Pandas DataFrame
저번에 하던 이야기를 계속해서 해보자
Pandas를 활용하여 다음과 같이 진행해 보려고 한다.
- 외부 resource를 이용해서 DataFrame 생성
1. CSVS 파일을 이용해서 DataFrame을 생성
2. MySQL안에 Database로 부터 SQL을 이용해 DataFrame을 생성
- 프로그램적으로 SQL을 직접 이용
- ORM방식을 이용해서 사용(Django)
- 프로그램적으로 SQL을 직접 이용하는 방법에 대해 알아보자
- 우선 외부 모듈이 필요하다
conda install pymysql# MySQL안에 데이터베이스 생성하고 제공된 Script 파일을 이용해서 Table을 생성! import pymysql import numpy as np import pandas as pd # Database 연결 # 연결을 시도해보고 만약 성공하면 연결객체를 얻어요 con = pymysql.connect(host='localhost', user='root', password='yu974346!', db='lecture0317', charset='utf8') # 연결을 성공하면 # SQL을 작성 # SELECT bisbn, btitle, bauthor, bprice From book WHERE btitle Like '%java%'' sql = "SELECT bisbn, btitle, bauthor, bprice From book WHERE btitle Like '%java%'" df =pd.read_sql(sql, con) # con이라는 연결에 대해서 sql실행해 그러고나서 dataframe 갖고와! 라는 의미 display(df)
- 다음과 같이 결과가 출력되는 것을 확인 할 수 있다

# DataFrame을 얻으면 # 이 DataFrame의 내용을 json 저장 (4가지 형태의 json 저장 가능) import pymysql import numpy as np import pandas as pd # Database 연결 # 연결을 시도해보고 만약 성공하면 연결객체를 얻어요 con = pymysql.connect(host='localhost', user='root', password='yu974346!', db='lecture0317', charset='utf8') # 연결을 성공하면 # SQL을 작성 # SELECT bisbn, btitle, bauthor, bprice From book WHERE btitle Like '%java%'' sql = "SELECT bisbn, btitle, bauthor, bprice From book WHERE btitle Like '%java%'" df =pd.read_sql(sql, con) # con이라는 연결에 대해서 sql실행해 그러고나서 dataframe 갖고와! 라는 의미 display(df) # 현재 DataFrame의 내용을 JSON파일로 저장해보자! # with 구문을 이용하고 폴더는 미리 생성되어 있어야 함! # with 구문으 이용하는 이유 # 파일을 open -> 파일안에 내용을 저장 -> 파일 close 절차순으로 짆애 # with 구문을 이용하면 close하는 부분을 우리가 코드로 작성하지 않아요! # encoding은 한글처리를 하려고 with open('./data/json/books.json', 'w', encoding='utf-8') as file: df.to_json(file, force_ascii=False) #데이터프레임이 가지고있는것을 json으로 바꿔서 file에 저장해! 라는 의미 # 뒤에 force_ascii는 걍 뒤에 사용된다고 보자# 만약 우리에게 JSON이 제공된다면 이걸 어떻게 DataFrame으로 변형할 수 있나! # JSON을 읽어들여서 DataFrame을 생성 import numpy as np import pandas as pd import json # 내장 module => 따로 설치하지 않아도 사용가능 with open('./data/json/books.json','r', encoding='utf-8') as file: dict_books = json.load(file) print(dict_books) # from_dict() 딕셔너리로부터 데이터 프레임을 만들 수 있음 df = pd.DataFrame.from_dict(dict_books) # display(df){'bisbn': {'0': '89-7914-371-0', '1': '89-7914-397-4', '2': '978-89-6848-042-3', '3': '978-89-6848-132-1', '4': '978-89-6848-147-5', '5': '978-89-6848-156-7', '6': '978-89-7914-582-3', '7': '978-89-7914-659-2', '8': '978-89-7914-832-9', '9': '978-89-7914-855-8', '10': '978-89-98756-79-6', '11': '978-89-98756-89-5'}, 