름- Dialect 설정만 바꾸면 동일한 코드로 여러 DB 지원 가능
🚩 예시: 페이징
| DBMS | 문법 |
|---|---|
| MySQL | LIMIT 0, 10 |
| Oracle | ROWNUM <= 10 |
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL8Dialect➡️ JPA는 이 설정을 통해 SQL을 자동 조정하므로 DB 독립성 보장
🧠 요약 정리
| 항목 | JPA 사용 시 장점 |
|---|---|
| ✅ 생산성 | 메서드만으로 저장/조회/수정 가능 |
| ✅ 유지 보수 | 객체만 수정해도 SQL 자동 생성 |
| ✅ 패러다임 해결 | 상속, 연관관계, 비교 모두 지원 |
| ✅ 성능 | 캐시, 지연 로딩, 배치로 최적화 |
| ✅ 이식성 | Dialect 설정으로 DB 전환 쉬움 |
