Deadlock

이화여자대학교 반효경 교수님의 2014년 Operating System 강의를 시청한 후 정리한 내용이다.
http://kocw.net/home/cview.do?cid=3646706b4347ef09
Resource
시스템에서 자원(Resource)는 CPU, Memory, I/O Deviece 등의 하드웨어 자원과 커널에서 추상적으로 정의하여 관리하는 소프트웨어 자원으로 나뉜다. 프로세스가 자원을 사용할 때는 Request, Allocate, Use, Release순으로 사용한다.
Deadlock
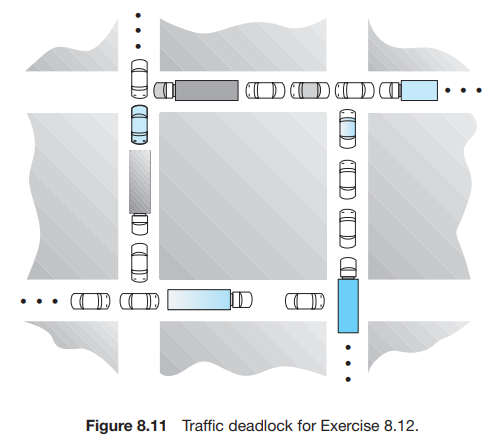
여러 프로세스가 서로의 자원을 필요로 하여, 결국 자원을 얻지 못해 무한히 block 상태가 되는 것을 Deadlock(교착상태)이라 한다. 아래 두 가지 상황은 Deadlock의 예시이다.
- 2개의 tape drive를 2개의 프로세스가 각자 가지고 있으면서, 상대의 tape drive 자원을 요청하고 기다리는 상황
- binary semaphore A, B에 대해, P1{P(A); P(B);}, P2{P(B); P(A);}
4 Conditions to Arise Deadlock
아래 Deadlock 발생 4가지 조건을 모두 만족해야만 Deadlock이 발생한다.
- Mutual Exclusion: 임의의 프로세스가 자원에 접근할 때 다른 프로세스들은 해당 자원에 접근할 수 없으므로 Deadlock이 발생할 수 있다. 만약 다수의 프로세스들이 자원에 동시 접근이 가능하다면 Deadlock이 발생할 일은 없을 것이다.
- No Preemption: 임의의 프로세스가 특정 자원을 할당받을 경우, 해당 자원을 다 사용하고 반납하기 전까지는 빼앗기지 않는다.
- Hold and Wait (보유 대기): 자원을 가지고 있는 프로세스가 다른 프로세스가 갖고 있는 자원을 기다릴 때, 자신이 할당 받고 있는 자원은 내놓지 않는다.
- Circular Wait (순환 대기): 여러 프로세스가 서로의 자원을 요구하여 Cycle을 형성한 상황이다. 예를 들어, N개의 프로세스가 존재할 때 P0은 P1이 갖고 있는 자원을 요구하고, P1은 P2의... PN은 P0의 자원을 요청하고 대기한 상황이다.
Resource-Allocation Graph
어떤 자원들이 어느 프로세스들에게 할당되고 요청되는지 그래프로 표현한 것을 자원할당그래프(Resource-Allocation Graph)라고 한다. 그래프에서 Vertex는 프로세스와 자원을, 프로세스를 가리키는 방향의 Edge는 자원의 할당을, 자원을 가리키는 방향의 Edge는 자원의 요청을 표현한 것이다. 이 자원할당그래프를 통해 Deadlock 발생 여부를 판단할 수 있다.
- 그래프 내에 Cycle이 없으면, Deadlock이 아니다.
- 그래프 내에 Cycle이 있고, 각 자원 당 인스턴스(박스 내에 점)가 1개이면 Deadlock이다.
- 그래프 내에 Cycle이 있고, 각 자원 당 인스턴스가 여러 개라면 Deadlock 가능성이 있다.
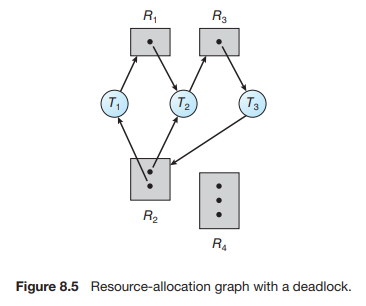
위 자원할당그래프에서, 자원 R2를 할당받은 스레드 T1은 T2가 할당 받은 자원 R1을 요청하고 있으면서, T2는 T3가 할당받은 자원 R3을 요청하고 있다. 또한 R3은 T1과 T2가 할당받은 자원을 요청중이다. 이 그래프에서 T1→R1→T2→R3→T3→R2→T1, T2→R3→T3→R2 사이클이 형성되었으므로, Deadlock이 발생한 것을 알 수 있다.