'btitle': {'0': 'Head First Java: 뇌 회로를 자극하는 자바 학습법(개정판)', '1': '뇌를 자극하는 Java 프로그래밍', '2': '모던 웹을 위한 JavaScript + jQuery 입문(개정판) : 자바스크립트에서 제이쿼리, 제이쿼리 모바일까지 한 권으로 끝낸다', '3': 'JavaScript+jQuery 정복 : 보고, 이해하고, 바로 쓰는 자바스크립트 공략집', '4': '이것이 자바다 : 신용권의 Java 프로그래밍 정복', '5': 'Head First JavaScript Programming : 게임과 퍼즐로 배우는 자바스크립트 입문서', '6': 'Head First JavaScript : 대화형 웹 애플리케이션의 시작', '7': 'UML과 JAVA로 배우는 객체지향 CBD 실전 프로젝트 : 도서 관리 시스템', '8': 'IT CookBook, 웹 프로그래밍 입문 : XHTML, CSS2, JavaScript', '9': '자바스크립트 성능 최적화: High Performance JavaScript', '10': 'IT CookBook, Java for Beginner', '11': 'IT CookBook, 인터넷 프로그래밍 입문: HTML, CSS, JavaScript'}, 'bauthor': {'0': '케이시 시에라,버트 베이츠', '1': '김윤명', '2': '윤인성', '3': '김상형', '4': '신용권', '5': '에릭 프리먼, 엘리자베스 롭슨', '6': '마이클 모리슨', '7': '채흥석', '8': '김형철, 안치현', '9': '니콜라스 자카스', '10': '황희정, 강운구', '11': '주성례(저자), 정선호(저자), 한민형(저자), 권원상'}, 'bprice': {'0': 28000, '1': 27000, '2': 32000, '3': 28000, '4': 30000, '5': 36000, '6': 28000, '7': 40000, '8': 23000, '9': 20000, '10': 23000, '11': 22000}}
- 다음과 같이 결과가 출력된다.
# DataFrame 생성 # 외부 resource를 이용한 DataFrame 생성 # CSV파일, Database이용, JSON파일에 DataFrame을 저장 JSON파일로부터 DataFrame 생성 # Open API를 이용해서 DataFrame을 생성해 보아요! > 영화진흥 위원회 PEN API import numpy as np import pandas as pd import urllib # open api 호출하기 위해서 필요한 module import json # 영화진흥위원회 OPEN API 호출에 대한 URL을 Query String을 이용해서 작성 # key : 74a66d13424d80d8f869a5824??????? # url : http://www.kobis.or.kr/kobisopenapi/webservice/rest/boxoffice/searchDailyBoxOfficeList.json # Query String : ?key =키값&targetDt=날짜 # ==> Query string : ?key=74a66d13424d80d8f869a5824???????&targetDt=20220301 url = 'http://www.kobis.or.kr/kobisopenapi/webservice/rest/boxoffice/searchDailyBoxOfficeList.json' query_string ='?key=74a66d13424d80d8f869a5824???????&targetDt=20220301' movie_url = url + query_string # url을 만들었으면 open api호출의 위한모듈을 사용한다 load_page = urllib.request.urlopen(movie_url) # 어떤url을 통해 request를 보낼건지 print(load_page) # request에 대한 response 객체(이 안에 결과 JSON이 들어 있어요!) # 결과 JSON을 얻으려면 my_dict =json.loads(load_page.read()) print(my_dict) # open api 호출 결과(json)를 dictionary로 얻어냈어요! # 이 dictionary를 잘 분해해서 DataFrame으로 만들어야 해요! # 나름 로직을 만들어서 DataFrame으로 만들어야 해요!
