Process

이화여자대학교 반효경 교수님의 2014년 Operating System 강의를 시청한 후 정리한 내용이다.
http://kocw.net/home/cview.do?cid=3646706b4347ef09
Process
실행 중인 프로그램. 프로그램이 메모리에 올라가면 프로세스가 된다.
Context
프로세스의 실행 문맥. 현재 프로세스가 위치한 메모리 공간과 레지스터에 저장된 값, 프로세스 정보를 담는 커널 데이터가 포함된다.
- 하드웨어 문맥: 프로그램 카운터, 레지스터
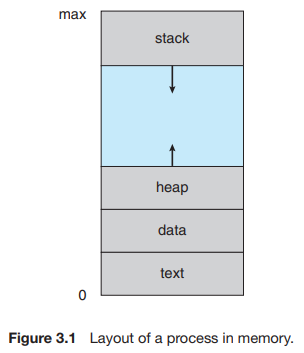
- 프로세스 주소 공간: code, data, stack
- 프로세스 정보를 담는 커널 데이터: PCB, kernel stack
프로그램 카운터(Program Counter)는 다음 실행할 명령어의 주소를 가리키는 레지스터이고, 인텔 x86 CPU에서는 IP(Instruction Pointer)라고도 한다. 그리고 프로세스의 가상 메모리 공간은 code, data, stack역으로 나뉜다. 메모리에 올라간 커널 영역도 마찬가지이며, 커널의 code영역에는 커널 코드가, data에는 커널이 관리하는 프로세스 PCB가 있다. 또한 stack에는 프로세스가 커널 함수를 호출했을 경우(system call 호출 시) 생성되는데, 프로세스별로 커널 스택이 존재한다.
Process State
프로세스의 상태는 new, ready, running, waiting, terminated로 나뉜다.
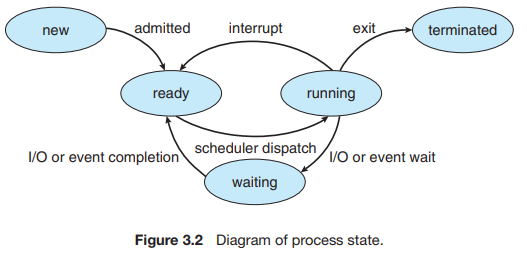
- new: 프로세스가 생성된 상태
- running: 프로세스가 실행 중인 상태
- waiting(block/asleep): 프로세스가 I/O 혹은 시그널 처리 등 이벤트가 발생하는 것을 기다리는 상태. 입출력 작업이 완료될 때까지 Block상태에 놓이는 경우.
- ready: 프로세스의 입출력 작업 등 모든 준비를 마치고 당장 실행 가능하여 CPU를 할당받기를 기다리는 상태
- terminated: 프로세스가 종료되는 상태
Process Control Block (PCB)
커널이 프로세스를 관리하기 위한 프로세스 정보 구조체
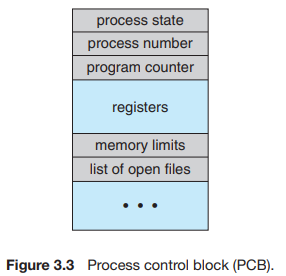
PCB는 아래와 같은 프로세스 정보들을 가지고 있다.
- Process state
- Program counter
- Registers
- CPU shceduling information: 프로세스의 스케줄링 우선순위, 스케줄링 큐 포인터 등의 스케줄링 정보
- Memory-management Information: 페이지 테이블, 세그먼트 테이블 등의 메모리 정보
- Accounting information: CPU점유율, 실제 사용시간, 최대 점유 가능 시간 등 CPU 사용 정보
- I/O status information: 프로세스에 할당된 I/O장치와 파일들의 정보
PCB는 프로세스가 생성되면서 같이 생성되고, 프로세스가 소멸되면 같이 소멸된다.
Context Switching
system call이나 interrupt에 의해 기존 프로세스(p1)에서 다른 프로세스(p2)로 CPU 제어권이 넘어가는 과정을 문맥 교환(Context Switching)이라 한다. 이때 p1의 context를 PCB에 저장한 후, p2의 PCB를 가져와서 p2가 실행했던 시점까지 레지스터, 메모리를 복원한다.
