
출처
제목: "HikariCP Dead lock에서 벗어나기 (실전편)"
작성자: techblog.woowahan(이재훈)
작성자 수정일: 2020년2월6일
링크: https://techblog.woowahan.com/2663
작성일: 2022년8월16일장애 상황
장애 환경에 대한 Thread count와 maximum pool size의 조건은 아래와 같.
- CPU Core : 4개
- Thread Count: 16개
- HikariCP MaximumPoolSize: 10개
하나의 Task에서 동시에 요구되는 Connection 갯수: 2개
(처음엔 1개일거라 생각했지만, getConnection에 대한 디버깅을 해보니 2번의 getConnection 요청이 발생했다.)
실제 구현부의 간단한 코드
@Entity
class Message {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
private String title;
private String contents;
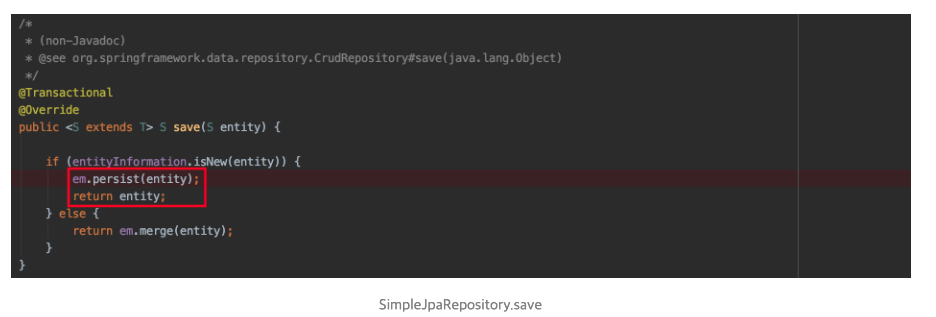
}@Transactional
public Message save(final Message message) {
return repository.save(message)
}왜 이 코드에서 Connection이 2개나 필요할까?
코드만 보면 하나의 Connection으로 Insert가 잘 될것 같다
하지만 아니지요
범인은 @GeneratedValue(strategy = GenerationType.AUTO)
-
JPA에서 DB Insert시, id 생성 방식을 결정하는 Annotation이다.
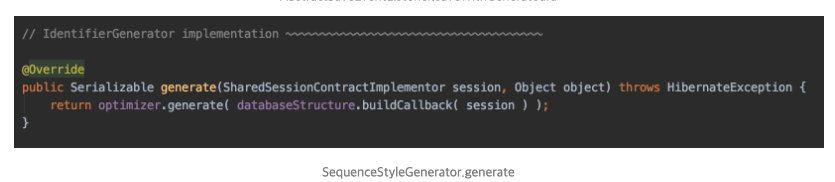
GenerationType이AUTO이고, id 변수의 Type이 Long이기 때문에 내부적으로는SequenceStyleGenerator로 ID를 생성하게 됩니다.
-
기본적으로
Sequence를 기반으로ID를 생성하는Generator이지만 -
MySQL은
Sequence를 지원하지 않기 때문에hibernate_sequence라는 테이블에 단일 Row를 사용하여 ID값을 생성한다. -
여기서
hibernate_sequence테이블을 조회,update를 하면서Sub Transaction을 생성하여 실행하게 된다.
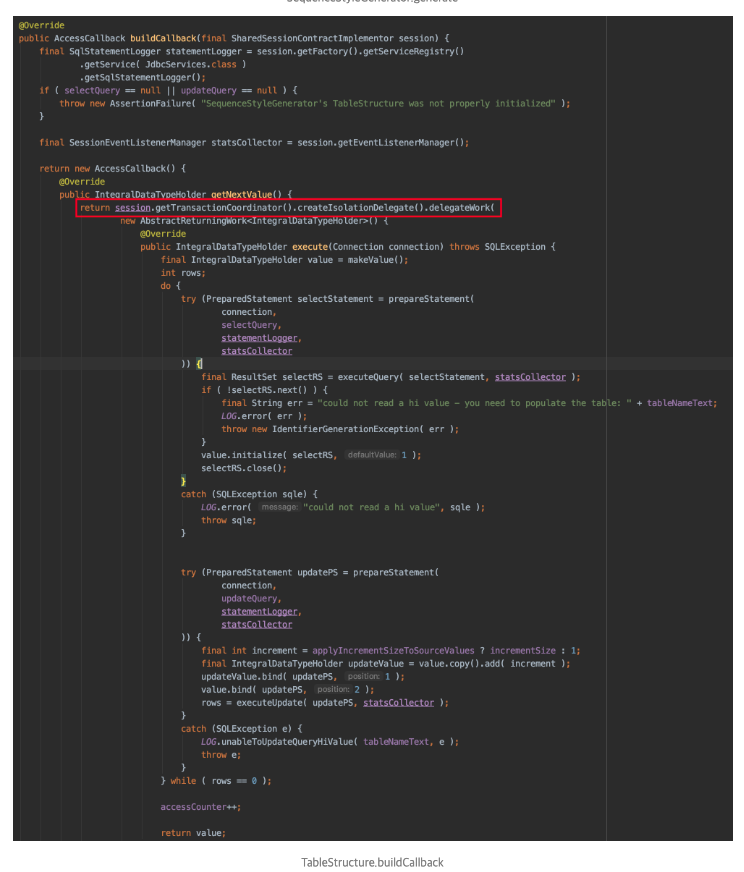
ID 하나 주세요
select next_val as id_val from hibernate_sequence for update;
-
MySQL for update쿼리는 조회한 row에lock을 걸어 현재 트랜잭션이 끝나기 전까지 다른 session의 접근을 막는다. -
별도 Sub Transaction을 구성한 이유는 만약 현재 사용 중인 상위 Transaction을 사용했다면,
상위 Transaction이 끝나기 전 까지 다른 thread에서 ID 채번을 할 수 없기 때문이라고 추측하고 있다.