- 데이터프레임 직접 생성해보기
import numpy as np import pandas as pd my_dict = {'이름' : ['홍길동', '아이유', '김연아', '신사임당'], '학과' : ['철학', '수학', '컴퓨터', '국어국문'], '학년' : [1, 3, 2, 4], '학점' : [1.4, 2.7, 3.5, 2.9]} df = pd.DataFrame(my_dict, columns = ['학과', '이름', '학점', '학년'], index = ['one','two','three','four']) display(df)결과 학과 이름 학점 학년 one 철학 홍길동 1.4 1 two 수학 아이유 2.7 3 three 컴퓨터 김연아 3.5 2 four 국어국문 신사임당 2.9 4
- 데이터프레임 인덱싱과 슬라이싱
- 예제 1
# 이렇게 DataFrame을 생성한 후 # indexing과 slicing을 할 줄 알아야 해요! # 복잡해요! import numpy as np import pandas as pd my_dict = {'이름' : ['홍길동', '아이유', '김연아', '신사임당'], '학과' : ['철학', '수학', '컴퓨터', '국어국문'], '학년' : [1, 3, 2, 4], '학점' : [1.4, 2.7, 3.5, 2.9]} df = pd.DataFrame(my_dict, columns = ['학과', '이름', '학점', '학년'], index = ['one','two','three','four']) display(df) # 학과 이름 학점 학년 # one 철학 홍길동 1.4 1 # two 수학 아이유 2.7 3 # three 컴퓨터 김연아 3.5 2 # four 국어국문 신사임당 2.9 4 # 1. 하나의 컬럼을 추출하려면 어떻게 해야 하나요? print(df['이름']) # 결관s Series # one 홍길동 # two 아이유 # three 김연아 # four 신사임당 # Name: 이름, dtype: object # 2. 이렇게 하나의 column을 추출하면 view로 추출되요! my_name = df['이름'] print(my_name) # one 홍길동 # two 아이유 # three 김연아 # four 신사임당 # Name: 이름, dtype: object my_name['one'] = '강감찬' print(my_name) # one 강감찬 # two 아이유 # three 김연아 # four 신사임당 # Name: 이름, dtype: object display(df) # 원본 데이터 프레임이 바뀜 # 그렇게 때문에 주의하라고 경고창이 뜸 # 학과 이름 학점 학년 # one 철학 강감찬 1.4 1 # two 수학 아이유 2.7 3 # three 컴퓨터 김연아 3.5 2 # four 국어국문 신사임당 2.9 4
- 예제 2
import numpy as np import pandas as pd my_dict = {'이름' : ['홍길동', '아이유', '김연아', '신사임당'], '학과' : ['철학', '수학', '컴퓨터', '국어국문'], '학년' : [1, 3, 2, 4], '학점' : [1.4, 2.7, 3.5, 2.9]} df = pd.DataFrame(my_dict, columns = ['학과', '이름', '학점', '학년'], index = ['one','two','three','four']) display(df) # 학과 이름 학점 학년 # one 철학 홍길동 1.4 1 # two 수학 아이유 2.7 3 # three 컴퓨터 김연아 3.5 2 # four 국어국문 신사임당 2.9 4 # 3. 비 연속적인 두개 이상의 column을 추출해보자! 이름과 학년 # => fancy indexing display(df[['이름', '학년']]) # 결과는 DataFrame # 이름 학년 # one 홍길동 1 # two 아이유 3 # three 김연아 2 # four 신사임당 4
- 예제 3
import numpy as np import pandas as pd my_dict = {'이름' : ['홍길동', '아이유', '김연아', '신사임당'], '학과' : ['철학', '수학', '컴퓨터', '국어국문'], '학년' : [1, 3, 2, 4], '학점' : [1.4, 2.7, 3.5, 2.9]} df = pd.DataFrame(my_dict, columns = ['학과', '이름', '학점', '학년'], index = ['one','two','three','four']) display(df) # 학과 이름 학점 학년 # one 철학 홍길동 1.4 1 # two 수학 아이유 2.7 3 # three 컴퓨터 김연아 3.5 2 # four 국어국문 신사임당 2.9 4 # 4. 특정 컬럼의 값을 수정 # df['학년'] = 1 # broadcasting 발생 # 학과 이름 학점 학년 # one 철학 홍길동 1.4 1 # two 수학 아이유 2.7 1 # three 컴퓨터 김연아 3.5 1 # four 국어국문 신사임당 2.9 1 # 원하는 값으로 채울려면? df['학년'] = [2, 3, 4, 4] # 리스트 형태로 줘서 넣어주면 된다 display(df) # 학과 이름 학점 학년 # one 철학 홍길동 1.4 2 # two 수학 아이유 2.7 3 # three 컴퓨터 김연아 3.5 4 # four 국어국문 신사임당 2.9 4
- 예제 4
