lms 9번의 데이터클리닝 연습
사용한 데이터셋
penguins.csv
연습을 위해 몇가지 데이터를 수정 후 사용했다
데이터셋 준비
모듈 불러오기
import pandas as pd import numpy as np import matplotlib.pyplot as plt
import os csv_file_path = os.getenv('USERPROFILE')+'/aiffel/data_preprocess/data/penguins.csv' pg = pd.read_csv(csv_file_path) pg
이 부분에서 많이 헤멨었는데,
클라우드 주피터가 불안정해서 로컬 주피터를 돌리려다보니
환경변수 설정을 제대로 몰라서 한참 검색했다
'HOME' 부분을 'USERPROFILE'로 바꾼 후 제대로 동작함을 확인.
결측치
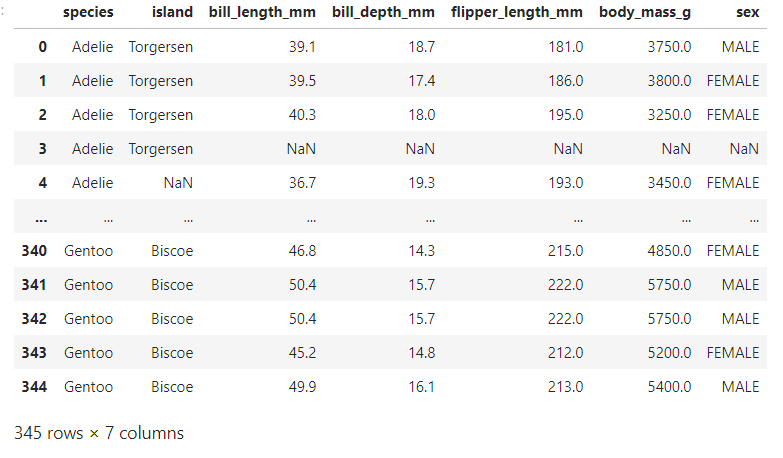
print('전체 데이터 건수:', len(pg))
print('컬럼별 결측치 개수') len(pg) - pg.count()
여기서 성별정보 컬럼을 삭제할까 잠시 고민함
pg.isnull()
결측치이면 True, 아니면 False 반환
pg.isnull().any(axis=1)
해당 행에 하나라도 결측치가 있다면 True 반환
pg[pg.isnull().any(axis=1)]
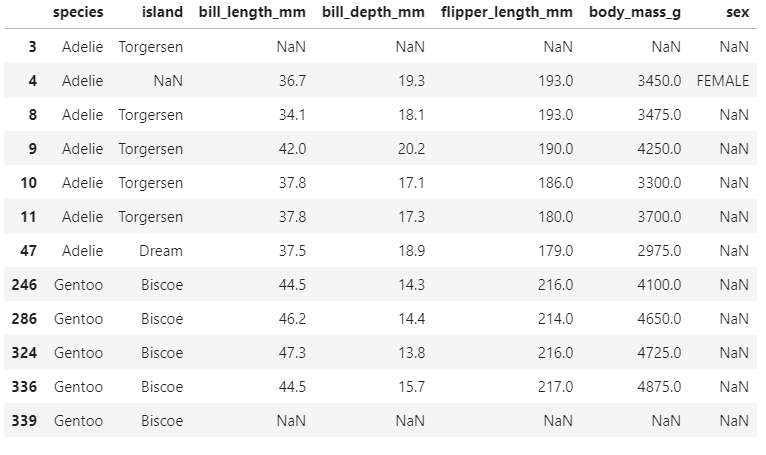
하나라도 True인 행만 따로 출력.