코드
아래 이미지의 라이브러리 버전은 다음과 같다.
- spring-data-jpa-2.2.1.RELEASE
- hibernate-core:5.4.8.Final
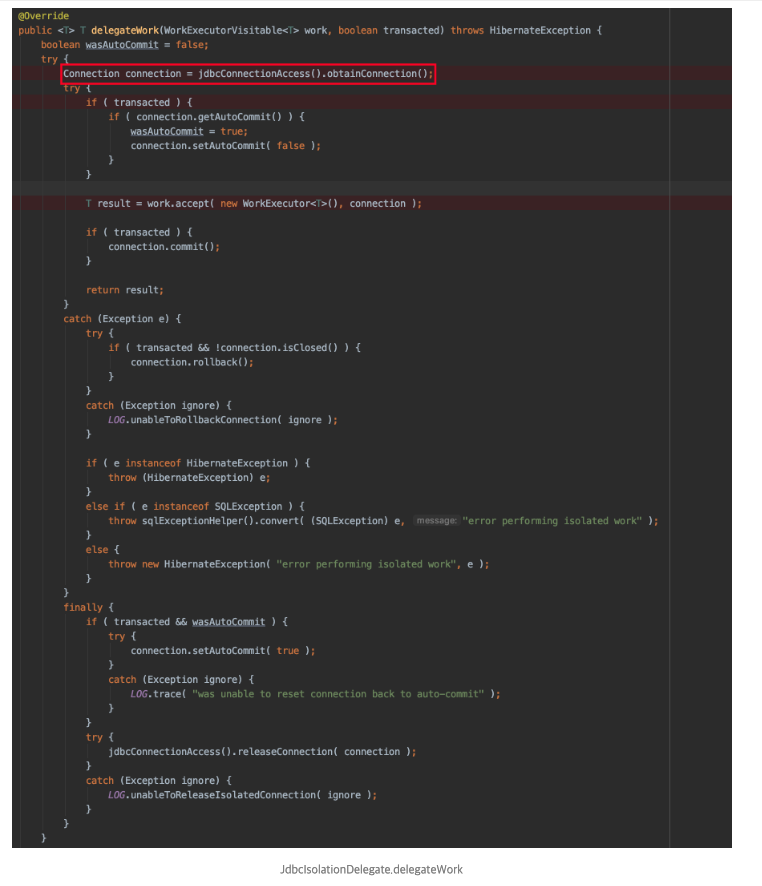
-
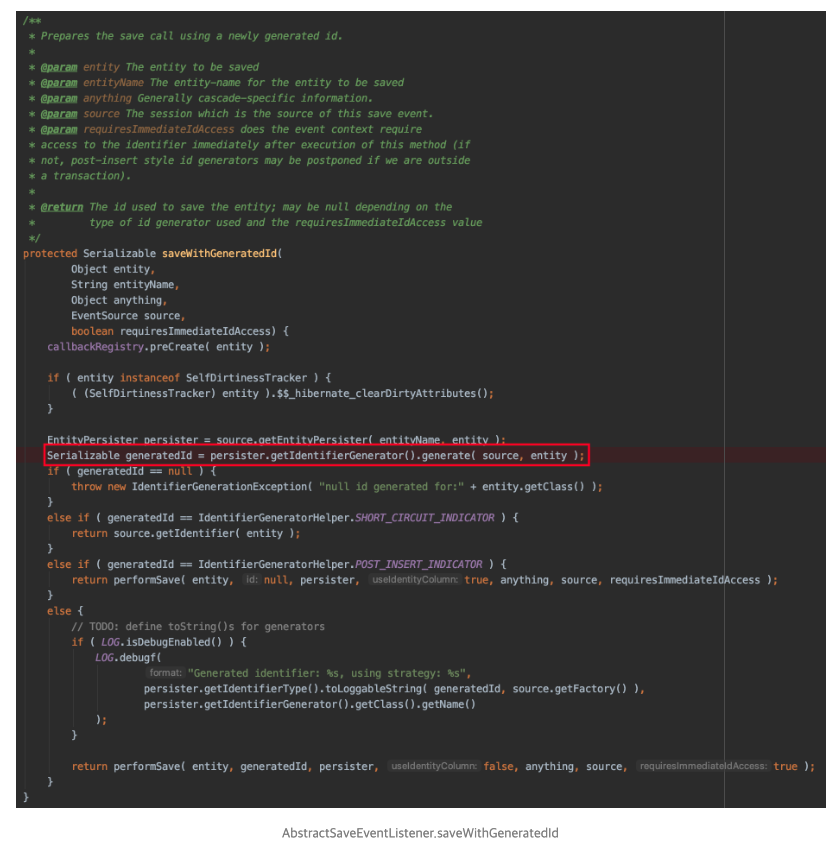
ID 채번을 위한 Query를 실행하는 과정에서
Connection connection = jdbcConnectionAccess().obtainConnection();코드가 실행 되며 2번째 Connection을 가지고 오게 된다. -
ID를 조회하고, update 하는 Transaction이 commit되면 Connection이 바로 Pool에 반납이 된다.
