
📌 이분 탐색
이진 탐색 으로 불리기도 한다.
대표적인 분할 & 정복 (Divide & Conquer) 알고리즘이다.
리스트에서 탐색 범위를 절반씩 좁혀가며 데이터를 탐색하는 알고리즘으로, 리스트의 내부의 데이터가 정렬되어 있어야만 사용 가능한 알고리즘이다.
start, end, mid 총 3개의 변수를 사용하여 찾으려는 데이터와 중간점 위치에 있는 데이터를 반복적으로 비교해서 원하는 데이터를 탐색할 수 있다.
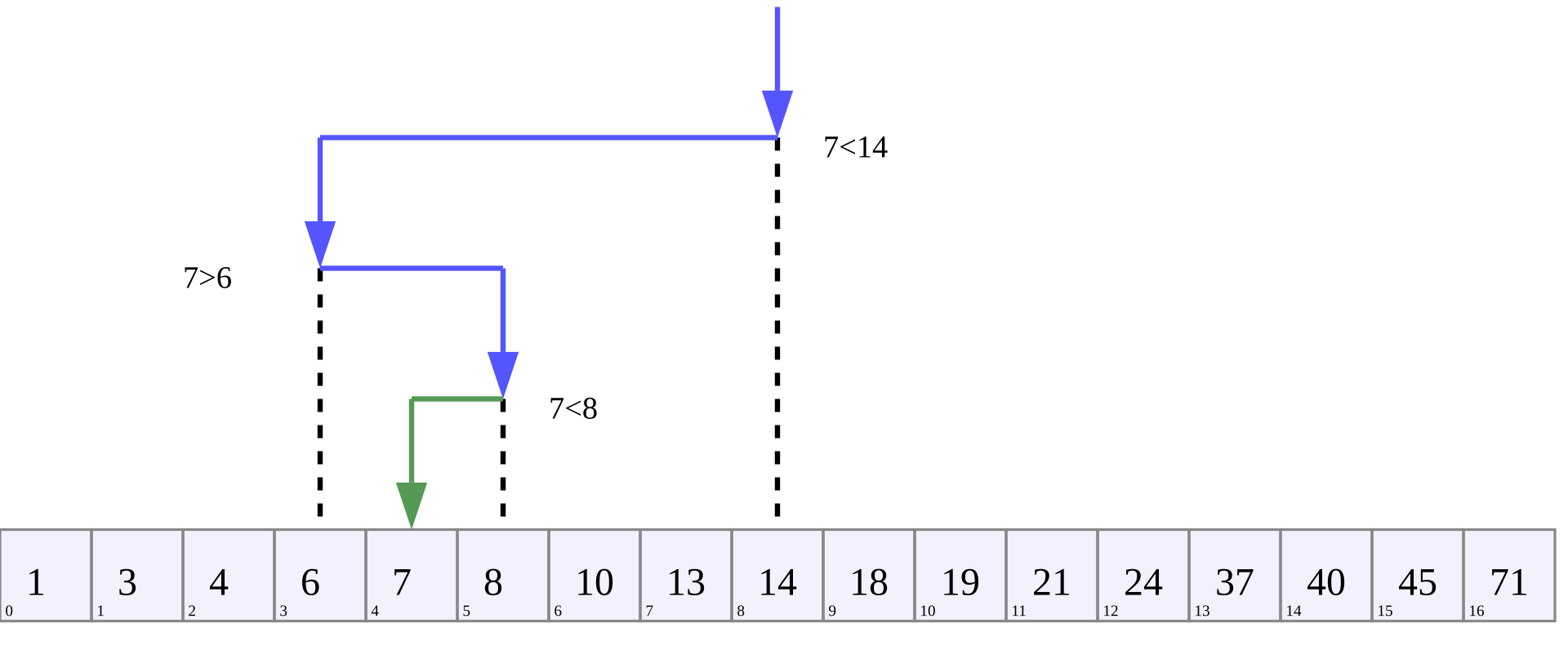
💿 동작 방식
start 는 배열의 시작 인덱스, end 는 배열의 끝 인덱스, mid 는 start 와 end 의 중간값으로 설정한다.
mid 번째 값과 검색 값을 비교한다.
- 해당 값과 검색 값이 같다면, 원하는 값을 찾았기 때문에 비교를 종료한다.
- 해당 값이 검색 값보다 크다면,
mid를 기준으로 오른쪽 구간에 대해서 재탐색한다. - 해당 값이 검색 값보다 작다면,
mid를 기준으로 왼쪽 구간에 대해서 재탐색한다.
💿 시간 복잡도
이진 탐색 은 어떠한 경우에도 O(log N) 의 시간 복잡도를 보장한다.
| best | average | worst |
|---|---|---|
| O(1) | O(log N) | O(log N) |
💿 코드의 구현
반복문과 재귀 두가지 방식으로 구현 가능하다.
//반복문을 사용하여 구현
int BinarySearch(vector<int> &_target, int _start, int _end, int _key)
{
while (_start <= _end)
{
int mid = (_start + _end) / 2;
if (_target[mid] == _key) //검색에 성공한 경우
return mid;
else if (_target[mid] > _key)
_end = mid - 1;
else
_start = mid + 1;
}
//검색에 실패한 경우(_start > _end)
return -1;
}//재귀를 사용하여 구현
int BinarySearch(vector<int> &_target, int _start, int _end, int _key)
{
if (_start > _end) //검색에 실패한 경우
return -1;
int mid = (_start + _end) / 2;
if (_target[mid] == _key) //검색에 성공한 경우
return mid;
else if (_target[mid] > _key) //중간 값이 검색 값보다 큰 경우
return BinarySearch(_target, _start, mid - 1, _key);
else //중간 값이 검색 값보다 작은 경우
return BinarySearch(_target, mid + 1, _end, _key);
}📌 파라메트릭 서치 (Parametric Serach)
최적화 문제를 결정 문제로 바꾸어 이분 탐색을 통해 해결하는 것이다.
최적화 문제 : 어떤 값의 최댓값 / 최솟값을 구하는 문제
결정 문제 : 답이 Yes or No로 갈리는 문제
💿 조건
다음과 같은 조건을 만족하여야 파라메트릭 서치를 활용하여 문제를 해결할 수 있다.
-
특정 조건을 만족하는 최댓값 / 최솟값을 구하는 형식의 문제이거나 이러한 형태로 변형이 가능한 문제여야 한다.
-
최댓값을 구하는 문제의 경우, 어떤 값이 조건을 만족하면 그 값보다 작은 값은 모두 조건을 만족해야 한다.
최솟값의 경우, 그 값보다 큰 값은 모두 조건을 만족해야 한다. -
답의 범위가 이산적이거나 허용 오차 범위가 있어야 한다.
이분 탐색으로는 정답에 한없이 가까워질 수는 있지만 완전히 정확한 값은 구할 수 없기 때문이다.
💿 시간 복잡도
조건 함수가 얼마나 빠른지에 따라 결정된다.
조건 함수가 한번 실행될 때 걸리는 시간 복잡도를 O(C(n)) 이라고 하면, 총 시간 복잡도는 O(C(n)log N) 이다.
