출처
제목: "내가 만든 서비스는 얼마나 많은 사용자가 이용할 수 있을까? - 1편(성능 테스트란?)"
작성자: tistory(Hooligans)
작성자 수정일: 2020년12월18일
링크: https://hyuntaeknote.tistory.com/10
작성일: 2022년8월13일성능 테스트는 왜 해야 되나요?
-
성능 테스트는 말 그대로 서비스의 성능적인 부분을 측정하기 위해 실행되는 작업이다.
-
어플리케이션의 성능을 측정한다는 것은 점진적인 부하를 가하는 과정 속에서 더 이상 처리량이 증가하지 않을 때, 그 수치를 측정하고 해석하는 것을 의미한다.
그렇다면 이러한 행위는 왜 하는 걸까?
-
성능 테스트의 목적은 첫 번째로 현재 어플리케이션이 최대 몇 명의 사용자를 수용할 수 있는지 측정하고, 그 결과가 최초 목표한 성능에 부합하는지 알아내기 위함이다.
-
두 번째는 만약 성능에 부합하지 않는다면 어떤 지점에서 병목이 발생하고, 이를 해결하기 위해 무엇을 해야 하는지 분석하여 개선함으로써 최종적으로 서비스가 중단되는 상황 없이 제공될 수 있도록 가용성을 높이는 것이다.
이러한 성능 테스트의 목적을 달성하기 위해서 서비스가 빠른지 느린지에 대한 명확한 기준이 필요하다
그렇다면 서비스의 성능은 어떤 수치를 기준으로 알 수 있을까?
서비스의 빠름과 느림의 기준
서비스의 속도를 결정하는 기준은 Throughput과 Latency를 보면 알 수 있다.
Throughput? Latency? 각각의 성능 지표가 어떤 것이길래 서비스의 성능을 파악할 수 있을까?
Throughput
-
Throughput이란 시간당 처리량을 의미한다. TPS(Throughput Per Second), RPS(Request Per Second) 등으로도 불리며, '1초에 처리하는 단위 작업의 수' 혹은 '1초에 처리하는 HTTP 요청 수' 등으로 해석할 수 있다.
-
즉, 1초에 최대한 많은 작업을 처리할 수 있는 서비스가 성능 측면에서 좋은 서비스라고 볼 수 있다.
-
예를 들어, A 서비스는 1초에 1000개의 작업을 처리하고 B 서비스는 1초에 2000개의 작업을 처리할 수 있는 능력을 가졌다면 B 서비스가 동일 시간 내에 더 많은 작업을 할 수 있으므로 성능면에서 더 좋다고 볼 수 있다.
-
이렇듯 Throughput을 보면 내 서비스의 작업 처리 능력을 알 수 있으며, 이는 서비스 성능의 지표가 될 수 있다.
Latency
-
Latency는 서버가 클라이언트로부터 요청을 받아서 응답을 보내주기까지 걸리는 시간을 의미한다. 쉽게 말해서 Latency는 서비스가 작업을 얼마나 빠르게 처리할 수 있는지를 나타내는 성능 지표로 볼 수 있다.
- 영어 그대로 직역해보자면 서버가 클라이언트의 요청을 처리하는데 발생하는 지연시간으로도 생각해볼 수 있다.
-
예를 들어, A 서비스의 웹 서버가 WAS로부터 요청을 응답을 보내는데 걸리는 시간이 100ms이고, B 서비스의 웹 서버가 WAS로부터 요청을 응답을 보내는데 걸리는 시간이 50ms가 걸렸다면, B서비스가 작업을 더 빨리 처리할 수 있음을 알 수 있고, 이에 따라 성능면에서 더 좋다고 볼 수 있따.
서비스의 성능을 파악할 수 있는 기준을 알아보았다. 여러 개의 시스템으로 구성된 웹 서비스에서 성능을 어떻게 해석해야 하고, 개선해야 하는지 자세히 알아보자
성능 개선
웹 서비스는 여러 시스템으로 구성되어 있다. 지금은 쉽게 설명하기 위해서 웹 서버 - WAS - DB 로 구성된 서비스를 예로 살펴보자
아래 그림은 해당 서비스의 구성과 각 하위 시스템들의 성능을 표시하였다. 설명을 위해 예를 든 것이니 혹시나 모든 성능이 저런 비율로 측정되는것은 아니다.