실제 운영환경에서는 어떤 일이 일어나고 있을까?
일반적인 상황에서는 확률이 적었을 것이다. Thread 전체가 동시에 일하지 않을 것이기 때문이다.
하지만 문제는 Thread 전체가 일하는 부하상황에서 발생한다.
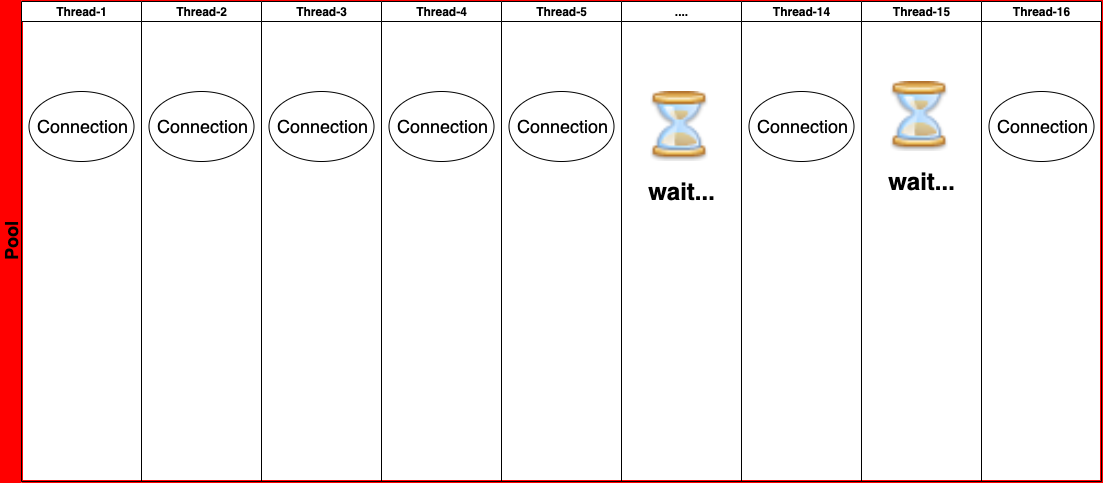
부하 상황에서 16개의 Thread가 거의 동시에 HikariCP로부터 Connection을 얻어내 10개의 Thread만이 Connection을 가지고 Transaction을 시작했을 것이다.
하지만 ID 생성을 위한 Connection을 얻으려 하면, 현재 Pool에는 idle Connection이 없기 때문에 handOffQueue에서 대기하게 된다.
그렇게 타임아웃이 발생하면 SQLTransientConnectionException이 발생하고 Transaction이 rollback 되면서 다시 Connection이 Pool에 반납되고 handOffQueue에서 기다리는 다른 Thread에서 다시 Connection을 받아가기 시작한다.
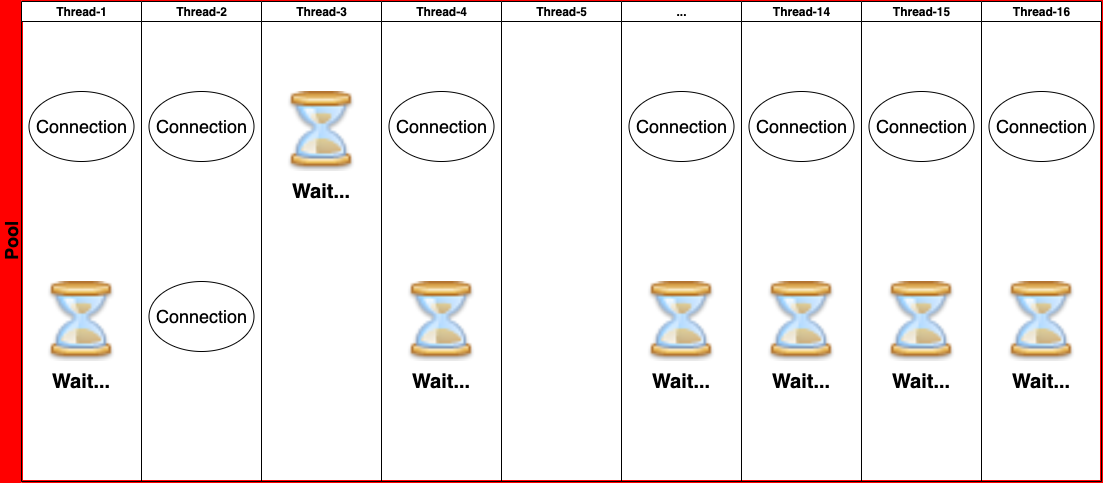
어쩌다 운이 좋은 Thread는 타이밍을 맞춰서 Id 채번을 위한 Connection을 받아낼 수도 있다.
