다익스트라 알고리즘
다익스트라 알고리즘은 가중치 간선으로 연결된 그래프에서 최단 경로를 찾는 알고리즘으로, 그리디 알고리즘과 다이나믹 프로그래밍을 결합한 형태입니다. 시간 복잡도는 O(간선의 수 X log 노드의 수) 입니다. 다익스트라 알고리즘의 로직은 다음과 같습니다.
- costs 배열을 선언하고 무한대의 값으로 초기화하고, 이곳에 시작 노드에서부터의 비용을 저장할 것입니다.
- 노드와 가중치를 모두 우선순위 큐(Priority Queue)에 저장합니다.
- 시작 노드와 연결된 노드들 중에 가장 비용이 작은것부터 pop합니다.
- 가장 비용이 작은 노드과 연결된 노드를 우선순위 큐에 추가합니다. 그리고 만약 costs 배열에 저장된 값이 더 크다면, 그 costs 배열에 그 노드까지의 비용을 저장합니다.
- 위의 과정을 반복합니다.
다음과 같은 그래프에서, 1 → 7 의 최단 경로를 구하려면 이 과정을 수행합니다.
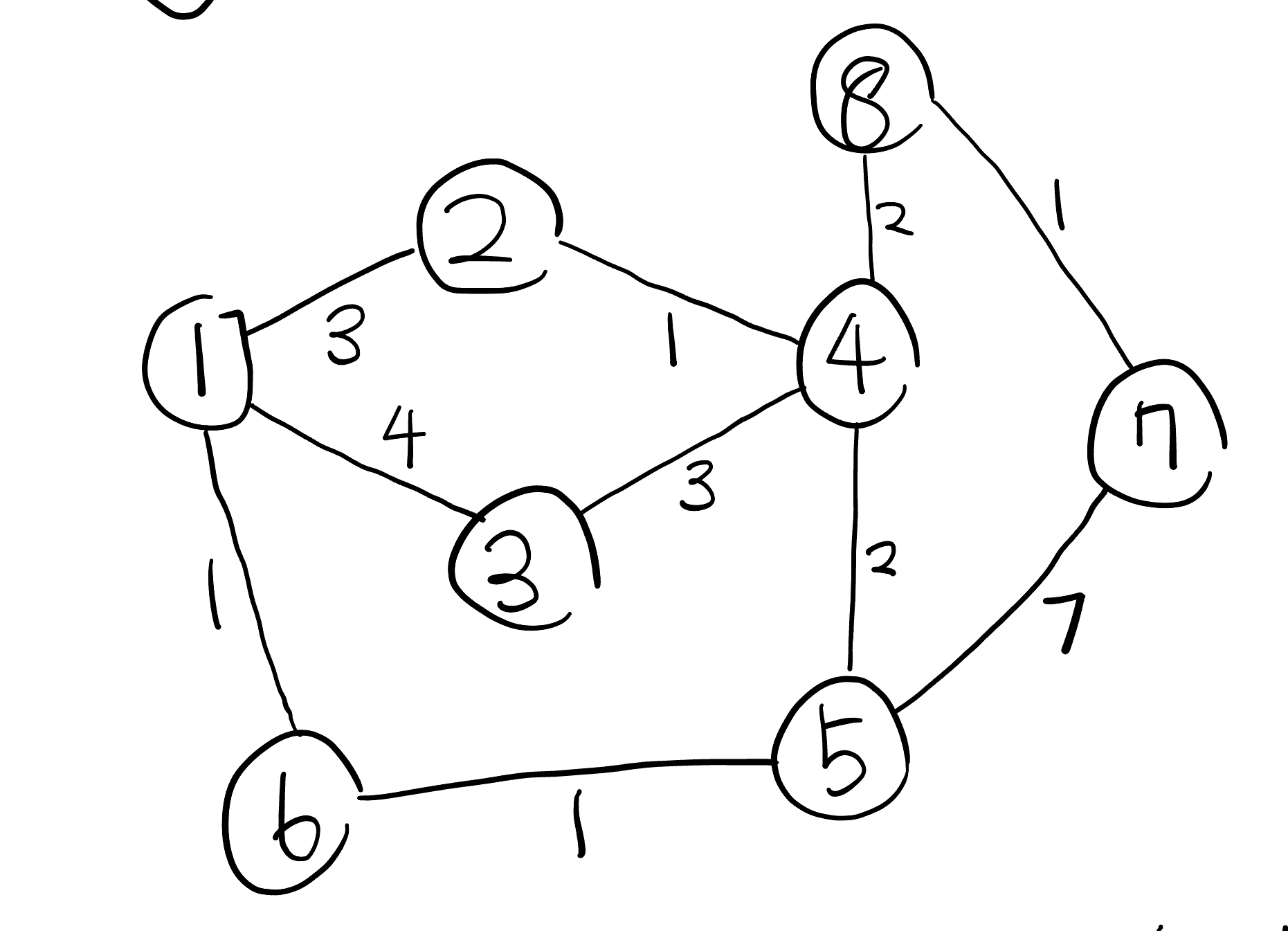
costs 배열 생성
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| infinity | infinity | infinity | infinity | infinity | infinity | infinity | infinity |
Step #1
첫번째 원소인 1은 0으로 초기화하고, 1에 연결된 노드중에서 가중치가 가장 작은것부터 탐색합니다.
