2026.04.17
🧠 오늘 배운 것
인증(Authentication)
“누구세요?”
사용자가 누구인지 확인하는 절차. (시스템에 등록된 사용자인지를 증명하는 과정)
- 아이디와 비밀번호를 입력해서 로그인하는 것.
- 스마트폰 잠금을 지문이나 얼굴 인식으로 해제하는 것.
인증 = 로그인
인가(Authorization)
“뭘 할 수 있나요?”
인증된 사용자가 특정 리소스나 기능에 접근 할 수 있는 권한이 있는지 확인하는 절차. (무엇을 할 수 있는지 허가해주는 과정)
- 일반 사용자는 게시글을 읽고 작성성 할 수 있다면, 관리자는 다른 사용자의 게시글을 삭제할 수 있는 것.
- 유료 구독자만 프리미엄 콘텐츠를 볼 수 있는 것.
인가 = 권한
세션(Session)
서버가 사용자의 로그인 상태를 기억하는 방식. (전통적으로 많이 사용되는 방식)
동작 흐름
- 사용자 로그인
- 세션 정보 생성 및 저장 : 서버는 로그인 정보가 유효하면, 사용자를 위한 세션 ID를 생성하고 이 정보를 서버 메모리나 데이터베이스에 저장.
- 세션 ID전송 : 서버는 생성된 세션 ID를 클라이언트에게 보내고, 클라이언트는 이 ID를 쿠키에 저장.
- 요청과 검증 : 이후 클라이언트는 서버에 요청을 보낼 때마다 쿠키에 담긴 세션 ID를 함께 보내고, 서버는 이 세션 ID를 받아 저장된 세션 정보와 비교하여 사용자를 식별하고 요청을 처리.
장점
서버에서 모든 세션 정보를 관리하기 때문에 보안에 유리. (특정 사용자를 강제로 로그아웃 시키는 등 제어가 쉬움.)
쿠키에 세션 ID만 저장하기 때문에 클라이언트에 민감한 정보가 남지 않음.
단점
사용자가 많아질수록 서버의 메모리나 DB 부하가 커짐. (→ 확장성 문제)
JWT(Json Web Token)
서버가 로그인 상태를 저장하지 않는(stateless) 인증 방식.
서버가 상태를 저장하지 않기 때문에 JWT 자체에 모든 인증 정보가 담겨 있음.
동작 흐름
- 사용자 로그인
- 토큰 생성 및 전송 : 서버는 로그인 정보가 유효하면, 사용자의 정보과 권한, 만료 시간 등을 담을 암호화된 토큰(Access Token)을 생성해서 클라이언트에게 보냄. 그리고 서버는 이 토큰을 저장하지 않음.
- 토큰 저장 : 클라이언트는 전달받은 토큰을 쿠키에 저장.
- 요청과 검증 : 이후 클라이언트는 서버에 요청을 보낼 때마다 HTTP헤더(쿠키 포함)에 토큰을 같이 보냄. 서버는 이 토큰의 서명을 검증해서 유효성을 확인하고 요청을 처리.
장점
무상태(Stateless) 및 확장성, 서버가 토큰을 저장하지 않기 때문에 서버의 부하가 줄고, 여러 서버로 확장하기 용이 (서버가 토큰을 저장하지 않아도 유저를 식별할 수 있는 이유는, JWT 자체에 모든 인증 정보가 담겨있기 때문)
웹 뿐만 아니라 모바일 앱 등 다양한 클라이언트 환경에서 사용하기 편리함.
단점
토큰이 탈취되면 만료될 때까지 악용될 수 있음.
세션 ID보다 토큰의 크기가 더 큼.
HTTP 복습
HTTP 구조는 크게 Start Line, Header, Body로 구성되있음.
Strat Line : 요청 종류(GET, POST 등) / 응답의 성공 여부(200 OK, 404 Not Found)
Header : 보내는 사람, 받는 사람, 내용물의 종류 등 필요한 각종 설정과 데이터
Body : HTML 문서, 이미지 파일, JSON 데이터 등
HTTP의 특징
무상태성(Stateless) : 매 요청마다 HTTP 요청 스스로가 자신이 누군지 밝혀야만 로그인 상태가 유지됨.
HTTP Header
Key : Value 의 형태로 여러정보들이 구성되어있음. (예를 들면, name : hello)
Body 로는 핵심 데이터를 주고 받고, Header 로는 인증 관련 데이터를 주고 받음.
인증을 위한 Session Key나 JWT를 Header에 넣어서 주고 받으면, Body의 데이터와 확실히 분리해서 핵심 데이터와 인증 데이터를 구분해서 사용할 수 있음.