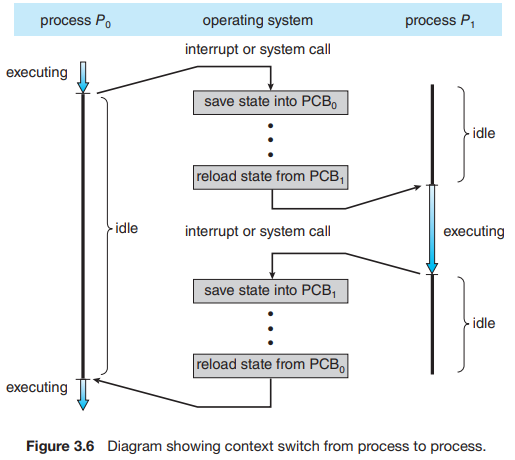
- p1 실행 중, interrupt나 system call, fork에 의해 user mode에서 kernel mode로 전환한다. (timer interrupt가 발생했을 경우, p1의 정해진 CPU 점유 시간이 만료된 것이다.)
- p1의 context를 p1의 PCB에 저장하고, 제어권을 받을 p2의 PCB로부터 레지스터 값과 메모리를 복구한다.
- ready → running: dispatch
- p2의 상태는 ready에서 running로 전환되고, p1의 상태는 어떤 이유로 CPU를 빼앗겼는지에 따라 다르다.
- running → ready: timer interrupt
- running → waiting: I/O request 발생
주의: p1에서 kernel mode로 전환되다가 다시 p1이 바로 실행될 경우, 이는 context switching이라 말할 수 없다. 그리고 context switching은 cache memory flush 연산이 포함된 오버헤드가 큰 작업이다.
Scheduling Queue
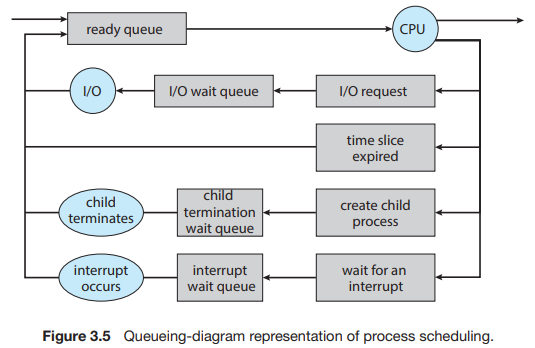
스케줄링에는 큐 자료구조가 사용된다. 또한 스케줄링은 프로세서뿐만 아니라 디바이스에서도 사용되며, 용도에 따라 크게 3가지로 나눌 수 있다.
- Job Queue: 스케줄링에 사용되는 큐 전체
- Ready Queue: ready 상태의 프로세스들의 집합
- Device Queue: I/O 장치의 사용을 기다리는 프로세스들의 집합
프로세스들은 실행 도중에 상태가 변하면서 여러 큐들을 돌아다니게 된다.
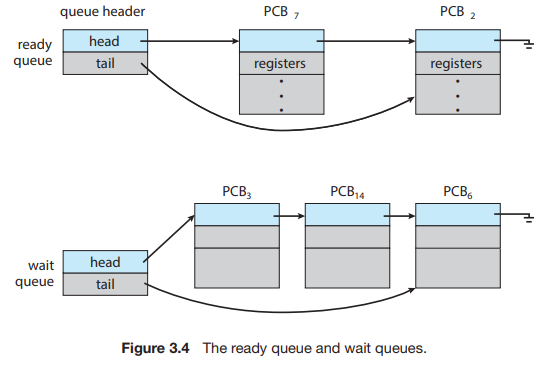
또한 큐는 PCB들의 Linked List로 구성되어 있다. 위 그림에서 PCB 내부에 있는 포인터가 linked list를 형성하여 큐를 구성하는 것을 볼 수 있다.
Scheduler
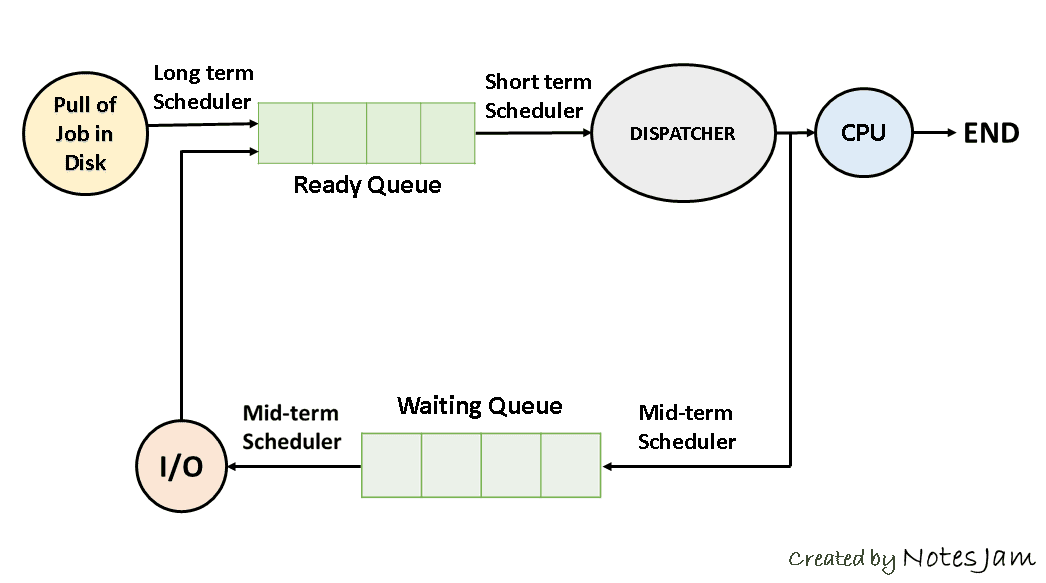
- Long-Term Scheduler (job scheduler): job pool에서 실행할 프로세스들을 선택하여 ready queue에 보내는 스케줄러다. 멀티프로그래밍의 수(degree of multiprogramming, DOM)를 제어한다.