(이 Case가 간헐적으로 어쩌다 성공하는 Case가 된다.)
이와 같은 경우를 HikariCP에서는 Dead lock 또는 Pool-locking 이라는 용어를 사용하여 표현하고 있다.
그래서 어쩌라고?
이미 이 이슈는 HikariCP github에서도 issue로 등록되었고, HikariCP wiki에서 Dead lock을 해결하는 방법을 제시하고 있다
- Github: https://github.com/brettwooldridge/HikariCP
- issue: https://github.com/brettwooldridge/HikariCP/issues/442#issuecomment-146096704
- wiki: https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing
수리수리 마수리
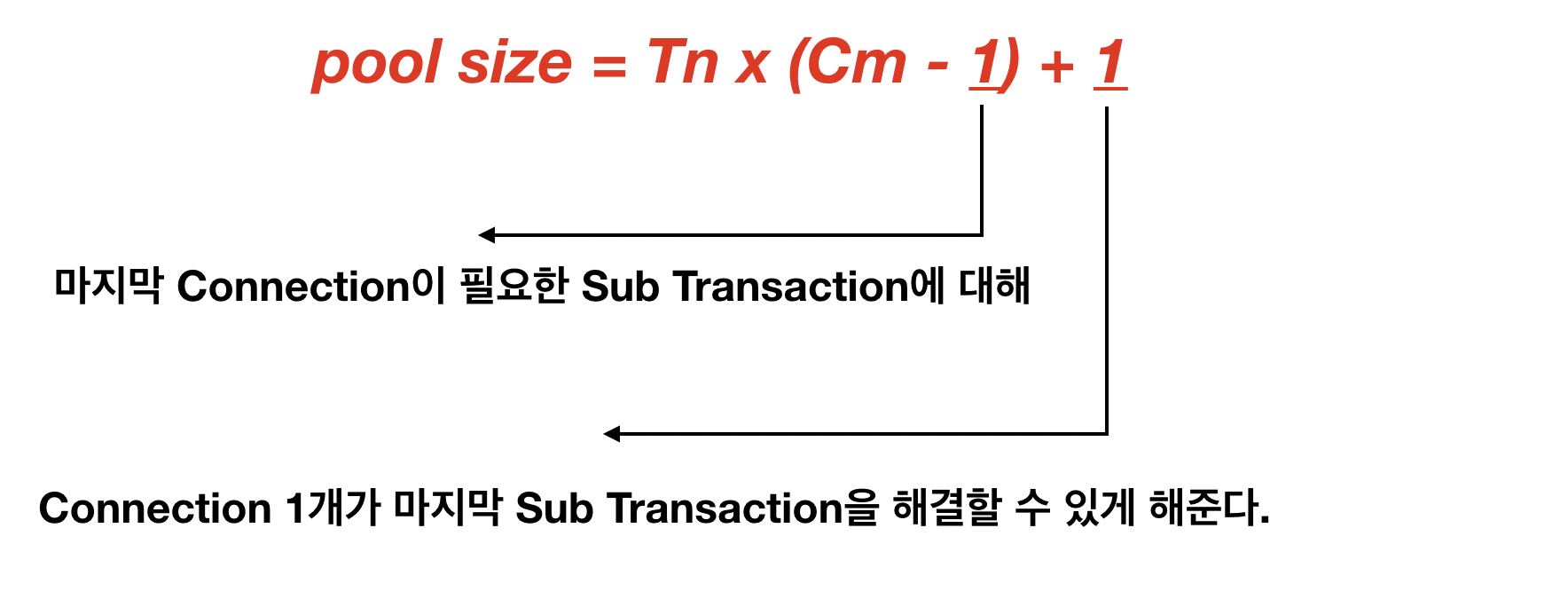
마법의 공식

- Tn : 전체 Thread 갯수
- Cm : 하나의 Task에서 동시에 필요한 Connection 수
- HikariCP wiki에서는 이 공식대로 Maximum pool size를 설정하면 Dead lock을 피할 수 있다고 합니다.
검증 들어간다

- 전체 Thread 갯수: 8개
- 하나의 Task에서 동시에 요구되는 Connection 갯수: 2개
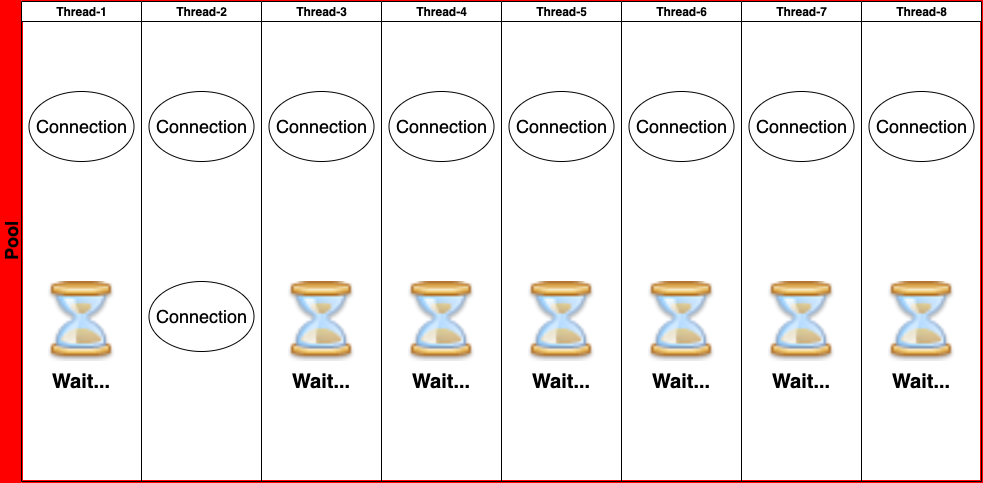
- 8개의 Thread가 동시에 HikariCP에 Connection을 요청하고 8개의 Connection을 골고루 나눠 가졌다.