HTTP Cookie
쿠키는 Key값이 Cookie 혹은 Set-Cookie 인 헤더. (쿠키의 Value는 그 안에 Key=Value 형태로 존재, 구분은 ;를 사용)
즉, Cookie는 여러개의 값을 가질 수 있음.
쿠키는 Client에서 요청을 보낼 때랑 Server에서 응답을 보낼 때의 형식이 다름.
Client 요청 : Key 이름이 Cookie
Server 응답 : Key 이름이 Set-Cookie
Set-Cookie 특별한 보안 3가지 (Server → Client)
- Secure : 쿠기가 HTTPS 통신일 때만 서버로 전송하도록 강제 - 암호화되지 않은 HTTP 연결에서 쿠키가 탈취되는 것을 막음.
- HttpOnly : 자바스크립트가 쿠키에 접근하는 것을 막음 - 악성 스크립트가 쿠키를 훔쳐가는 것을 막음.
- SameSite : 다른 도메인에서 요청을 보낼 때 쿠키 전송 여부를 결정 - 사용자가 의도하지 않은 요청에 쿠키가 자동으로 설려 가는 것을 막음.
Session
세션 인증은 서버가 사용자의 로그인 상태를 기억하고 관리하는 방식.
핵심 특징 : Stateful(상태 유지) - 서버가 사용자의 상태(로그인 정보)를 계속해서 저장하고 유지.
로그인을 하면 서버는 무작위의 유니크한 Session ID(=Session Key)를 생성해서 키 값으로 로그인 정보를 저장하고, Session ID를 클라이언트에게 반환.
클라이언트는 요청 시 Session ID를 헤더(or 쿠키)에 넣어서 서버에 요청하면, 서버는 Session ID를 키로 유저를 식별.
JWT
인증에 필요한 정보들을 암호화시킨 JSON 객체를 사용해서 인증을 처리하는 방식
서버가 사용자를 기억하는것이 아니라, 사용자가 자신의 신분증을 들고 다니는 것과 같음.
핵심 특징 : Stateless(무상태) - 모든 정보가 JWT에 들어있기 때문에 서버는 로그인 상태를 기억하지 않아도 됨.
JWT를 한단어로(한마디로) 정의하면? Stateless(무상태) ⭐️
로그인을 하면 서버는 JWT에 생성해서 이것을 클라이언트에게 반환.
클라이언트는 요청 시 JWT를 헤더(or 쿠키)에 넣어서 서버에 요청하면, 서버는 JWT에 담겨있는 정보로 유저를 식별.
JWT의 구성 요소
aaaa.bbbb.cccc 처럼 . 으로 구분된 세 부분으로 구성.
Header : JSON - 토큰 유형, 서명(Signature)을 생성할 때 사용할 정보가 담겨있음. (Base64Url 방식으로 인코딩)
Payload : JSON - 토큰에 담을 실제 정보(클레임)이 들어있음. (Base64Url 방식으로 인코딩)
📌클레임(Claim) : 사용자의 정보(이름, 아이디, 권한 등)나 토큰의 속성(만료 시간, 발급자 등)
인코딩은 절대 암호화가 아님. 디코딩하면 다 확인 할 수 있음.
Signature : JWT의 무결성을 보장하는 가장 중요한 부분. (Header와 Payload를 인코딩한 값과 비밀키(Secret Key)를 합쳐서 헤더에 암호화해서 값을 다시 만듦.)
Refrest Token
새로운 Access Token을 발급받기 위해 사용하는 토큰으로, Access Token이 만료되었을 때만 사용. (JWT가 Access Token을 사용하고 있음.)
보통 데이터베이스와 같은 안전한 곳에 저장해서 관리.
ArgumentResolver
컨트롤러(Controller)의 메서드 파라미터에 들어오는 데이터를 자도응로 처리하고 바인딩(binding)해주는 도구.
@RequestParam @RequestBody @PathVariable 등의 어노테이션 기능들이 ArgumentResolver
ArgumentResolver 구현
HandlerMethodArgumentResolver인터페이스 구현 - 2개의 핵심 메서드 정의supportsParameter()메소드 구현(언제 실행할지 결정) - ArgumentResolver의 실행 조건을 정의resolverArgument()메소드 구현(무엇을 만들어줄지 결정) - 파라미터에 실제로 주입될 값을 만들어서 반환하는 로직 작성WevMvcConfigurer에 등록 -ArgumentResolver를 스프링이 인식하고 사용할 수 있도록 설정 파일에 등록
HttpServletRequest
HTTP 요청 메시지 전체를 담고 있는 그릇. (클라이언트가 서버로 보내는 모든 정보가 담겨있음.)