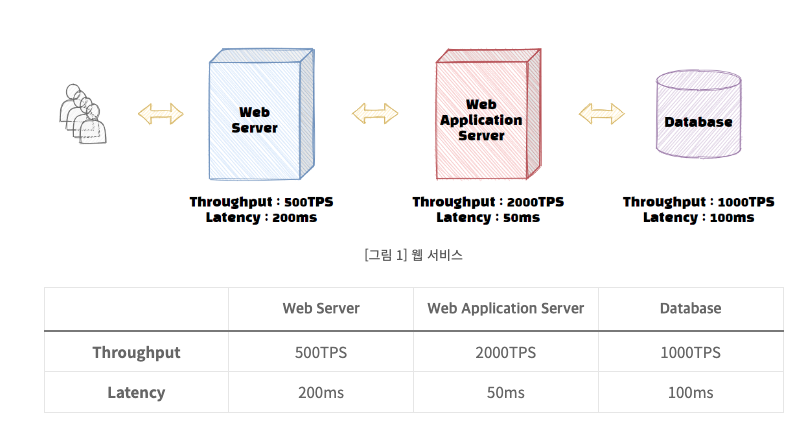
우선 그림을 보고 잠시 생각해보자. 전체 서비스의 Throughput은 얼마나 될까?
정답은 500 TPS이다.
-
성능에 대한 비유는 고속도로 정체 상황을 비유하자
- 하나의 작업을 차 한대로 가정하고, 500TPS는 Web 서버라는 고속도로를 1시간당 500대의 차가 통과한다고 가정하자
-
이러한 상황에서 만약에 2000대의 차량이 해당 도로를 통과하면 어떤일이 벌어질까
- Web 서버에서 차들은 정체되고, WAS와 DB는 웹 서버를 통과한 차들만 수용할 수 있으므로 아무리 시간당 WAS에서 2000대를 통과시킬 수 있더라도 시간당 500대만 통과하게 된다.
현재 상황을 웹 서비스로 다시 돌아와보면 이러한 경우, 웹 서버에서 병목이 발생했다고 볼 수 있다.
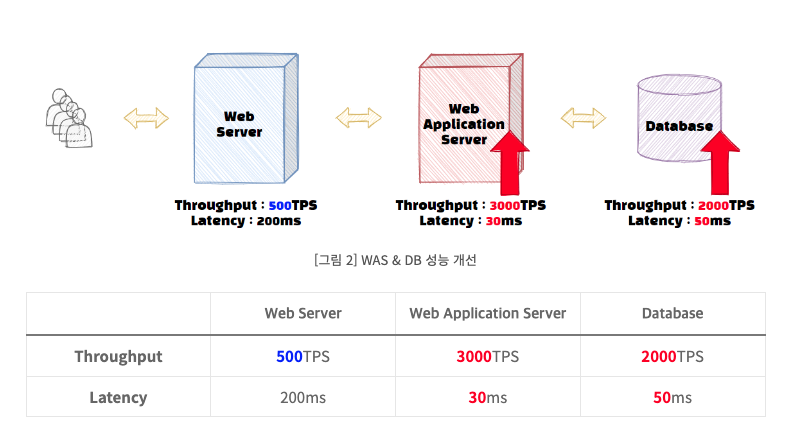
그렇다면 여기서 DB나 WAS 성능을 아래와 같이 개선한다고 해서 전체 서비스의 성능이 올라갈까?