- 그럼에도 불구하고 1개의 Connection이 남아있다.
- 이 1개의 Connection이 Dead lock을 피할 수 있게 해주는 Key Connection이 됩니다.
위의 예시에서는 Thread-2에서 먼저 ID 채번을 위한 Connection을 얻었다.
그렇게 되면 정상적으로 DB Insert가 이루어지고, idle Connection 2개가 Pool에 반납된다.
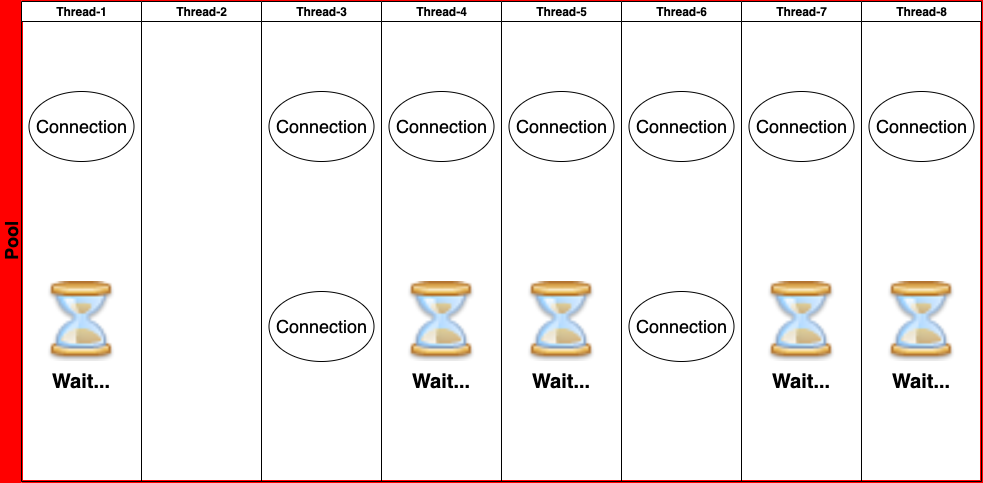
- 다음 Step으로 Thread-2를 제외한 Thread는 handOffQueue에서 새로운 Connection을 얻기 위해 대기하다가
Thread-2가 반납한 Connection을 받아가게 된다, - 위의 예시에서는 Thread-3, Thread-6에서 사이 좋게 나눠 가져간다.
위의 공식대로 pool size를 설정하니 Dead lock이 발생하지 않게 되었다.
다시 공식을 보자
이게 최선입니까?
-
위의 공식은 이론적으로 Dead lock을 피할 수 있는 최소한의 Pool size 이다.
-
공식대로라면 Thread가 몇 개이든 동시에 필요한 Connection이 1개라면 Pool size가 1개인 Pool을 가지고도 모든 Request를 다 처리할 수 있을 것이다.
-
하지만 효율이 좋지 않겠죠. 어떤 Thread는 운이 없게 할당받지 못해서 30초 후에
SQLTransientConnectionException을 던질 수도 있다. -
그렇기 때문에 최적의 Pool Size를 설정하기 위해서는 Dead lock을 피할수 있는 pool 갯수 + a가 되어야한다.
-
이에 대한 방법으로는 성능 테스트를 수행하면서 최적의 Pool Size를 찾는 방법이 있을 것 같다.
장애 후속 처리
- Dead lock을 회피할 수 있는 pool size 적용
- SequenceGenerator에 대한 Pooled-lotl optimizer 적용
Dead lock을 회피할 수 있는 pool size 적용

-
위와 같은 pool size 공식을 기준으로 내부적으로 기본 공식을 확장하여 사용해보자
-
조금 더 성능 테스트를 진행해야 하겠지만 일단은 아래와 같이 설정하였다.
-
thread count : 16
-
simultaneous connection count : 2
-
pool size : 16 * ( 2 – 1 ) + (16 / 2) = 24
SequenceGenerator에 대한 Pooled-lotl optimizer 적용
위의 코드에서 확인했지만, SequenceStyleGenerator에는 몇가지 optimizer를 통해 ID를 채번할 수 있다.
NoopOptimizer
Default Optimizer이다. generate() 메서드 호출 시 마다 DB에 Query하여 ID를 채번한다.
sequence값을 +1씩 update하여 사용한다.