@RequestHeader
@RequestHeader 어노테이션을 사용하면 HttpServletRequest 객체를 가져오지 않고도 특정 헤더 값을 파라미터로 직접 받아올 수 있음. (코드가 간결하고 의도가 명확해짐.)
@SessionAttribute와 HttpSession을 활용한 세션 관리
@RequestHeader 를 사용해서 Session ID를 가져올 순 있지만,
“Session ID만 가져올 수 있으면 좋겠다!”
라고 생각할 수 있음. 그리고 그걸 할 수 있게 해주는게 @SessionAttribute
복습
트랜잭션 : 여러 작업을 하나의 단위로 묶어서 모두 성공하거나 모두 실패하게 하는 것. (원자성)
영속성 컨텍스트 : 트랜잭션 내에서 데이터베이스를 한 번이라도 갔다 온 엔티티를 관리 (@Transactional)
영속성 컨텍스트
엔티티를 영속적으로 저장하는 환경
JPA는 영속성 컨텍스트에서 엔티티들을 관리하다가, 작업이 끝나면(트랜잭션이 끝나면) 최종 결과물만 DB에 반영
1차 캐시
영속성 컨텍스트는 일종의 Map 형태의 캐시 저장소를 갖고 있음.(엔티티가 영속성 컨텍스트의 1차 캐시에 저장)
1차 캐시를 확인하고, 동일한 ID의 엔티티가 있으면 DB를 조회하지 않고 바로 반환
동일성(Identity) 보장
1차 캐시 덕분에, 같은 트랜잭션 안에서 같은 ID로 조회한 엔티티는 항상 동일한 메모리 주소의 인스턴스 보장
이렇게 불필요한 DB 조회를 줄여서 성능을 향상시킬 수 있음.
변경 감지(Dirty Checking)
트랜잭션이 커밋되기 직전에 영속성 컨텍스트에 1차 캐시에 있는 모든 엔티티의 최초 상태랑 현재 상태를 비교해서 다르면, JPA는 변경된 내용을 감지하고 자동으로 DB에 반영
이 과정을 변경 감지(Dirty Cheking)
쓰기 지연(Transectional Write-Behind)
save() 메서드가 호출되면 DB에 저장하기 위해서 1차 캐시에 차곡차곡 쌓아두고, 트랜잭션이 커밋되는 순간, JPA는 모아뒀던 모든 데이터들을 한 번에 DB로 보냄.(이 과정을 Flush)
EntityManager
EntityManager가 영속성 컨텍스트에서 Entity를 가지고 들어온 요청을 처리하기 위해 일을 함.
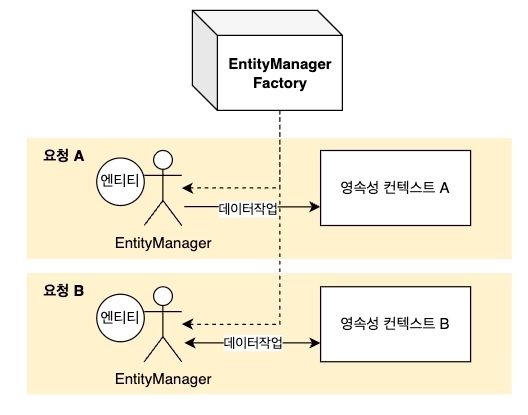
트랜잭션 전파(Transcation Propagation)
REQUIRED(Default) : 부모 트랜잭션이 있으면, 그 트랜잭션에 참여 (없으면 새로운 트랜잭션을 생성)REQUIRES_NEW: 무조건 새로운 트랜잭션을 생성 (반드시 기록되어야하는 부가 기능에 사용됨. 실패해도 실패했다라는 로그를 DB에 남겨야함.)NESTED: 부모 트랜잭션이 있으면 중첩, 없으면 새로운 트랜잭션 생성 (하나의 작업 중, 실패할 가능성이 있는 부분을 따로 분리하여 예외처리를 하고 싶을 때 사용)SUPPORTS: 부모 트랜잭션이 있으면 참여, 없으면 트랜잭션 없이 그냥 실행 (읽기 전용 메서드에서 사용)NOT_SUPPORTED: 항상 트랜잭션 없이 실행 (트랜잭션과 전혀 관련 없는 특정 로직을 수행할 때 사용. 실무에선 사용 안함.)MANDATORY: 부모 트랜잭션이 반드시 있어야함. 없으면 예외 발생 (독립적으로 사용되서는 안 되고, 반드시 어떤 트랜잭션의 일부로서만 동작해야하는 메서드임을 강제하고 싶을 때 사용. 설계적 안정장치)NEVER: 트랜잭션이 없는 상태에서만 실행됨. 있으면 예외 발생 (트랜잭션이 걸려있으면 오히려 문제가 되는 특성 메서드에 사용)
트랜잭션 격리 수준(Transaction Isolation Level)
동시에 실행되는 여러 트랜잭션들이 서로 어느 정도까지 격리되어 실행될지를 결정하는 데이터베이스 설정
- READ UNCOMMITTED 트랜잭션에서의 변경내용이 COMMIT이나 ROLLBACK 여부에 상관 없이 다른 트랜잭션에서 값을 읽을 수 있음. 정합성에 문제가 많아서 권장하지 않음.
