
📌 set
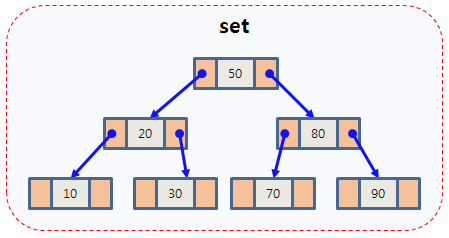 set의 내부 구조
set의 내부 구조
연관 컨테이너 (associative container) 중 하나로, 노드 기반 컨테이너 이며 균형 이진 트리 로 구현되어 있다.
중복이 허용되지 않는 key라고 불리는 원소들의 집합이다.
원소 삽입 시 자동으로 정렬되며, 기본적으로 오름차순 정렬을 지원한다.
set을 순회할 때, 중위 순회 방식으로 순회를 진행한다.
💿 선언 방법
- 비어 있는 set을 생성하는 경우 :
set <데이터 타입> 이름; - iterator를 통해 값을 초기화하는 경우 :
set <데이터 타입> 이름 (시작 반복자, 끝 반복자);
ex)
set <int> s1;
...
set <int> s2 (s1.begin(), s2.begin()); //s2에는 s1의 모든 원소가 복사되어 저장된다.- 정적 배열의 이름을 통해 값을 초기화하는 경우 :
set <데이터 타입> 이름 (배열이름 + 시작 인덱스값, 배열 이름 + 끝 인덱스값); - set을 복사하여 값을 초기화하는 경우:
1)set <데이터 타입> 이름 (복사할 set 이름);
2)set <데이터 타입> 이름 = 복사한 set 이름;
💿 시간 복잡도
- 임의의 원소에 접근하는 경우 :
O(logN) - 특정 원소를 검색하는 경우 :
O(logN) - 원소를 삽입 / 삭제하는 경우 :
O(logN)
💿 장 / 단점
- 장점
- 데이터의 처리 속도가 빠르다.
- 중복된 데이터를 처리할 수 있다.
- 삽입, 삭제, 탐색 연산 모두 동일한 시간 복잡도를 가진다.
- 단점
- 데이터 삽입 시 이진 탐색 트리를 재조정해야하기 때문에 속도가 느릴 수 있다.
- 데이터 삽입 시 복사 생성자를 사용하기 때문에 객체가 크거나 복잡한 경우, 성능 문제가 발생할 수 있다.
📌 unordered_set
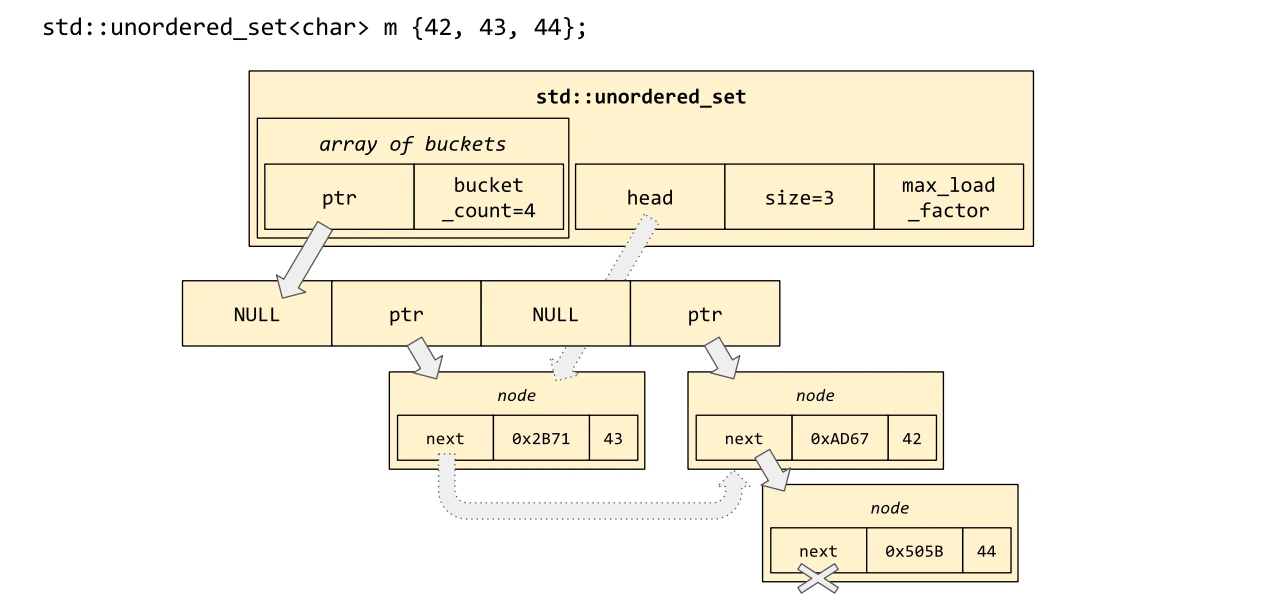 unordered_set의 내부 구조
unordered_set의 내부 구조
자동으로 정렬을 지원하지 않는 set이다.
💿 시간 복잡도
- 임의의 원소에 접근하는 경우 :
O(1) - 특정 원소를 검색하는 경우 :
O(1) - 원소를 삽입 / 삭제하는 경우 :
O(1)
시간 복잡도의 차이가 나는 이유?
set은 레드-블랙 트리 로 구현되어 있고, unordered_set은 해시 테이블 로 구현되어 있기 때문이다.
📌 multiset
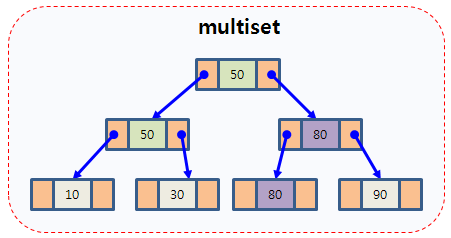 multiset의 내부 구조
multiset의 내부 구조
key 값의 중복을 허용하는 set이다.
set에서 insert의 return 값은 삽입한 원소를 가리키는 반복자와 삽입 성공 / 실패 여부를 묶은 pair객체이지만, multiset에서 insert의 return 값은 삽입한 원소의 위치를 가리키는 반복자이다.
이미지 출처

학습 내용 정리 순차적 갱신 / 정리 중