import numpy as np import pandas as pd my_dict = {'이름' : ['홍길동', '아이유', '김연아', '신사임당'], '학과' : ['철학', '수학', '컴퓨터', '국어국문'], '학년' : [1, 3, 2, 4], '학점' : [1.4, 2.7, 3.5, 2.9]} df = pd.DataFrame(my_dict, columns = ['학과', '이름', '학점', '학년'], index = ['one','two','three','four']) display(df) # 5. 새로운 컬럼을 추가! 나이 column을 추가 # df['나이'] = [20, 22, 30, 25] # 나이라는 컬럼을 새롭게 만들고 붙이면 된다. # display(df) # 학과 이름 학점 학년 나이 # one 철학 홍길동 1.4 1 20 # two 수학 아이유 2.7 3 22 # three 컴퓨터 김연아 3.5 2 30 # four 국어국문 신사임당 2.9 4 25 # 6. 연산을 통해서 새로운 컬럼을 추가할 수 있어요! # 모든 사람의 학점을 20% 증가시켜서 '조정학점' 컬럼으로 저장 df['조정학점'] = df['학점'] * 1.2 display(df) # 학과 이름 학점 학년 나이 조정학점 # one 철학 홍길동 1.4 1 20 1.68 # two 수학 아이유 2.7 3 22 3.24 # three 컴퓨터 김연아 3.5 2 30 4.20 # four 국어국문 신사임당 2.9 4 25 3.48
- 예제 5
import numpy as np import pandas as pd my_dict = {'이름' : ['홍길동', '아이유', '김연아', '신사임당'], '학과' : ['철학', '수학', '컴퓨터', '국어국문'], '학년' : [1, 3, 2, 4], '학점' : [1.4, 2.7, 3.5, 2.9]} df = pd.DataFrame(my_dict, columns = ['학과', '이름', '학점', '학년'], index = ['one','two','three','four']) display(df) # 학과 이름 학점 학년 # one 철학 홍길동 1.4 2 # two 수학 아이유 2.7 3 # three 컴퓨터 김연아 3.5 4 # four 국어국문 신사임당 2.9 4 # 7. 원하는 column을 삭제하려면? # 함수가 있다. drop() # drop()은 행을 삭제하거나 열을 삭제할 때 사용 new_df = df.drop('학점', axis = 1, inplace =False) # 괄호 안에 컬럼명을 넣어주면 된다! 컬럼인지 index인지 알려줘야한다. display(new_df) # 학과 이름 학년 # one 철학 홍길동 1 # two 수학 아이유 3 # three 컴퓨터 김연아 2 # four 국어국문 신사임당 4 ### 여기까지가 DataFrame column에 대한 생성, 수정 , 삭제, 추출에 대한 내용!
- DataFrame의 Row indexing
# 이번에는 row indexing에 대해서 알아보아요! import numpy as np import pandas as pd my_dict = {'이름' : ['홍길동', '아이유', '김연아', '신사임당'], '학과' : ['철학', '수학', '컴퓨터', '국어국문'], '학년' : [1, 3, 2, 4], '학점' : [1.4, 2.7, 3.5, 2.9]} df = pd.DataFrame(my_dict, columns = ['학과', '이름', '학점', '학년'], index = ['one','two','three','four']) display(df) # 학과 이름 학점 학년 # one 철학 홍길동 1.4 1 # two 수학 아이유 2.7 3 # three 컴퓨터 김연아 3.5 2 # four 국어국문 신사임당 2.9 4 # column indexing # df['이름'] # Series # print(df['이름':'학년']) # 될거라 생각했는데 에러가남! 즉 컬럼에 대한 slicing은 안되요! # display(df[['학과', '이름', '학년']]) # 가능 결과는 DataFrame으로 나와요! # 학과 이름 학년 # one 철학 홍길동 1 # two 수학 아이유 3 # three 컴퓨터 김연아 2 # four 국어국문 신사임당 4 # row indexing(숫자 index를 이용) # pirnt(df[0]) # Error 숫자 인덱스로는 단일 indexing이 안되요! # display(df[0:2]) # 슬라이싱은 가능, slicing한 결과는 당연히 dataFrame, view # 학과 이름 학점 학년 # one 철학 홍길동 1.4 1 # two 수학 아이유 2.7 3 # display(df[[0, 2]]) # Fancy indexing 안되요! # row indexing(지정 index를 이용) # print(df['one']) # one이라는 컬럼을 뜯어와 라는 의미 Error ( 단일 indexing이 안됨) # display(df['one':'three']) # 슬라이싱은 가능 , slicing한 결과는 당연히 DataFrame # 학과 이름 학점 학년 # one 철학 홍길동 1.4 1 # two 수학 아이유 2.7 3 # three 컴퓨터 김연아 3.5 2 # display(df['one', three]) # # Fancy indexing 안되요! # df [] => row indexing은 이렇게 하지마세요! # => column indexing할때만 이렇게 하세여! # df.loc[] = > row indxing과 column indexig을 둘다 사용할 수 있어요!