장기 스케줄러의 기능은, 입출력 위주 프로세스와 CPU 위주 프로세스들을 밸런스 있게 선택해 스케줄링하여 CPU의 성능을 끌어올리는 것이다(https://www.scaler.com/topics/what-is-a-long-term-scheduler/). 만약 입출력 위주 프로세스들만 선택한다면, 오랜 시간이 걸리는 I/O 연산 때문에 CPU가 일을 하지 않는 시간이 길어진다. 반대로 CPU 위주 프로세스들만 선택한다면, CPU가 오랜 시간동안 바빠지고 I/O 대기 큐는 비어있게 되며, 입출력 장치들은 사용될 일이 거의 없어지게 된다. - Short-Term Scheduler (CPU scheduler): Long-term scheduler에 의해 선별된 ready queue에 있는 프로세스들 중 실행할 1개의 프로세스를 선택하는 스케줄러다. 단기 스케줄러가 cpu가 실행할 프로세스를 선택하면, dispatcher가 해당 프로세스를 dispatch한다. 스케줄링하는 시간이 매우 짧아 빠른 것이 특징이다.
- Medium-Term Scheduler (Swapper): 여러 프로세스들이 메모리 위에 올려져 있는 상황에서, 특정 프로세스가 메모리를 많이 점유하여 메모리 공간의 여유가 없을 경우, 해당 프로세스를 강제로 메모리에서 디스크로 쫒아내어 degree of multi-programming을 제어한다. 이때 메모리에서 프로세스를 내리는 것을 swap-out, 올리는 것을 swap-in이라 한다.
Suspended State
중기 스케줄러나 사용자가 의도적으로 정시시킨 경우(Ctrl+Z, break key) 등의 이유로 프로세스가 정지되어 메모리에서 swap-out된 상태이다. 이때 memory image는 secondary storage의 swap 영역에 저장된다. 그리고 스케줄러나 사용자가 해당 프로세스를 swap-in하면 메모리를 얻게 되어 resume하게 된다.
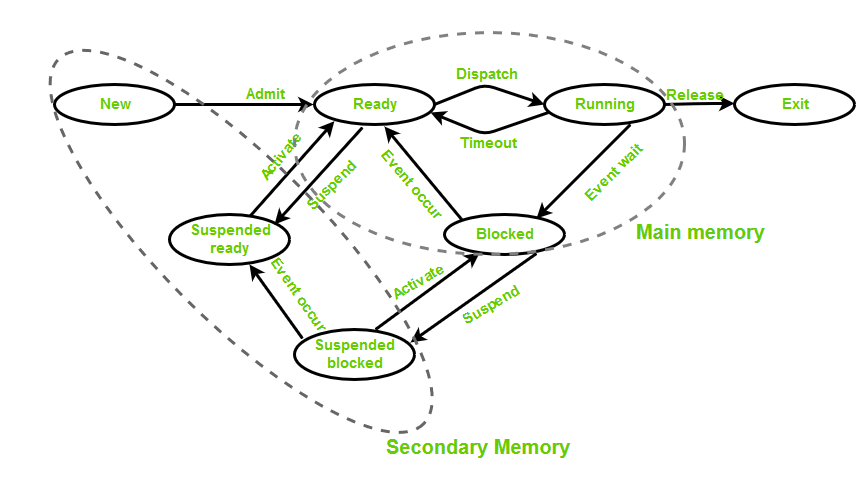
- suspended ready: new(created) 프로세스가 바로 메모리를 빼앗기거나, ready상태에서 CPU를 오랜 시간 점유하지 못하는 프로세스가 swap-out 되면서 전이하는 상태. swap-in을 하면 ready상태로 다시 복귀한다.
- suspended waiting(block/asleep): waiting상태에서 ready로 오랜 시간 넘어가지 않는 경우 swap-out하여 전이하는 상태. swap-in을 하면 waiting상태로 복귀하고, suspended waiting 상태에서 I/O 작업이 끝나면 suspended ready 상태로 전이한다.