HiLoOptimizer
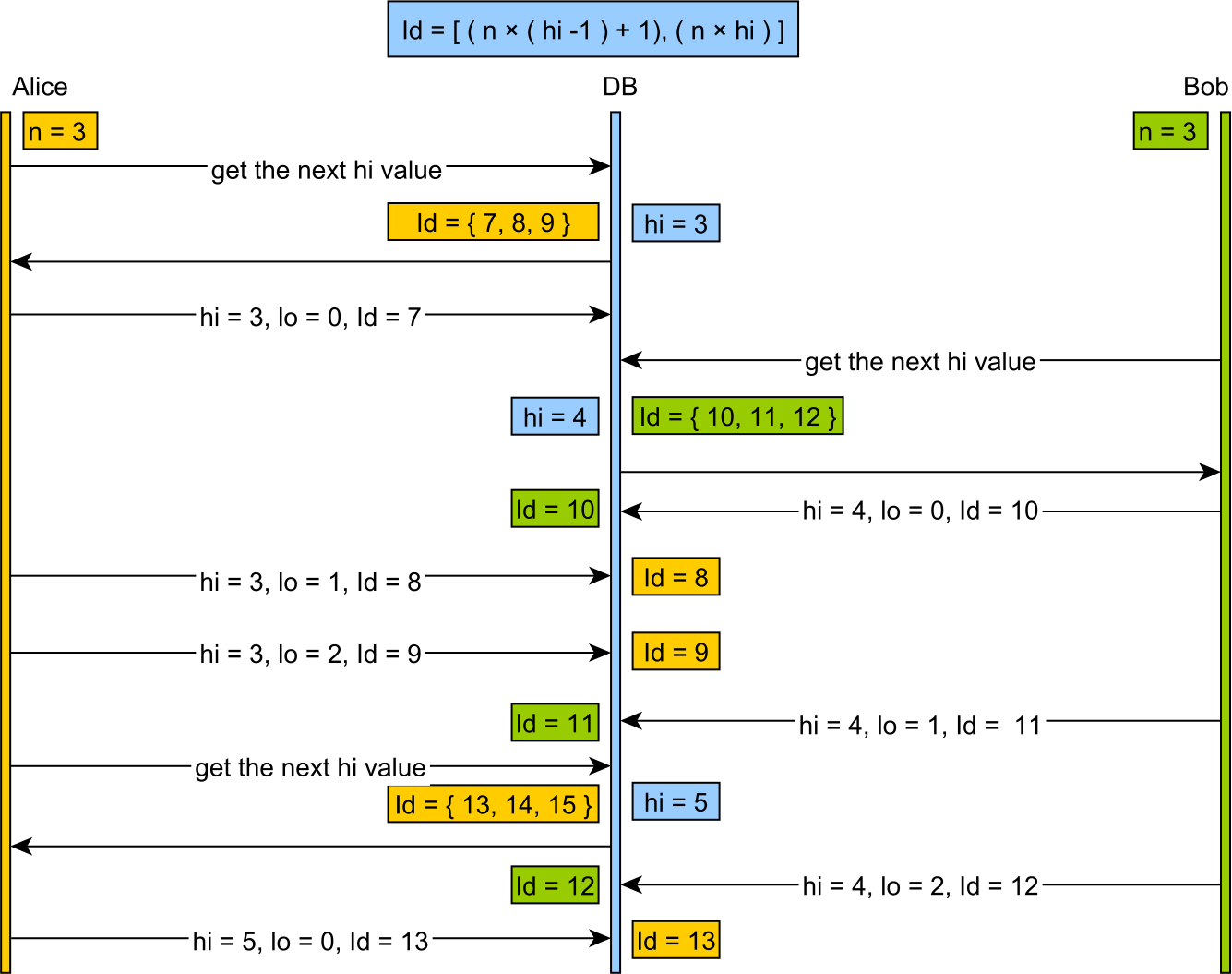
- "hilo" algorithm 을 적용한 Optimizer이다.
- 내부적으로 hilo optimizer는 deprecated된 optimizer이다.
(increment (조회한 Sequence -1) + 1) ~ (Hincrement 조회한 Sequence) 만큼의 범위를 사용 ID를 채번한다.