3, 339는 전부 결측치이므로 제거해야하고
성별 정보는 따로 예측해서 넣을 수 있는 값이 아니므로
그냥 성별 컬럼을 날리기로 결정
pg = pg.drop('sex', axis=1) pg.head()
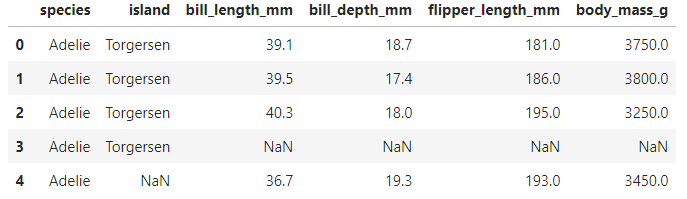
성별컬럼 삭제 확인
pg.dropna(how='all', subset=['bill_length_mm', 'bill_depth_mm', 'flipper_length_mm', 'body_mass_g'], inplace=True) pg[pg.isnull().any(axis=1)]

정보가 모두 결측치인 행 삭제 확인
4번이 섬 정보가 결측. 앞 뒤의 정보를 토대로 추측해서 집어넣자
pg.loc[[2,4,5]]
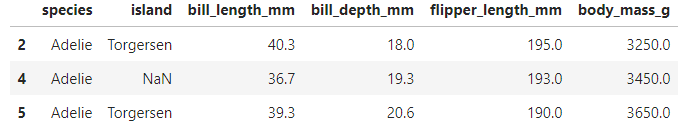
4의 앞 뒤 행을 가져오려다 계속 오류가 남
이전 과정에서 3을 지웠다는 걸 깨닫고 2 4 5 행 출력
pg.loc[4, 'island'] = 'Torgersen' pg.loc[[4]]

2행과 5행의 정보로 채움
중복된 데이터
pg[pg.duplicated()]
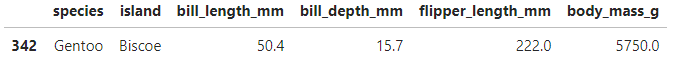
342 행이 중복데이터로 검색됨
pg[(pg['body_mass_g']==5750.0)]

species와 island 같은걸로 검색하면 너무 많이 나올 것 같아서
body_mass_g 로 중복 자료 검색
pg.drop_duplicates(inplace=True) pg
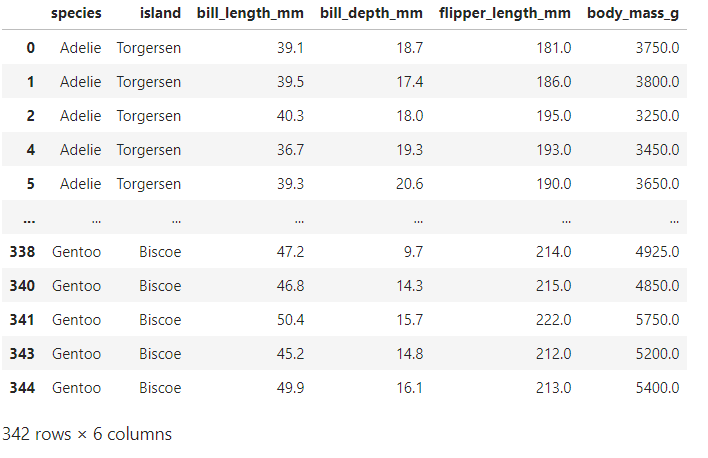
중복 제거 후 남은 데이터 342개
이상치
z-score method
def outlier(df, col, z): return df[abs(df[col] - np.mean(df[col]))/np.std(df[col]) > z].index pg.loc[outlier(pg,'body_mass_g', 2)]