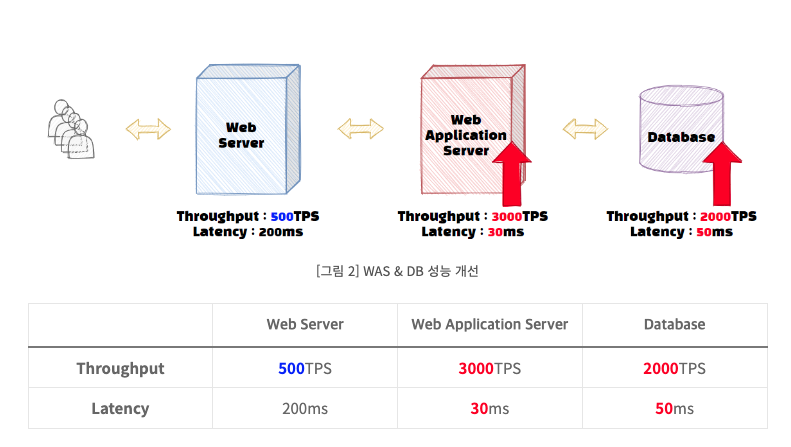
서비스의 성능이 올라간다고 생각하면 안된다
-
여전히 웹 서버의 TPS가 동일하기 때문에 해당 서비스는 여전히 초당 500개의 TPS만 통과할 수 있다.
-
이러한 병목 현상과 같이 서비스의 성능 중 가장 큰 영향을 미치는 부분을 Critical Path라고 한다.
-
서비스의 전체 성능을 높이기 위해서는 Critical Path를 찾아야 하고, 여기에 해당하는 Throughput이 증가해야만 해결할 수 있다.
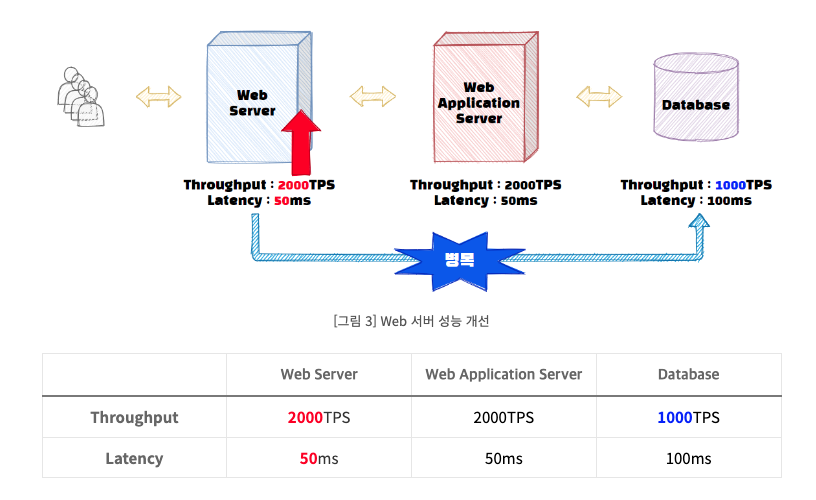
다시 돌아와서 DB와 WAS는 그대로 두고 Web 서버의 성능을 개선해보자.
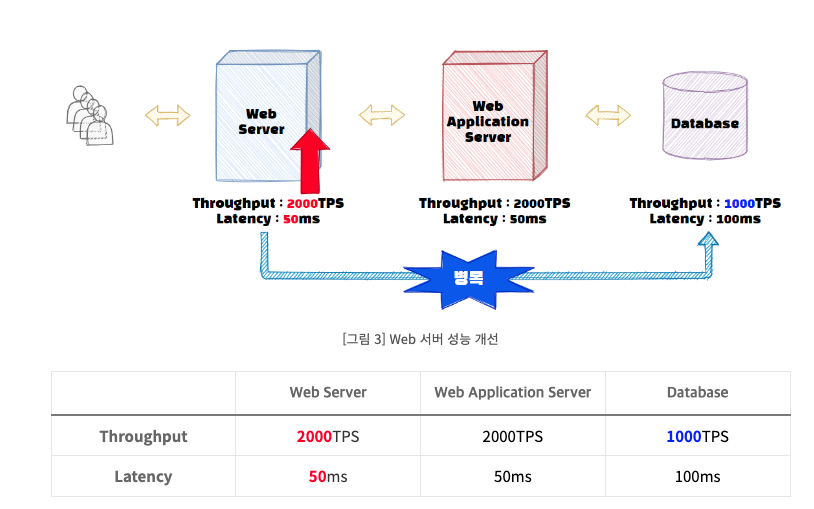
웹 서버의 Throughput이 개선되자 웹서버와 WAS에서는 2000개의 트랜잭션을 처리할 수 있게 된다. 하지만 DB에서 초당 2000개의 처리작업을 수행할 수 없으므로, 서비스 전체의 Throughput은 DB의 Throughput인 1000TPS로 변경된다.