- DataFrame의 loc에 대해 알아보자!
# df.loc에 대해서 알아보아요 # df.loc[]는 행과 열에 대한 indexing 할 수 있음 # 단, loc를 이용할 때는 숫자 index는 사용할 수 없어요! 지정 index만 사용이가능 import numpy as np import pandas as pd my_dict = {'이름' : ['홍길동', '아이유', '김연아', '신사임당'], '학과' : ['철학', '수학', '컴퓨터', '국어국문'], '학년' : [1, 3, 2, 4], '학점' : [1.4, 2.7, 3.5, 2.9]} df = pd.DataFrame(my_dict, columns = ['학과', '이름', '학점', '학년'], index = ['one','two','three','four']) display(df) # print(df.loc['one']) # 성공, Series로 결과가 return. 단일 row 추출가능 # 학과 철학 # 이름 홍길동 # 학점 1.4 # 학년 1 # Name: one, dtype: object # print(df.loc[0]) # Error loc는 숫자 index를 사용할 수 없어요! display(df.iloc[0]) # 앞에 i가 붙으면 지정인덱스는 못쓰지만 숫자 인덱스는 쓸 수 있음! # 학과 철학 # 이름 홍길동 # 학점 1.4 # 학년 1 # Name: one, dtype: object # display(df.loc['one':'three']) # ok DataFrame으로 결과가 return # 학과 이름 학점 학년 # one 철학 홍길동 1.4 1 # two 수학 아이유 2.7 3 # three 컴퓨터 김연아 3.5 2 # display(df.loc[['one','three']]) # or Datarframe으로 결과가 return Fancy indexing # 학과 이름 학점 학년 # one 철학 홍길동 1.4 1 # three 컴퓨터 김연아 3.5 2 # loc, iloc # loc는 지정인덱스 iloc는 숫자 인덱스 하지만 구조는 같다 # 이런걸 조심하도록 하자! # df.loc['one':-1] # loc는 숫자 인덱스를 못씀 그래서 -1을 넣어서 slicing하는건 불가!
- 좀 더 알아보도록 하자
- 예제 2
import numpy as np import pandas as pd my_dict = {'이름' : ['홍길동', '아이유', '김연아', '신사임당'], '학과' : ['철학', '수학', '컴퓨터', '국어국문'], '학년' : [1, 3, 2, 4], '학점' : [1.4, 2.7, 3.5, 2.9]} df = pd.DataFrame(my_dict, columns = ['학과', '이름', '학점', '학년'], index = ['one','two','three','four']) display(df) # 학과 이름 학점 학년 # one 철학 홍길동 1.4 1 # two 수학 아이유 2.7 3 # three 컴퓨터 김연아 3.5 2 # four 국어국문 신사임당 2.9 4 # loc를 이용해서 row indexing과 column indexing을 같이 할 수 있어요! # display(df.loc['two':'three']) # ok row slicing # 학과 이름 학점 학년 # two 수학 아이유 2.7 3 # three 컴퓨터 김연아 3.5 2 # df.loc['two':'three','학과':'이름'] # ok # 학과 이름 # two 수학 아이유 # three 컴퓨터 김연아 # print(df.loc['two':'three','이름']) # ok 결과는 Series # two 아이유 # three 김연아 # Name: 이름, dtype: object # df.loc['two':'three',['이름','학년']] # 이름 학년 # two 아이유 3 # three 김연아 2
- 예제3
import numpy as np import pandas as pd my_dict = {'이름' : ['홍길동', '아이유', '김연아', '신사임당'], '학과' : ['철학', '수학', '컴퓨터', '국어국문'], '학년' : [1, 3, 2, 4], '학점' : [1.4, 2.7, 3.5, 2.9]} df = pd.DataFrame(my_dict, columns = ['학과', '이름', '학점', '학년'], index = ['one','two','three','four']) display(df) # 학과 이름 학점 학년 # one 철학 홍길동 1.4 1 # two 수학 아이유 2.7 3 # three 컴퓨터 김연아 3.5 2 # four 국어국문 신사임당 2.9 4 # 학점이 3.0 이상인 학생의 학과와 이름을 출력하세요! df['학점']>= 3.0 # one False # two False # three True # four False # Name: 학점, dtype: bool # df.loc[행, 열] df.loc[df['학점']>= 3.0,['학과','이름']] # 학과 이름 # three 컴퓨터 김연아