PooledOptimizer
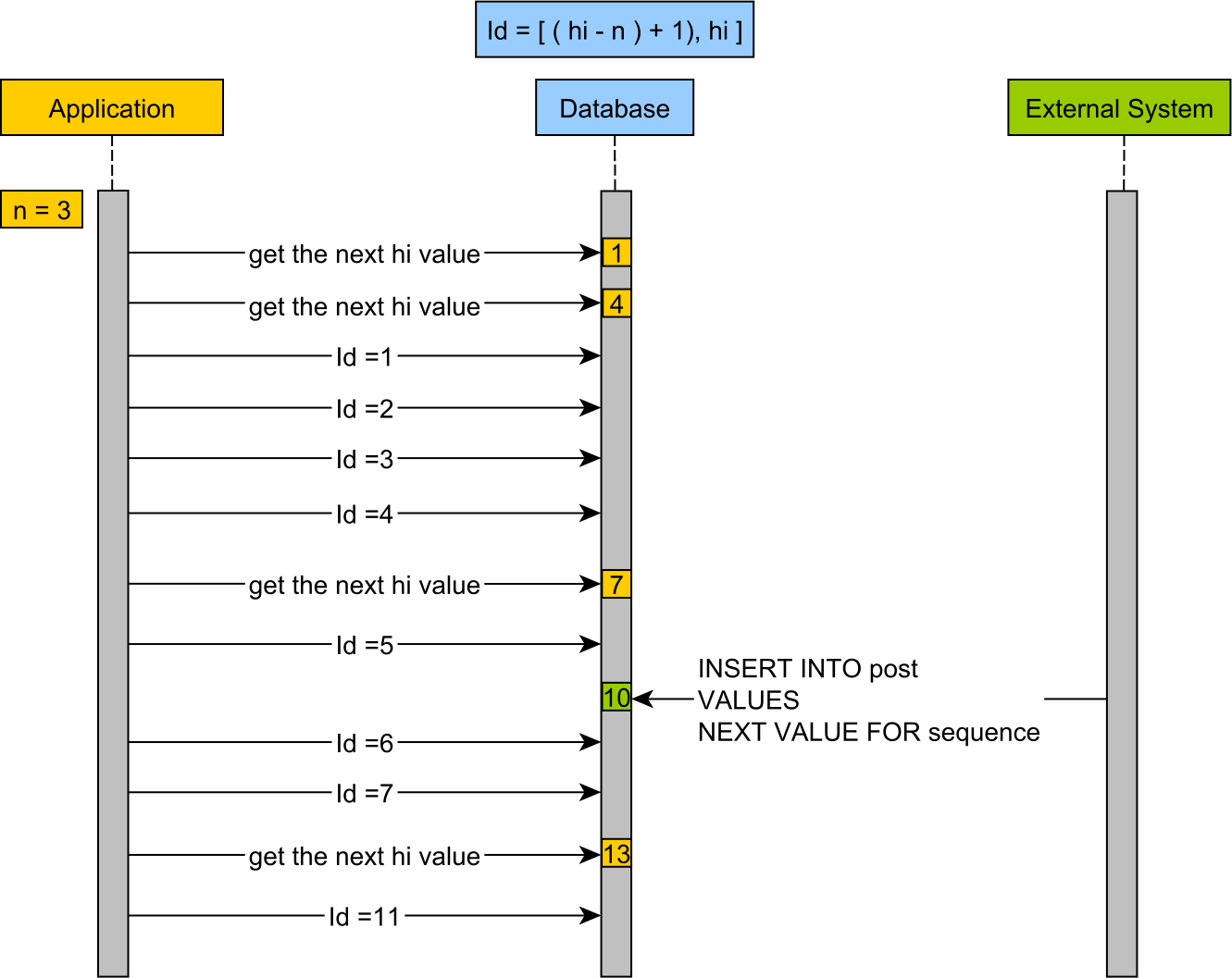
- NoopOptimizer와 다르게 한번에 incrementSize만큼 sequence를 업데이트하고 범위만큼 메모리에서 관리하는 방식이다.
- (조회한 sequence - increment) ~ 조회한 sequence 만큼의 범위를 DB를 Query하지 않고 메모리를 이용하여
채번할 수 있다.
- ex) 현재 sequence가 1000이고 increment가 100인 경우, 900~999까지는 DB를 Query하지 않고 메모리에서 채번.
update hibernate_sequence set next_val = next_val + 100 where next_val = 1000을 실행하여 미리 100만큼 업데이트 한다.
PooledLoOptimizer
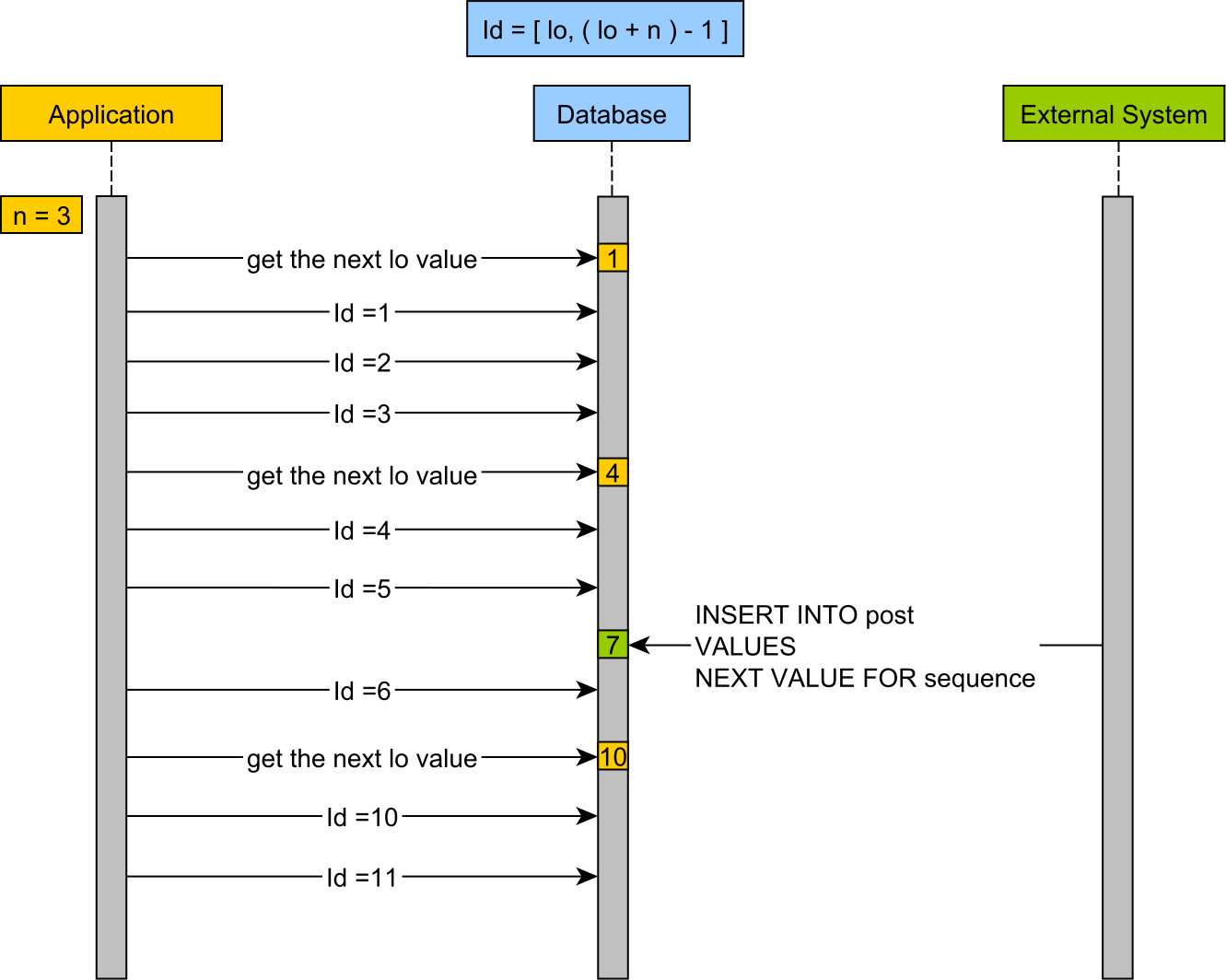
PooledOptimizer와 동일하지만 조회해 온 sequence값을 Low값으로 하여 사용한다.
ex) 현재 sequence가 1000이고 increment가 100인 경우, 1000~1099까지는 DB를 Query하지 않고 메모리에서 채번한다.
PooledLoThreadLocalOptimizer
PooledLoOptimizer를 Thread단위로 사용한다.
ex) 현재 sequence가 1000이고 increment가 100인 경우,
thread-1에서는 1000~1099까지 범위를 사용.
thread-2에서는 1100~1199까지 범위를 사용
이 방식의 장점은 Thread 별로 ID 구간을 관리하므로 효율성 입장에서는 PooledLo보다 좋다.
- PooledLoThreadLocalOptimizer를 사용했다.
- 작업 단위가 Thread단위로 분리되어 있고, 굳이 Linear한 ID를 생성할 필요가 없기 때문입니다.
아래처럼 코드를 구성하여 Optimizer를 적용하였다.
@Entity
class Message {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "message-id-generator")
@GenericGenerator(
name = "message-id-generator",
strategy = "sequence",
parameters = [
