1. Introduction
- 본 논문 이전까지 DNN(Deep Neural Network)는 음성인식, 사물인식 등에서 꾸준히 좋은 성과를 보여옴. 그러나 Input size가 고정된다는 한계점이 존재하여 순서가 있는 Sequencial problem을 제대로 해결할 수 없는 문제가 존재
- 본 논문에서는 2개의 LSTM 구조를 각각 Encoder, Decoder로 사용해 이러한 DNN의 Sequencial problem을 해결하는 것을 제안함.
2. The Model
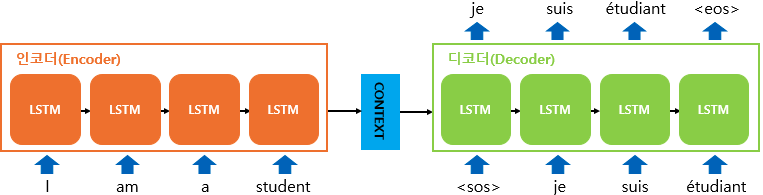
- 본 논문에서 제시하는 모델은 Encoder 부분에 해당되는 첫번째 LSTM 모델 구조에서 Context Vector를 생성한 뒤, Decoder 부분에 해당되는 두번째 LSTM 모델 구조에서 Context Vector를 활용한 Output Sentence를 생성하는 방식으로 동작함.
- Input Sentence ↔ Output Sentence 간 단순 매핑이 아니라, Input Sentence를 통해 Encoder LSTM 에서 Input Sentence의 문맥적 의미를 포함한 Context Vector를 생성하고 이를 Decoder LSTM의 첫번째 Layer 입력으로 받아 이와 유사한 Output Sentence를 만들어냄.
- 본 논문에서는 Input Sentence에서 단어 순서를 reverse해서 사용하였으며, 각 문장별 구분을 알리는 End of Sentence Token을 각 Sentence의 끝에 추가하여 다양한 길이의 문장 구조에 대해서도 적용가능하게 하였음.
- Input Sentence에서 단어 순서를 Reverse하게 입력시킨 이유?
- 원래의 순서대로 나열된 단어의 경우 source와 target에서의 연결되는 단어쌍(pair of word) 사이의 거리가 모두 동일하지만, 이를 reverse시킬 경우에는 sentence에서 앞에 위치한 단어일수록 단어쌍 사이의 거리가 짧아지고 뒤에 위치한 단어일수록 단어쌍 사이의 거리가 멀어지게 됨.
- sequencial problem에서는 앞쪽에 위치한 data가 뒤의 모든 data에 영향을 주기 때문에 앞에 위치한 data일 수록 중요도가 더 높다고 할 수 있음.
- reverse를 통해 source sentence에서 앞쪽에 위치한 data(word)들의 target sentence에서의 연관 word와의 거리를 줄이는 것은 더 중요도 높은 data에 대해 더 좋은 성능을 보장함.
- Input Sentence에서 단어 순서를 Reverse하게 입력시킨 이유?
3. Experiments
- 본 논문에서는 WMT’14의 English to French dataset 사용
- 실험에 사용한 Dataset의 대부분은 Short length sentence여서 mini-batch 사용 시 각 batch 마다 매우 적은 수의 long length sequence가 포함되는 문제로 인해, 각 Batch마다 비슷한 Length를 갖는 sentence가 포함될 수 있도록 normalization 진행함.
- source / target language 각각에 fixed size vocabulary를 사용 (source: 160,000 / target: 80,000)
- 실험결과, long sequence에서는 source sentence를 reverse시킨 경우가 특히 성능이 더 좋았으며 구체적인 수치로 BLEU score가 25.9에서 30.6으로 증가함.
- BLEU Score : Input, Output 모두 sequence로 이루어져 있는 경우 주로 사용되는 지표이며 Machine translation task에 주로 사용됨.

- 간단하게, 문장 길이와 단어의 중복을 고려하여 정답문장과 예측문장 사이의 겹치는 정도를 수치화 한 지표
- BLEU Score : Input, Output 모두 sequence로 이루어져 있는 경우 주로 사용되는 지표이며 Machine translation task에 주로 사용됨.
- 이는 SOTA(State of the Art)에 비해 0.5 낮은 BLEU Score 임.
Conclusion
- 본 논문에서는 LSTM 기반의 encoder-decoder 구조로 sequentical problem을 제대로 해결할 수 없는 기존의 DNN 모델 구조의 한계점을 개선하였으며 reversed order input sentence를 모델의 입력으로 주어 long length sentence의 long term dependency 문제를 개선함.

📚 IT 지식과 최신 기술 트렌드, 금융 관련 내용을 공유합니다.