- 예제 4
import numpy as np import pandas as pd my_dict = {'이름' : ['홍길동', '아이유', '김연아', '신사임당'], '학과' : ['철학', '수학', '컴퓨터', '국어국문'], '학년' : [1, 3, 2, 4], '학점' : [1.4, 2.7, 3.5, 2.9]} df = pd.DataFrame(my_dict, columns = ['학과', '이름', '학점', '학년'], index = ['one','two','three','four']) display(df) # 학과 이름 학점 학년 # one 철학 홍길동 1.4 1 # two 수학 아이유 2.7 3 # three 컴퓨터 김연아 3.5 2 # four 국어국문 신사임당 2.9 4 # 새로운 row를 추가해 보아요! # df.loc['five',:] = ['영어영문', '강감찬', 3.7, 1] # 값이 두개나오면 행과 열인데 하나만 나오면 행 # display(df) # 학과 이름 학점 학년 # one 철학 홍길동 1.4 1.0 # two 수학 아이유 2.7 3.0 # three 컴퓨터 김연아 3.5 2.0 # four 국어국문 신사임당 2.9 4.0 # five 영어영문 강감찬 3.7 1.0 # df.loc['five',['학과','이름']] = ['물리학과','강감찬'] # display(df) # 학과와 이름에만 값을 줬기 때문에 NaN이라는 값으로 채워짐! # 학과 이름 학점 학년 # one 철학 홍길동 1.4 1.0 # two 수학 아이유 2.7 3.0 # three 컴퓨터 김연아 3.5 2.0 # four 국어국문 신사임당 2.9 4.0 # five 영어영문 강감찬 NaN NaN # NaN(Not a Number) : 결치 값(값이 없는 것을 나타내는 의미) # NaN은 실수로 간주 컬럼들은 같은타입의 시리즈이기 때문에 학년 값이 실수값으로 출력되는것을 볼 수 있다
- 예제 5
import numpy as np import pandas as pd my_dict = {'이름' : ['홍길동', '아이유', '김연아', '신사임당'], '학과' : ['철학', '수학', '컴퓨터', '국어국문'], '학년' : [1, 3, 2, 4], '학점' : [1.4, 2.7, 3.5, 2.9]} df = pd.DataFrame(my_dict, columns = ['학과', '이름', '학점', '학년'], index = ['one','two','three','four']) display(df) # row를 삭제해 보아요! (axis=0이면 행을 삭제 axis =1이면 열을 삭제) new_df =df.drop('three', axis=0, inplace=False) display(new_df) # 학과 이름 학점 학년 # one 철학 홍길동 1.4 1 # two 수학 아이유 2.7 3 # four 국어국문 신사임당 2.9 4
여기까지가 dataframe의 row, column indexing에 대한 내용이에요!!
그 다음에는 dataframe이 제공하는 함수(기능)들을 살펴봐야 해요!
- 데이터 셋을 받아서 활용해보자
UCL Machone Learning Repository 에서 제공하는
MPG(Mile per Gallon) => 자동차 연비에 관련된 데이터 셋import numpy as np import pandas as pd df = pd.read_csv('./data/auto-mpg.csv', header =None) # header = None은 컬럼명이 없다를 명시 # mpg : 연비(mile per gallon) # cylinders : 실린더 개수 # displacement : 배기량 # horsepower : 마력(출력) # weight : 중량 # acceleration : 가속능력 # year : 출시년도 (70 => 1970년도) # origin : 제조국 (1: USA, 2: EU, 3: JPN) # name : 차량이름 df.columns = ['mpg', 'cylinders','displacement','horsepower', 'weight', 'acceleration', 'year', 'origin', 'name'] display(df)
DataFrame의 함수
1. head(), tail()
# DataFrame안의 데이터 앞에서 5개(기본), 뒤에서 5개(기본)를 추출 display(df.head()) # 상위 5개의 행만 확인(기본값) display(df.tail()) # 하위 5개의 행만 확인(기본값) #두개다 ()안에 숫자를 넣어주면 그 갯수만큼 조회
- 상위 하위 5개의 데이터를 출력하는 것을 확인 할 수 있다!