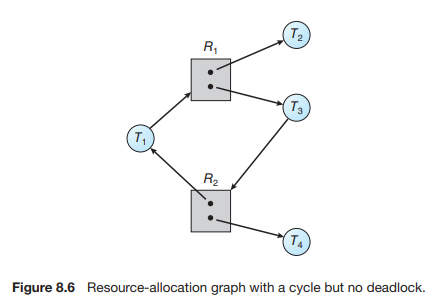
그러나 이 그래프에서는 Deadlock이 발생하지 않았다. 분명 T1→R1→T3→R2→T1 사이클이 존재하지만, R1과 R2의 인스턴스가 2개씩 존재하고, 만약 T2와 T4가 작업을 마치고 자원을 반납하면 T1와 T3는 각각 R1과 R2를 얻을 수 있기 때문이다.
Methods for Handling Deadlocks
- Deadlok Prevention: Deadlock의 4가지 발생 조건 중 하나를 만족하지 못하도록 한다.
- Deadlock Avoidance: 프로세스마다 자원의 할당, 필요 정보를 통해 Deadlock이 발생할 가능성이 없는 경우에만 자원을 할당하도록 한다.
- Deadlock Detection and Recovery: Deadlock이 발생하면 delection 루틴을 이용하여 발생 Deadlock 발생 이전으로 rollback한다.
- Deadlock Ingnorance: Deadlock을 시스템에서 책임지지 않고, 사용자가 직접 프로세스를 종료함으로써 해결하도록 두는 방식이다. 현재 UNIX를 포함한 대부분의 OS가 채택하고 있는 방식이다.
Handling Method #1: Deadlock Prevetion
Deadlock 발생 조건 중 하나를 만족하지 못하도록 관리한다.
- Mutual Exclusion: 임의의 프로세스가 공유 불가능한 자원을 쓸 경우 반드시 성립해야 한다.
No Preemption: 임의의 프로세스가 자원을 요청할 때, 해당 프로세스가 보유한 자원이 Preempt되도록 한다. 이 구현은 Preempt되기 전 State를 저장하고 복구할 수 있는 자원(CPU, Memory)에서 사용된다.
Hold and Wait (보유 대기): 임의의 프로세스가 자원을 요청한 시점에서 할당 받고 있는 자원이 없어야 한다. 이는 처음부터 프로세스가 생성될 때 실행에 필요한 모든 자원들을 전부 할당함으로써 해당 프로세스가 자원을 요청하는 경우를 배제하거나, 자원 요청 시 가지고 있던 자원을 반납함으로써 이 조건을 만족하지 못하게 할 수 있다.
Circular Wait (순환 대기): 자원에 할당 순서를 부여하여 프로세스들이 자원을 할당할 때 정해진 순서대로 할당 받도록 한다. 만약 3번째 할당 순서인 자원 Ri을 보유한 프로세스가 첫 번째 할당 순서인 자원 Rj을 요청하면, 갖고 있는 Ri를 반납해야 Rj를 할당받을 수 있다.
이 방법은 원천적으로 Deadlock을 막을 수 있지만, 발생 확률이 매우 낮은 Deadlock에 대비하여 이렇게 자원 할당에 제약을 걸게 되면, 정상적으로 동작하는 상황에서도 자원을 효율적으로 사용하지 못하고, 성능이 떨어질 수 있으며, Starvation이 발생할 수 있다.
Handling Method #2: Deadlock Avoidance
프로세스가 종료되기 전까지 필요한 자원 정보와 할당 정보, 그리고 가용 자원 정보를 이용하여 요청한 자원을 할당할 경우 deadlock이 발생하는지 검사하여 안전한 경우 할당하는 방법이다. 프로세스의 자원 관련 부가정보를 필요로 하므로, 프로세스가 실행하는 동안 필요한 자원의 최대 사용량을 미리 선언하는 것이 일반적인 모델이다. 이 방법은 자원의 인스턴스의 개수에 따라 2가지 방식으로 나뉜다.