그래도 이전 500TPS에서 1000TPS로 개선되었으니 해당 서비스의 성능은 2배 빨라졌다고 할 수 있다.
또한 병목이 웹서버에서 데이터베이스로 옮겨갔다. 이와 같이 기존 구간의 성능 개선을 하게되면 Critical Path는 바뀔 수 있고, 우리는 이러한 Critical Path(병목 구간)을 지속적으로 해결하면서 전체 서비스의 성능을 올려야 한다.
종합해보면 우리가 서비스의 Throughput이라고 말하는 것은 서비스의 하위 시스템들 중 가장 낮은 처리량을 의미한다.
또한 Throughput 관점에서 성능을 개선한다는 의미는 Critical Path을 찾아서 이를 개선한다는 것을 의미한다.
다음으로 서비스의 Latency는 얼마일까?
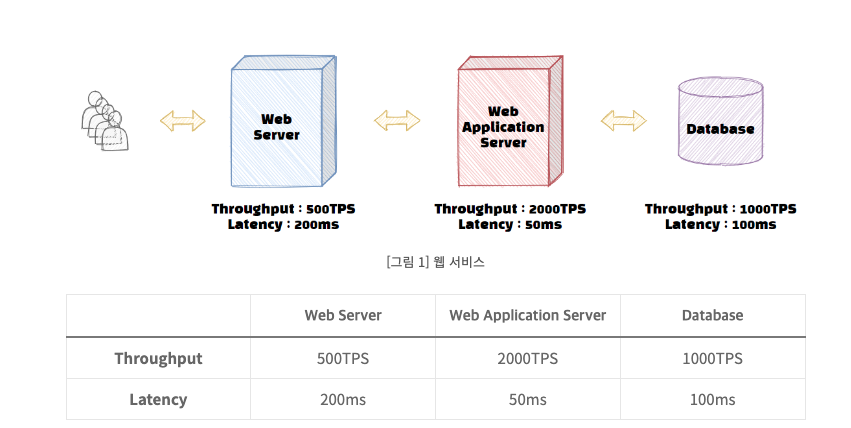
서비스의 Latency는 대기시간을 포함한 각 하위 시스템 Latency의 총합이다. 위 그림을 참고하면 현재 서비스의 Latency는 350ms+대기시간으로 해석할 수 있다.
Latency를 개선하기 위해서 고려할 요소들을 굉장히 많다.
-
기본적으로 하드웨어의 처리 성능, 어플리케이션 로직, 쿼리 인덱스 등 다양한 원인으로 작업의 Latency가 발생할 수 있다. 더 나아가 Throughput이 한계점에 도달하면 대기시간 또한 길어지므로 Latecny 발생의 원인이 될 수 있다.
-
Throughput을 분석할 때와 달리 Latencty의 경우, 하나의 하위 시스템 Latecny가 줄어들면 전체 서비스의 Latency도 줄어들게 되므로 병목 구간을 찾기보다 가장 Latency가 큰 하위 시스템을 개선하는 것이 서비스의 Latency를 큰 폭으로 줄일 수 있는 방법이다.
WAS와 DB의 Latency를 줄이면서 전체 서비스의 대기시간을 제외한 Latency은 350ms->280ms로 줄였다.
이렇듯 서비스 Latency 개선의 경우, 병목 지점과 관계없이 각 하위 시스템들의 Latency 개선이 전부 영향을 줄 수 있음을 알 수 있다.
물론 위 그림 처럼 Throughput을 개선하면 대기시간이 줄어들어 Latency를 줄일 수 있기 때문에 Throughtput을 개선하는 것이 Latency 개선에도 영향을 줄 수 있다.
결론
- 성능 테스트는 서비스가 목표하는 최대 사용자 수에 도달하기 위해 현재 성능을 파악하고, 개선하는 작업이다.
- 서비스의 성능을 알 수 있는 지표는 Throughput과 Latency가 있다.
- 전체 서비스의 성능을 개선하기 위해서는 하위 시스템의 병목 구간을 찾아 개선하고, 각 하위 시스템의 Latency를 줄여서 전체 서비스의 Latency를 줄여야 한다.