2. shape
print(df.shape) # (398, 9)
- 행과 열의 개수를 확인할 수 있다.
3. info() : DataFrame의 기본 정보를 알려줘요!
print(df.info())결과 <class 'pandas.core.frame.DataFrame'> RangeIndex: 398 entries, 0 to 397 Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 mpg 398 non-null float64 1 cylinders 398 non-null int64 2 displacement 398 non-null float64 3 horsepower 398 non-null object 4 weight 398 non-null float64 5 acceleration 398 non-null float64 6 year 398 non-null int64 7 origin 398 non-null int64 8 name 398 non-null object dtypes: float64(4), int64(3), object(2) memory usage: 28.1+ KB None
- 다음과 같이 해당 컬럼들의 컬럼명 속성 데이터 개수 데이터 타입을 확인 할 수 있다.'
4. count() : 유효한 값의 개수 (NaN이 아닌 값의 개수)
print(df.count()) # Series로 결과가 return결과 mpg 398 cylinders 398 displacement 398 horsepower 398 weight 398 acceleration 398 year 398 origin 398 name 398 dtype: int64
- 각 컬럼의 데이터의 개수를 계산하여 알려준다 NaN값 제외
5. value_counts() : Series에 대해서 unique value의 개수를 알려줘요!
- 일단 origin이라는 컬럼은 제조국을 나타내고 1, 2, 3중 하나의 값을 가져요!
- 1: USA, 2: EU, 3: JPN 의미
df['origin'].value_counts() # Series로 결과가 return되요!결과 1 249 3 79 2 70 Name: origin, dtype: int64
- 해당 컬럼에 대해서 중복되는 값들에 대하여 그 값을 기준으로 카운트 해준다!
- 만약 NaN값이 있으면 value_counts()는 어떻게 동작하나?
- 기본적으로 NaN을 포함해서 계산, 만약 옵션을 주면 NaN을 제외하고 수행할 수 있다!
print(df['origin'].value_counts(dropna=False)) # NaN 포함시켜서 계산 True이면 NaN을 제외하고 계산
6. unique() : Series에 대해서 중복해서 유일한 값이 어떤값이 있는지 알려줌!
df['year'].unique()결과 array([70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82], dtype=int64)다음과 같이 중복된 유일한 값들을 출력해준다!
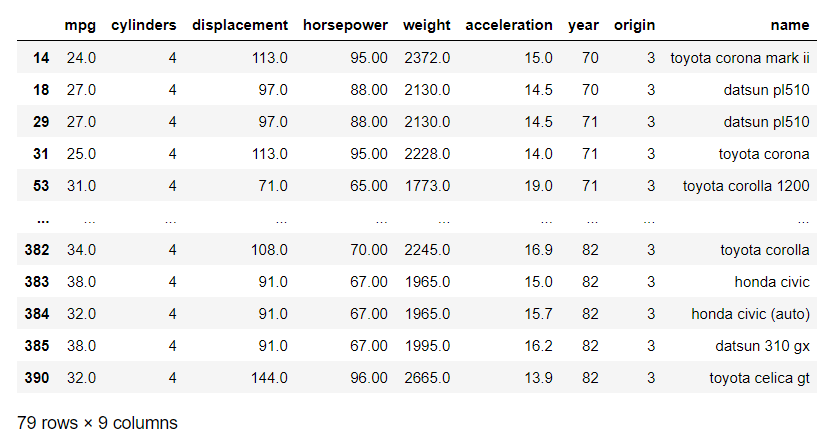
7. isin() : boolean mask를 만들기 위해서 많이 사용
df['origin'].isin([3]) # 제조국이 일본(3)인 mask # 0 False # 1 False # 2 False # 3 False # 4 False # ... # 393 False # 394 False # 395 False # 396 False # 397 False # Name: origin, Length: 398, dtype: bool # 마스크를 통해 제조국이 3인 컬럼만 True 3이 아닌 컬럼은 False로 떨어진다 df.loc[df['origin'].isin([3]),:] # boolean indexing # Dataframe의 'origin'컬럼중에서 제조국이 3인 항목에 대해 열을 전부다 뽑아라!
