
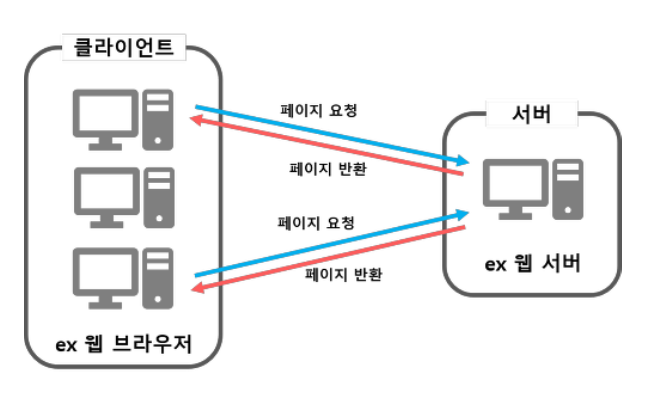
클라이언트-서버 통신
- 클라이언트: 브라우저(크롬, IE 등)를 의미하며, 코드 수정 및 접근이 가능함
- 서버: 웹 서버나 데이터베이스 서버를 의미하며, 클라이언트가 코드 수정 및 접근을 할 수 없음
- 클라이언트와 서버는 HTTP라는 통신 규약을 통해 페이지 요청(Request)과 응답(Response)을 주고받음
HTTP와 HTTPS
- HTTP (Hyper Text Transfer Protocol): 웹에서 정보를 주고받는 통신 규약
- HTTPS (HTTP over Secure Socket): SSL 또는 TLS 프로토콜을 사용해 데이터를 암호화하여 주고받는 더 안전한 통신 규약
- HTTP로 시작하는 URL은 HTTP를 사용하며, HTTPS로 시작하는 URL은 데이터를 암호화하여 전송함
SSL/TLS
- SSL (Secure Socket Layer)
- IETF(국제 인터넷 표준화 기구)에서 명칭을 표준화하여 TLS(Transport Layer Security)라고도 부름
- 개인키(Private Key)와 공개키(Public Key)를 이용해 데이터를 암호화함
- 인증기관(Certificate Authority, CA)이라는 제3자를 통해 원격 컴퓨터의 신원을 확인함
- TLS (Transport Layer Security)
- SSL과 동일한 개념임
- HTTPS는 HTTP에 SSL이나 TLS 프로토콜을 더해 데이터를 암호화하여 통신함
HTTP 요청 방식 및 상태 코드
- GET: URL 뒤에 데이터를 붙여서 전송하는 방식임. 데이터가 노출되고 전송량에 제한이 있음
- POST: 데이터를 HTTP Body에 담아 전달하는 방식임. GET보다 안전하며 데이터가 노출되지 않아 로그인, 게시물 등록 등에 사용됨
- HTTP 상태 코드 (Status Code): 서버가 요청을 처리한 결과에 대한 요약 정보를 의미함
- 2xx: 성공
- 200 OK: 요청이 성공했음을 나타냄
- 204 No Content: 요청은 성공했으나 응답 본문(Response Body)에 데이터가 없음
- 205 Reset Content: 성공 후 클라이언트의 화면을 새로고침하도록 권고함
- 206 Partial Content: 성공했으나 데이터 일부만 반환됨
- 3xx: 리다이렉션
- 클라이언트가 이전 주소로 요청하여 서버가 새로운 URL로 이동을 요청하는 경우
- 301 Moved Permanently: 요청한 자원이 새 URL에 영구적으로 존재함
- 302 Found: 301과 유사하나, 일시적인 URL을 사용함
- 303 See Other: 302와 유사하지만 GET 방식으로 새 URL에 접속해야 함
- 304 Not Modified: 요청한 자원이 변경되지 않아 클라이언트의 캐시된 자원을 사용하도록 함
- 4xx: 클라이언트 오류
- 대부분 요청한 자원이 서버에 없는 경우 발생함
- 400 Bad Request: 잘못된 요청임
- 401 Unauthorized: 권한 없이 요청함
- 403 Forbidden: 서버에서 해당 자원 접근이 금지됨
- 404 Not Found: 서버가 요청받은 리소스를 찾을 수 없음
- 405 Method Not Allowed: 허용되지 않은 요청 방식(Method)임
- 5xx: 서버 오류
- 서버에서 에러가 발생한 경우임
- 501 Not Implemented: 요청한 동작을 서버가 수행할 수 없음
- 503 Service Unavailable: 서버가 과부하 상태이거나 유지 보수 중임
Chrome 개발자 도구
- 사용법: 웹페이지에서 Fn+F12를 눌러 실행함 (mac 기준)
- Elements: HTML 코드 분석 및 수정이 가능함. 네이버 페이 포인트 값을 수정하는 것처럼 클라이언트 측의 변경이 가능함
- Network: 서버와의 통신 내역을 보여줌. HTTP 요청 방식, 상태 코드, 전송 데이터 등을 확인할 수 있음
- 기타 탭:
Console, Sources, Performance 등 다양한 분석 도구를 제공함
웹 크롤링의 기본 개념
- 웹 크롤링: 조직적이고 자동화된 방법으로 웹사이트를 탐색해 정보를 수집하는 행위임
- 웹 스크래핑: 웹 크롤링과 유사한 용어로, 원하는 데이터를 지정해 구조화해서 가져오는 것을 뜻함
- 크롤러/스파이더/파서: 웹 크롤링을 수행하는 주체들로 같은 의미로 사용됨
정적 vs 동적 웹페이지 크롤링
- 정적 웹페이지 (Static Web Page):
- 서버에 미리 저장된 HTML, 이미지, 자바스크립트 파일이 그대로 전달되는 웹페이지임
- requests 모듈을 사용해 크롤링하기 적합함
- 동적 웹페이지 (Dynamic Web Page):
- 서버에 있는 데이터가 자바스크립트에 의해 동적으로 생성되어 전달되는 웹페이지임
- 사용자는 상황이나 시간에 따라 달라지는 페이지를 보게 됨
- Selenium 모듈을 사용해 크롤링하기 적합함
파이썬 크롤링 모듈 및 활용
- Requests: HTTP 요청을 보내 HTML 코드를 읽어오는 모듈임
- BeautifulSoup: HTML 및 XML 파일에서 데이터를 쉽게 파싱하는 파이썬 라이브러리임
- find(): 특정 조건에 맞는 요소를 하나만 찾는 함수임
- find_all(): 특정 조건에 맞는 요소를 모두 찾는 함수임
- Selenium: Webdriver라는 API를 통해 브라우저를 직접 제어하는 라이브러리임. 동적 웹페이지의 콘텐츠를 불러올 때 유용함
- ChromeDriver: Selenium을 사용하려면 현재 크롬 버전에 맞는 ChromeDriver를 다운로드해야 함
- 주요 함수:
- find_element_by_id(): HTML 태그의 id 속성으로 요소를 찾음
- send_keys(): 특정 요소에 문자열을 입력함
- click(): 특정 요소를 클릭하는 이벤트를 실행함
고급 크롤링 개념
- robots.txt: 웹 크롤러 봇의 접근을 제어하기 위한 규약임. 웹사이트 최상위 경로에 위치하며,
Disallow로 크롤링 제한을 요청할 수 있음
- iframe (inline frame): HTML 문서 안에 다른 HTML 문서를 보여주는 태그임. 크롤링 시
driver.switch_to.frame() 함수를 사용해 내부로 접근해야 함