Thread
스레드는 CPU의 실행 단위이고 모든 프로세스에 적어도 1개의 스레드가 있다. 스레드가 1개인 프로세스를 single-thread process, 2개 이상이라면 multi-thread process라고 한다.
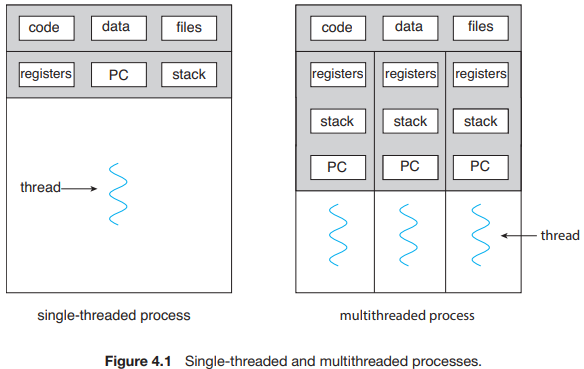
스레드는 code, data, heap 영역을 공유하며, open된 파일 서술자 테이블도 공유하므로, IPC 기법 없이 스레드간 쉽게 통신 가능하다. 그러나 같은 코드를 공유해도 각 스레드의 실행 과정이 다르므로 별도의 program counter와 stack 영역을 갖는다. 이러한 특징을 갖는 스레드를 사용하면 메모리가 복제되는 multi-process(fork(2))보다 자원을 절약할 수 있다. 그리고 하나의 스레드가 block되는 동안 다른 스레드가 실행이 가능하므로 비교적 빠른 응답성을 기대할 수 있으며, 시스템이 2개 이상의 CPU를 가질 경우(multi-processing system), 각 스레드들은 병렬적으로 실행 가능하다(kernel-level thread 한정).
스레드 구현 방법은 2가지로 나뉜다.
- User-Level Thread: 커널이 관리하지 않는 스레드, 라이브러리로 지원받다. 커널은 해당 스레드의 존재를 모르므로, 멀티스레드 프로세스인 경우에도 커널은 싱글스레드 프로세스로 보고 관리한다. 그리고 스레드 간 동기화나 스레드 문맥 교환에서 커널이 개입하지 않는다. 따라서 스레드를 사용자 수준에서 쉽게 관리할 수 있고, 커널 모드가 필요하지 않으므로 빠르게 thread switching이 가능하다. 또한 커널 수준 스레드과 달리 어느 운영체제에서도 동작할 수 있다.
그러나 유저 수준 스레드는 multiprocessing system에서 각 core를 갖고 동시에 실행할 수 없고, 하나의 스레드가 block상태로 빠지면 해당 프로세스도 block상태가 되는 단점이 존재한다. - Kernel-Level Thread: 커널이 관리하는 스레드. 스레드의 문맥 정보도 커널이 관리하며, 유저 수준 스레드보다 비교적 속도가 느리다. 그러나 multiprocessing system에서 스레드가 각 core를 갖고 병렬적으로 실행이 가능하며, 하나의 스레드가 block상태가 되어도 다른 스레드는 실행할 수 있다. 그러나 thread switching에서 커널 모드가 필요하며, 운영체제에 종속적으로 이식성이 낮다 단점이 있다.
Thread Control Block
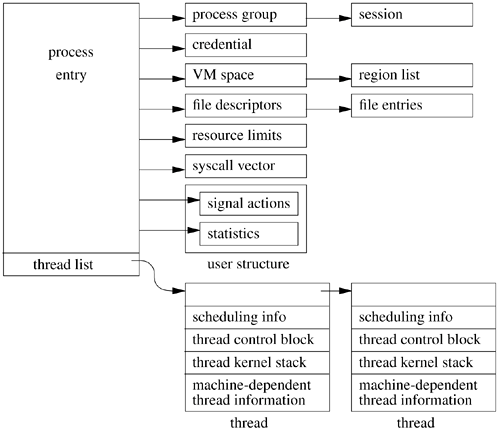
TCB는 커널이 스레드 정보를 관리할 때 사용하는 자료구조이고, PCB에서 프로세스가 갖는 스레드의 TCB를 가리키는 포인터가 존재한다. TCB에서는 스레드가 별도로 갖는 TID와 스레드 상태, PC, 각 레지스터의 값을 저장하고, 다른 스레드를 가리키는 포인터가 있다. 프로세스와 마찬가지로, 스레드 간 context switching이 발생할 경우 해당 TCB를 저장 및 교환한다. 그러나 프로세스 간 context switching이 발생하면 PCB 정보 뿐만 아니라 TCB 정보도 같이 교환 및 저장한다.