- 다음과 같이 제조국이 3(일본)인 항목의 열들만 출력해서 보여준다!
DataFrame의 데이터 정렬!
- 예제를 통해 알아보도록 하겠다
# 정렬(DataFrame 안의 데이터를 정렬해보아요!) import numpy as np import pandas as pd # 난수의 재현성을 확보하기 위해 seed를 주어 랜덤으로 나오는 값을 고정시킴 np.random.seed(1) df = pd.DataFrame(np.random.randint(0, 10, (6,4)), columns = ['A', 'B', 'C', 'D'], index=pd.date_range('20220101', periods=6)) # 판다스가 제공해주는 날짜 인덱스 periods 는 간격 1부터 6까지 display(df) # 결과 A B C D 2022-01-01 5 8 9 5 2022-01-02 0 0 1 7 2022-01-03 6 9 2 4 2022-01-04 5 2 4 2 2022-01-05 4 7 7 9 2022-01-06 1 7 0 6 # index를 랜덤하게 섞을꺼에요! # np.random.shuffle(df.index) # shuffle()은 원본데이터를 변경하는 특징 / 이렇게 작성시 오류가 난다. # DataFrme의 index는 mutable operation을 지원하지 않아요! # => 쉽게 말하면 index 자체를 변경 시킬 수 없어요! # 그럼 어떻게하나요? # 다른함수가 있어요! np.random.permutation() # 이 함수는 섞어서 원본을 변경하지 않고 복사본을 만들어요! # random_index = np.random.permutation(df.index) print(random_index) # 결과 ['2022-01-03T00:00:00.000000000' '2022-01-01T00:00:00.000000000' '2022-01-04T00:00:00.000000000' '2022-01-05T00:00:00.000000000' '2022-01-02T00:00:00.000000000' '2022-01-06T00:00:00.000000000'] # 이렇게 변경된 index로 DataFrame을 재설정 해야해요! df2 = df.reindex(index=random_index, # reindex 인덱스를 재설정 하는 메서드 columns=['B', 'A', 'D', 'C']) display(df2) # 결과 B A D C 2022-01-03 9 6 4 2 2022-01-01 8 5 5 9 2022-01-04 2 5 2 4 2022-01-05 7 4 9 7 2022-01-02 0 0 7 1 2022-01-06 7 1 6 0 # 이제 정렬을 한번 해 보아요! # index를 기반으로 한 정렬 # value를 기반으로 한 정렬 # index 기반 정렬 display(df2.sort_index(axis=1, ascending=True)) # ascending =True 오름차순 정렬 # 컬럼정렬 axis=1 이기 때문에 컬럼 기준으로 정렬 되는 것을 알 수 있다. # 결과 A B C D 2022-01-03 6 9 2 4 2022-01-01 5 8 9 5 2022-01-04 5 2 4 2 2022-01-05 4 7 7 9 2022-01-02 0 0 1 7 2022-01-06 1 7 0 6 display(df2.sort_index(axis=0, ascending=True)) # ascending =True 오름차순 정렬 # 행 정렬 axis=0이기 때문에 행을 기준으로 정렬 시키는 것을 볼 수 있다. # 결과 B A D C 2022-01-01 8 5 5 9 2022-01-02 0 0 7 1 2022-01-03 9 6 4 2 2022-01-04 2 5 2 4 2022-01-05 7 4 9 7 2022-01-06 7 1 6 0 # Value 기반 정렬 display(df2.sort_values(by='B', ascending=True)) # ascending =True 오름차순 정렬 # 특정 컬럼의 값으로 행을 정렬 # 결과 B라는 특정 컬럼을 기준으로 오름차순 정렬이 된것을 확인 할 수 있다! B A D C 2022-01-02 0 0 7 1 2022-01-04 2 5 2 4 2022-01-05 7 4 9 7 2022-01-06 7 1 6 0 2022-01-01 8 5 5 9 2022-01-03 9 6 4 2
여기까지가 Pandas의 DataFrame의 기본 함수였다 좀 더 공부해야 할 부분이 많기 때문에 추가적으로 공부를 해보자!

초보개발자