- READ COMMITTED COMMIT이 된 데이터만 읽음. RDB에서 대부분 기본적으로 사용되고 있는 격리 수준
- REPEATABLE READ 자신의 트랜잭션이 생성되기 이전의 트랜잭션에서 COMMIT이 된 데이터만 읽음. MySQL의 default 격리 수준
- SERIALIZABLE 가장 엄격한 격리 수준 데이터를 접근할 때, 항상 Lock을 걸고 데이터를 조회 성능 문제로 데이터베이스에서 거의 사용되지 않음.
| 격리 수준 | Dirty Read | Non-Repeatable Read | Phantom Read |
|---|---|---|---|
| READ UNCOMMITTED | ✅ 발생 | ✅ 발생 | ✅ 발생 |
| READ COMMITTED | ❌ | ✅ 발생 | ✅ 발생 |
| REPEATABLE READ | ❌ | ❌ | ✅ 발생 |
| SERIALIZABLE | ❌ | ❌ | ❌ |
연관관계
엔티티 - 테이블 간의 관계
Primary Key(기본키)
테이블에 있는 각 행(row)을 유일하게 식별할 수 있는 고유한 값
| 특징 | 설명 | 예시 |
|---|---|---|
| 유일성 | 테이블 내 모든 행은 서로 다른 키 값을 가져야 한다. | 주민등록번호 |
| NOT NULL | 기본 키 값은 절대 비어있을 수 없다. | 주민등록번호가 없는 대한민국 사람은 없다. |
| 불변성 | 기본 키 값은 변경되면 안 된다. | 주민등록번호가 바뀌면 안 된다. |
Foreign Key(외래키)
한 테이블의 컬럼이 다른 테이블의 기본 키를 참조하는 것 (테이블 간의 관계를 맺어주는 연결고리 역할)
| 특징 | 설명 | 예시 |
|---|---|---|
| 관계 설정 | 외래 키는 두 테이블을 연결하여 의미 있는 데이터 관계를 만든다. | Team과 Member는 관계가 있다. |
| 중복 허용 | 외래 키 값은 기본 키와 달리 중복될 수 있다. | 하나의 Team은 여러 명의 Member를 가질 수 있다. |
| NULL 허용 | 외래 키 값은 비어 있을 수 있다. | Team이 없는 Member가 있을 수 있다. |
단방향
한 쪽 객체에서만 다른 쪽 객체를 참조할 수 있는 관계
양방향
양 쪽 객체가 서로를 참조하는 관계
연관관계의 주인
단방향 관계에서는 연관관계의 주인은 경우의 수가 하나밖에 없음.
양방향 관계에서는 두 객체가 서로를 참조함.
이때 JPA는 둘 중 누가 DB의 외래키(FK)를 관리할지를 정해야하는데, 이 관리 권한을 가진 쪽을 연관관계의 주인
주인의 규칙 : 외래키(FK)를 가진 테이블과 매핑된 엔티티가 주인
주인이 아닌 쪽 : MappedBy 속성을 사용해서 “나는 주인이 아니며, 주인의 어떤 필드와 연결되어 있는지”를 명시함.(DB에 반영되지 않고, 오직 조회만 가능함.)
@ManyToOne 이 있는 쪽이 연관관계의 주인!
❌ 어려웠던 점
ArgumentResolver 구현에서 튜터님은 쉽죠?라고 하지만 전혀 쉽지 않다. 영어 울렁증이 심해서 그냥 아무것도 모르겠다.
트랜잭션 전파는 어떻게 이해해보겠는데, 격리 수준은 뭘 나타내고자 하는 건지 이해가 어렵다.
⚒️ 해결 방법
근데 또 과제 진행하면 어떻게든 이해를 하긴 하더라…