- 각 자원의 인스턴스 수가 1개일 경우: Resource-Allocation Graph 사용
- 각 자원의 인스턴스 수가 2개 이상일 경우: Banker's Algorithm 사용
Deadlock Avoidance: Resource-Allocation Graph (for Single Instance of Resource Types)
각 자원의 인스턴스 수가 1개일 경우에는 자원할당그래프를 사용하여 deadlock 발생 여부를 확인한다. 아래 그림은 T2가 T1이 할당받은 R1을 요청한 상황이다. 이 그림에서 점선은 프로그램 실행 시 최소한 1번 이상 요청하는 자원을 의미한다. 즉, T1과 T2는 종료 직전까지 무조건 R2를 요청하게 되어있다. 앞서 기술했지만, Deadlock Avoidance 방법은 프로세스가 사용할 자원의 최대 사용량을 미리 선언하여 deadlock 발생 가능성을 확인한다.
그래프를 그려서 해결하는 방식은 테이블을 이용하는 방식의 subset이므로, 후에 기술할 Banker's Algorithm처럼 테이블을 이용해도 무방하다.
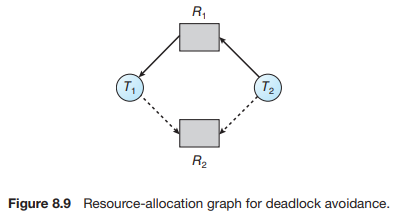
이 상황에서 만약 T2가 R2를 요청하고 이를 수락하여 할당했다면 아래와 같은 상황이 전개된다.
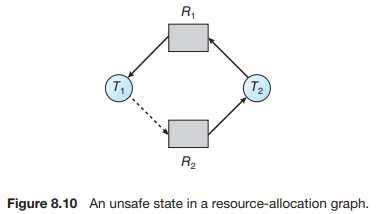
결국 T2는 T1이 스레드를 실행하며서 언젠가 요청할 자원 R2를 할당받아, 점선을 포함하여 cycle이 형성되었다. 물론 이 상황 자체는 deadlock이 아닌데, 그 이유는 T1이 R1을 반납한다면 해당 자원을 요청했던 T2가 할당받을 수 있기 때문이다. 그러나 T1이 R2를 요청한다면 deadlock이 발생하므로, 결국 이 상황은 deadlock에 unsafe한 state라고 볼 수 있다.
따라서 이 방법에서는 deadlock의 발생 가능성이 있는 unsafe state가 되지 않도록 T2에게 R2를 할당하지 않도록 하는데, 자원을 할당했을 때 cycle이 생긴다면 할당하지 않는다. 반대로 기술하면 자원 할당을 가정했을 때 cycle이 생기지 않는다면 자원을 할당하는 것이다.
Deadlock Avoidance: Banker's Algorithm (for Multiple Instances of Resource Types)
Banker's Algorithm은 자원의 인스턴스 수가 여러 개일 때 사용하는 알고리즘으로, 각 프로세스마다 자원의 최대 사용량을 미리 파악하여 특정 자원을 요청한 프로세스의 상태를 보고 할당할지를 결정한다.
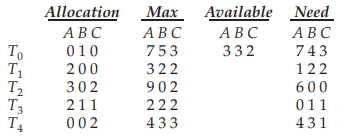
위 테이블에서는 가용 자원의 인스턴스 수는 A=3, B=3, C=2이다. 그리고 T1의 자원 할당량은 A=2, B=0, C=0이고, 스레드가 실행하면서 사용하는 자원의 최대 사용량은 A=3, B=2, C=2이며 앞으로 종료되기 전까지 필요한 자원의 인스턴스 수는 A=1, B=2, C=2이다.
위 테이블은 자원 A, B, C의 인스턴스가 각각 10, 5, 7개일 경우 가용 자원의 인스턴스 수(Available)와 스레드 T0~T4의 자원 할당량(Allocation)/최대 사용량(Max)/현재 시점에서 종료 전까지의 필요량(Need) 정보를 나타낸 것이다. 이때 현 시점에서 종료 전까지의 자원 필요량(Need)은 자원 최대 사용량(Max)에서 할당량(Allocation)을 뺀 것이다.