Parameter(name = SequenceStyleGenerator.SEQUENCE_PARAM, value = "hibernate_sequence"),
Parameter(name = SequenceStyleGenerator.INCREMENT_PARAM, value = "1000"),
Parameter(name = AvailableSettings.PREFERRED_POOLED_OPTIMIZER, value = "pooled-lotl")
]
)
private long id;
private String title;
private String contents;
}- 이렇게 적용하니 Thread에서 ID 범위를 설정할 때만
hibernate_sequence에 Query 하여 - NoopOptimizer를 사용할 때 보다 Connection을 사용 횟수를 줄여 조금 더 효율적으로 Connection을 사용할 수 있게 되었다
왜
@GeneratedValue(strategy = GenerationType.AUTO)를 사용 했나요?사실
GenerationType.IDENTITY를 사용하고,MySQL id column에auto_increment를 적용하면
1개의 Connection으로도 insert 할 수 있습니다.
하지만 저희는 auto_increment를 사용하지 말아야 할 이유가 있었습니다.
메세지 플랫폼에서 사용하는 메세지 발송 Table은 데이터의 삽입/삭제가 빈번하게 일어납니다.
그런데 RDS Restart 시, auto_increment의 index가 변경될 가능성이 있습니다.
(RDS Restart 시, Table의 Last ID 기준으로 auto_increment index가 조정됩니다.)
외부 벤더사와의 연동을 하다보니 이전에 사용한 ID를 다시 사용하면 안되는 벤더사 측 이슈가 있기 때문에,
중복되지 않고, ID 대역을 언제든지 조작할 수 있도록 SEQUENCE로 사용하도록 의사 결정 하였습니다.
내 코드에서 Dead lock 발생 가능성을 체크해보자
- HikariCP의 Maximum Pool Size을 1로 설정한 다음 1건씩 Query를 실행해 본다.
- 만약 정상적으로 실행되지 않고, connection timeout과 같은 에러가 발생한다면 Dead lock 발생 가능성이 있는 코드이다.
Nested Transaction을 사용하지 않는다. 보이지 않는 dead lock을 유발할 수 있다.