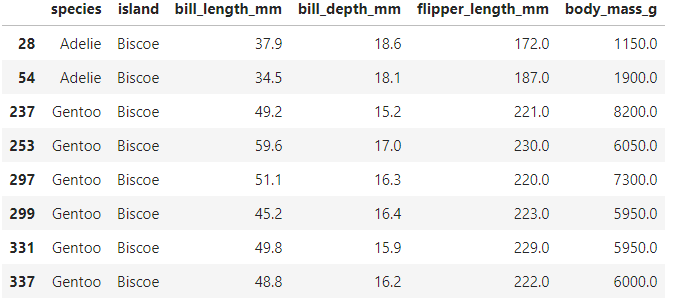
이상치 리턴 함수를 만들어서 적당한 값의 z=2를 선택
def not_outlier(df, col, z): return df[abs(df[col] - np.mean(df[col]))/np.std(df[col]) <= z].index pg.loc[not_outlier(pg, 'body_mass_g', 2)]
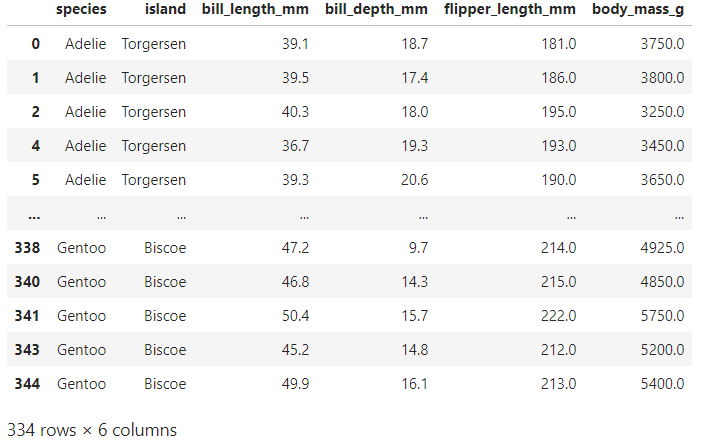
이상치가 아닌 데이터만 리턴하는 함수 만들기
이전 342개에서 이상치 8개 제거된 334개 리턴
IQP method
def outlier2(df, col): q1 = df[col].quantile(0.25) q2 = df[col].quantile(0.5) q3 = df[col].quantile(0.75) iqr = q3 - q1 print('{}의 중앙값: {}'.format(col.split('_')[0]+' '+col.split('_')[1], q2)) return df[(df[col] < q1 - 1.5 * iqr)|(df[col] > q3 + 1.5 * iqr)]
IQP 메서드로 이상치 찾는 함수 만들기
중앙값 출력에 문자열 포매팅 응용해봄
outlier2(pg, 'bill_length_mm')

부리가 긴 펭귄 1마리 발견
outlier2(pg, 'bill_depth_mm')

부리 깊이 깊은 펭귄 1마리, 얕은 펭귄 1마리
outlier2(pg, 'flipper_length_mm')

팔 길이는 수정하는 걸 빼먹었는지 이상치 없음
outlier2(pg, 'body_mass_g')
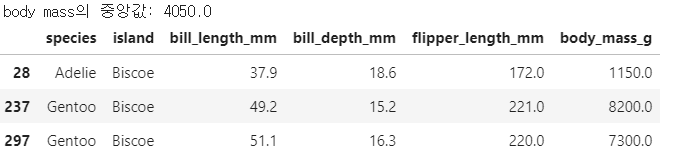
영양실조 1마리, 뚱땡이 2마리 발견