이 상황에서 T1이 자원 A 1개와 C 2개를 요청하면, 가용 자원에서 A, C 모두 요청한 인스턴스 수보다 많으므로 할당 가능하다. 하지만 바로 할당하지 않고, 요청한 스레드 T1의 필요량(A=1, B=2, C=2)이 현재 가용 자원(A=3, B=3, C=2)으로 커버할 수 있는지 확인한다. 만약 필요량이 현재 가용 자원으로 만족된다면 T1이 요청한 자원(A=1, B=0, C=2)만큼이 아니라 해당 스레드의 필요량(A=1, B=2, C=2)를 할당한다. 이로써 스레드가 나중에 추가적인 자원을 요청할 때 deadlock이 발생하지 않도록 막을 수 있다.
그러나 만약 T0가 자원 B 2개를 요청했다고 하면, 물론 가용 자원에서 B의 인스턴스 수가 3개이므로 당장은 할당 가능하다. 그러나 T0의 현재에서 종료 시점까지 필요한 자원(A=7, B=4, C=3)량은 가용 자원(A=3, B=3, C=2)량으로 충족되지 않으므로 할당하지 않는다. 이는 추후에 T0가 가용 자원보다 더 많은 자원을 요청하여 deadlock이 발생할 것을 막는 것이다. T0는 후에 다른 스레드가 종료하면서 반납했을 때 증가한 가용 자원량으로 조건을 충족한다면 할당받을 수 있다.
이 규칙으로 자원을 할당/반납하게 되면, T1이 먼저 할당받고, 이 스레드가 반납하여 증가한 가용 자원으로 T3가 할당 받고...를 반복하면 sequence <T1, T3, T4, T2, T0>가 형성되는데, 이러한 sequence가 존재한다면 safe state라고 한다. 이때 sequence<P1, P2, ..., Pn>가 safe하려면 1≤j<i≤n 인 i, j에 대하여, 가용 자원+Pj≤Pi 를 만족해야 한다. 즉, Pj가 자원을 반납하면 그것이 가용 자원이 되므로, 증가한 가용 자원이 Pi의 필요한 자원량을 충족시킬 수 있어야 한다.
하지만 unsafe state라고 하더라도 항상 deadlock인 것은 아니다. 예를 들어 방금 전에 논의한 테이블에서 T0가 자원 A=1만을 요청하고, 이를 수락해서 그것만을 할당한다면, T0의 할당량은 증가하고(A=0→1), T0의 필요 자원량(A=3→2)과 가용 자원량(A=7→6)은 감소할 것이다. 이 경우 T0가 이후 자신의 자원을 반납하지 않고 가용 자원량보다 많은 최대 자원량을 요청하면 deadlock이 발생할 수 있으므로 unsafe state이지만, 실제로 최대 자원량을 요청한 것이 아니므로 deadlock은 아니다. 애초에 Banker's Algorithm은 가용 자원량으로 필요 자원량을 충족시키지 못하면 자원을 할당하지 않으므로, 항상 safe state를 유지한다.
Handling Method #3: Deadlock Detection and Recovery
1, 2번째 방법과 달리, deadlock이 발생을 예방하지 않다가 시스템에 부하가 생기거나 특정 루틴에 의해 deadlock이 감지가 되면 deadlock 발생 이전으로 복구하는 방법이다. Deadlock Avoidance와 마찬가지로 각 자원마다 인스턴스 수가 1개라면 자원할당그래프를 사용하고(이 경우에도 마찬가지로 테이블을 이용할 수 있다.), 인스턴스 수가 2개 이상이라면 테이블을 이용한다.