queue : (0 : cost, 1 : node) ← popped
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| 0 | infinity | infinity | infinity | infinity | infinity | infinity | infinity |
1에서 가장 비용이 적은 원소인 6을 탐색합니다. 이때까지의 비용과 그 원소까지의 거리를 합한 것이 지금까지 탐색했던 해당 원소까지의 비용보다 작다면, costs 배열의 그 원소를 변경합니다. 그리고, 그 원소와 비용을 우선순위 큐에 추가합니다.
queue: (1, 6)
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| 0 | infinity | infinity | infinity | infinity | 1 | infinity | infinity |
이제 두번째로 작은 원소인 3를 탐색합니다. 위의 과정을 반복하여, 다음과 같이 실행됩니다.
queue: (1, 6), (4, 3)
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| 0 | infinity | 4 | infinity | infinity | 1 | infinity | infinity |
queue: (1, 6), (3, 2), (4, 3)
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| 0 | 3 | 4 | infinity | infinity | 1 | infinity | infinity |
Step #2
이제 queue에 추가된 (1, 6)에서 탐색을 할 차례입니다. 위의 과정을 반복하여 탐색합니다.
queue: (2, 5), (3, 2), (4, 3)
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| 0 | 3 | 4 | infinity | 1 + 1 | 1 | infinity | infinity |
Step #3
5번 노드에서 탐색을 계속합니다.
queue: (3, 2), (4, 3), (4, 4)
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| 0 | 3 | 4 | 2+2 | 2 | 1 | infinity | infinity |
queue: (3, 2), (4, 3), (4, 4), (9, 7)
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| 0 | 3 | 4 | 4 | 2 | 1 | 2+7 | infinity |
Step #4
이제 2번 노드에서 탐색을 시작합니다.
queue: (4, 3), (4, 4), (9, 7)
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| 0 | 3 | 4 | 4 == 3 + 1 | 2 | 1 | 9 | infinity |
이때, 4번 노드까지 가는 거리가 더 작지 않기 때문에 queue에 추가하지 않습니다.
Step #5
이제 3번 노드에서 탐색을 시작합니다.
queue: (4, 4), (9, 7)
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| 0 | 3 | 4 | 4 < 3 + 4 | 2 | 1 | 9 | infinity |
3번 노드에서 4번 노드까지 가는 비용이 저장된 비용보다 크기 때문에 queue에 추가하지 않습니다.
Step #6
4번 노드에서 탐색을 계속합니다.
queue: (6, 8), (9, 7)
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| 0 | 3 | 4 | 4 | 2 | 1 | 9 | 4+2 |
이때 4번 노드에서 5번 노드까지 가는 비용은 6으로, 기존의 2보다 크기 때문에 queue에 추가하지 않습니다.
Step #7
8번 노드에서 탐색을 계속합니다.
queue: (7, 7), (9, 7)
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| 0 | 3 | 4 | 4 | 2 | 1 | 7 | 6 |
이때 7번 노드로 가는 비용이 원래 비용이었던 9보다 작으므로, 7번 노드의 비용을 수정해줍니다.
Step #8
7번 노드에서 탐색을 계속합니다. 그러나, 7번 노드에 연결되어있는 8번 노드와 5번 노드까지의 비용은 7번 노드가 가지고 있는 비용인 7보다 작습니다. 따라서 연산을 수행하지 않습니다.
Step #9
9가 7번 노드의 비용 7보다 크므로 연산을 수행하지 않습니다.
탐색 완료
이제 1번 노드에서 모든 노드까지의 비용이 다 구해졌습니다. 처음 구하려고 했던 것은, 1번 노드에서 7번 노드까지의 비용이였으므로, 배열에서 7번 노드의 값을 가져오면, 그것이 최단 거리입니다.
다익스트라 알고리즘은 DP와 같이 이전까지의 최소비용을 구하는 알고리즘입니다. 그리고, 현재 상황에서 가장 가중치가 낮은 노드를 찾는다는 점에서 그리디 알고리즘이라고 볼 수도 있습니다.
코드(BOJ 1916)
import sys
from collections import deque
import heapq
input = sys.stdin.readline
n = int(input())
m = int(input())
table = {i: [] for i in range(1, n+1)}
costs = [10**9] * n # costs 배열 초기화
for _ in range(m):
x, y, z = map(int, input().split())
table[x].append([y, z]) # 노드와 간선, 가중치 표현
start, end = map(int, input().split())
costs[start-1] = 0 # 시작 노드 0
queue = [(0, start)]
def dijkstra(): # 다익스트라
while queue:
cost, node = heapq.heappop(queue)
if cost > costs[node-1]: # 만약 노드 비용이 현재 비용보다 더 크다면
continue
if node in table:
for next_node, weight in table[node]:
if weight + cost < costs[next_node-1]: # 더 작은 값일 경우 queue 에 넣고 배열 수정
costs[next_node-1] = weight + cost
heapq.heappush(queue, (costs[next_node-1], next_node))
dijkstra()
print(costs[end-1])