정규화
Standardization
cols = ['bill_length_mm', 'bill_depth_mm', 'flipper_length_mm', 'body_mass_g'] pg_Z = (pg[cols] - pg[cols].mean()) / pg[cols].std() pg_Z
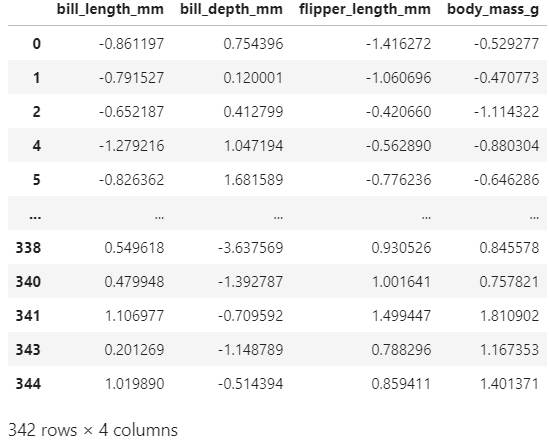
표준화 작업
pg_Z.describe()
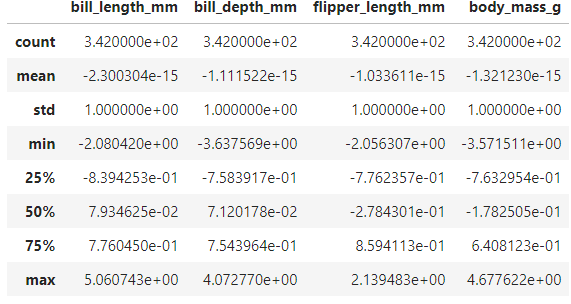
평균이 0, 표준편차가 1인 표준정규분포 형태임을 확인
Min-Max Scaling
pg[cols] = (pg[cols] - pg[cols].min()) / (pg[cols].max() - pg[cols].min()) pg
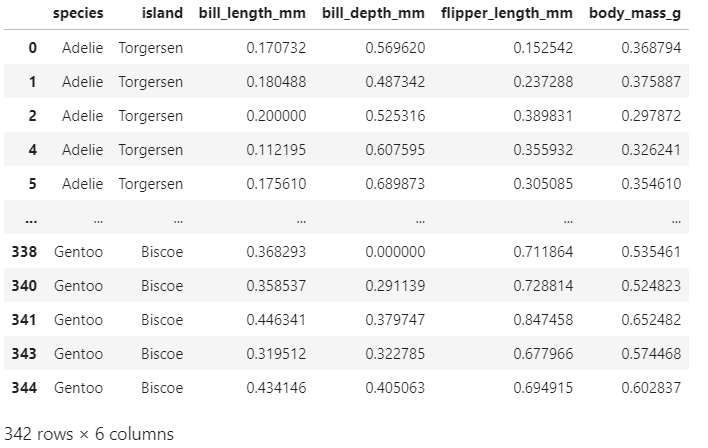
변량에서 최솟값을 뺀 값을, 최대값과 최소값의 차로 나눠줌
pg.describe()
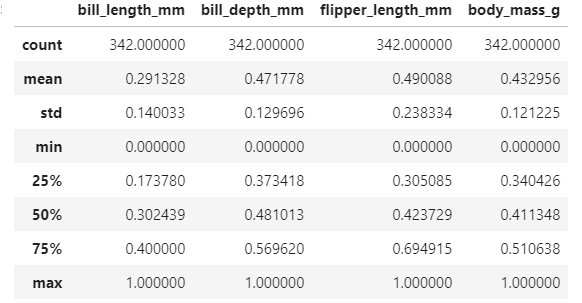
최소는 0, 최대는 1인 형태
원-핫 인코딩
print(pg['island']) island = pd.get_dummies(pg['island']) island
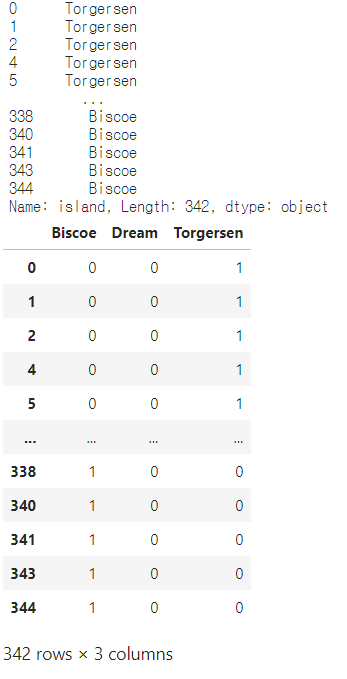
lms의 예제와는 달리 데이터가 정렬되어 있어서
일부 화면만으로는 잘 보이지 않음
해당하는 값에 1, 나머지는 0을 배정하는 형태
pg = pd.concat([pg, island], axis=1) pg.drop(['island'], axis = 1, inplace = True) pg
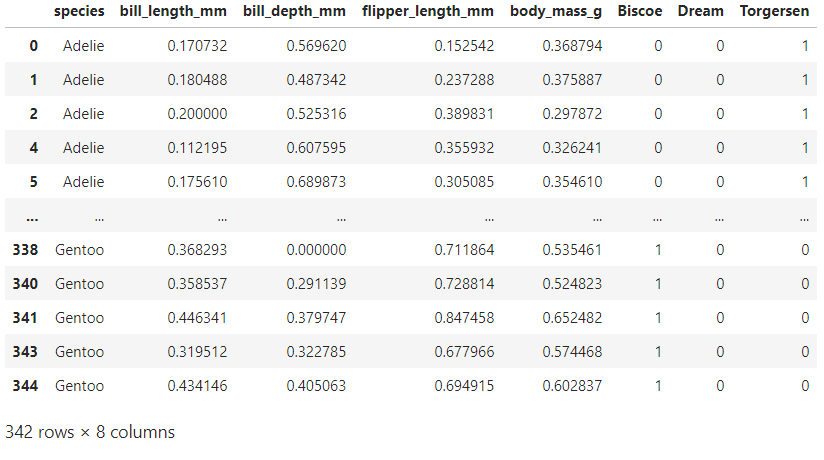
새로 만든 열을 추가하고 필요없어진 섬 칼럼은 삭제
구간화 하기에는 적당하지 않은 데이터셋인 것 같아서 일단 여기서 마무리