Deadlock Detection and Recovery: Wait-for-graph Algorithm (for Single Instance of Resource Types)
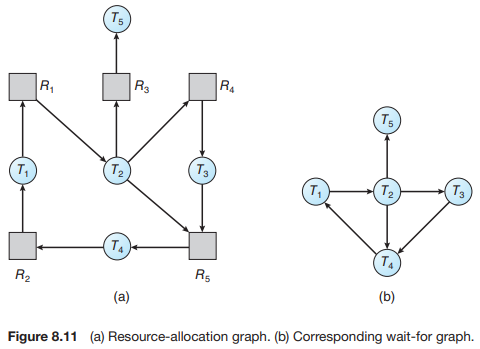
왼쪽의 그림은 자원할당그래프로, 스레드와 자원 간의 요청/할당 관계를 표현하였다. 하지만 wait-for-graph는 자원 표기를 생략하고, 어떤 스레드가 어느 스레드의 자원을 요청하고 대기하는지를 나타낸다. 위 그림에서 오른쪽 그래프는, T1이 T2가 갖는 자원을 기다리고, T2가 T3가 갖는 자원을 기다리는 것을 볼 수 있는데, 결국 그래프 b에서 총 2개의 cycle이 생기므로 deadlock임을 알 수 있다. 또한 deadlock avoidance와 달리 각 태스크 마다 자원의 최대 사용량을 미리 선언하지 않아, 어느 태스크가 적어도 한 번 어떤 자원을 요청하는지 모르므로, 점선 표기가 존재하지 않는다. 이 그래프에서 cycle을 검사하는 시간 복잡도는 O(n*(n-1))인 O(n^2)이다(BFS Algorithm).
Deadlock Detection and Recovery: for Muliple Instances of Resource Types
Deadlock Detection and Recovery는 Deadlock Avoidance처럼 deadlock 발생 가능성을 판단하지 않으므로, 특정 프로세스가 자원을 요청하면 바로 할당한다. 아래의 테이블에서는 특정 시점 t0에서의 할당과 요청, 가용 자원량을 나타낸 것으로, 자원 A, B, C가 각각 7, 2, 6개인 것을 가정한다.
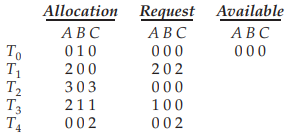
이 상황은 가용 자원이 없는 상황으로, 다른 스레드에서 자원 요청이 들어오면 당장 할당이 불가능하다. 하지만 이 케이스를 낙관적인 시각에서 본다면 deadlock이 발생한 것은 아닌데, 먼저 자원 요청이 없는 T0와 T2가 종료하고 자원을 반납하면 가용 자원이 증가(A=0→2, B=0→1, C=0→2)하고, 다시 자원을 T3이 할당받다가 반납하면 T1이 할당받고, 또 다시 T1이 반납하면 T4가 할당받아 사용할 수 있다. 즉 deadlock이 발생하지 않는 sequence<P0, P2, P3, P1, P4>가 존재한다.
deadlock 발생 가능성이 아닌 발생 여부 그 자체를 보는 것이므로 낙관적으로 해석해야 한다. 예를 들어, 현재 시점에서 T0와 T1은 자원 요청이 없어도 나중에 자원을 요청할 수 있지만, 이 경우를 고려하지 않는 것이다.
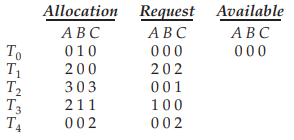
그러나 T2의 자원 요청(C=0→1)이 위와 같을 때를 고려하면 deadlock이 발생하게 되는데, 마찬가지로 자원 요청이 없는 T0가 자원을 반납(B=0→1)하고 종료했다고 해도, 나머지 스레드들은 자원 A와 C만을 요구하기 때문에 자원 요청에 수락할 수 있는 스레드가 존재하지 않는다.
이렇게 deadlock이 발생했을 경우 복구를 진행하는데, 복구 방법은 2가지가 존재한다.
-
Process Termination: deadlock에 연루된 모든 프로세스들을 abort하거나, deadlock cycle이 없어질 때까지 하나씩 abort하는 방식이다.
-
Resource Preemption: 비용을 최소화하는 특정 프로세스를 victim으로 선정하여 자원을 빼앗아 safe state로 복구하여 프로세스를 rollback하고 재시작한다. 이 방법은 동일한 프로세스가 지속적으로 victim으로 선택될 경우 Starvation을 야기할 수 있으므로 해당 프로세스가 rollback한 횟수도 비용 계산에 고려한다.
Handling Method #3: Deadlock Ignorance
발생 가능성이 희박한 deadlock에 특정 연산을 하거나 제약을 두는 것은 비효율적이므로, deadlock이 발생하여도 아무런 조치를 취하지 않는 방법이다. 만약 deadlock이 발생하면 시스템에 부하가 생기고, 사용자가 이를 인지하면 프로세스를 종료하는 방식으로 해결할 수 있다. 이 방법은 UNIX나 Windows 등 대부분의 OS에서 채택하고 있다.
