
이진트리란?
-
이진트리(Binary tree)란 자식노드가 최대 두 개인 노드들로 구성된 트리를 말한다.
-
이진트리의 depth가 d인 노드의 수는 최대 2^d 노드이다.
-
높이가 H인 노드가 가질수있는 최대 노드의 개수는 2^(H+1)-1이다.
-
n개의 노드를 가진 트리는 적어도 lg(n+1)-1 의 높이를 가진다.
package week5;
public class Node {
private int value;
private Node left;
private Node right;
public Node addLeftNode(int value){
Node newNode = new Node(value);
this.left= newNode;
return newNode;
}
public Node addRightNode(int value){
Node newNode = new Node(value);
this.right= newNode;
return newNode;
}
public int getValue() {
return value;
}
public void setValue(int value) {
this.value = value;
}
public Node getLeft() {
return left;
}
public void setLeft(Node left) {
this.left = left;
}
public Node getRight() {
return right;
}
public void setRight(Node right) {
this.right = right;
}
Node(int value){
this.value=value;
this.left=null;
this.right=null;
}
}이진탐색트리의 조건
1) 이진탐색트리의 자식 노드 개수는 2개이하이다.
2) 모든원소는 중복된 값을 가져서는 안된다.
3) 왼쪽 서브트리에 존재하는 노드들의 값은 그 트리의 루트 값보다 반드시 작다.
4) 오른쪽 서브트리에 존재하는 노드들의 값은 그 트리의 루트 값보다 반드시 크다.
이진탐색트리의 삽입
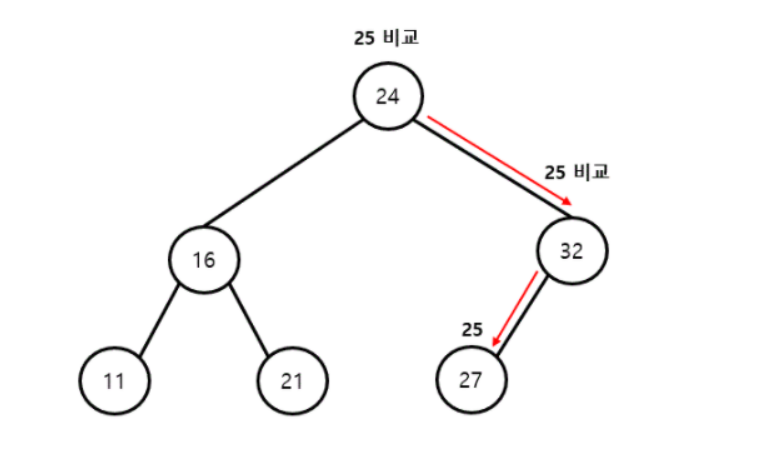
public void insertNode(int value){
if(root==null){
setRoot(new Node(value));
}else{
Node tempNode= root;
// 노드 순회 시작
while(true){
if(tempNode.getValue()==value){
System.out.println("노드 내 중복된 값이 존재합니다");
break;
} else if(tempNode.getValue()>value){
// 값이 작아 좌측으로 빠지는 경우
if(tempNode.getLeft()==null){
tempNode.setLeft(new Node(value));
break;
}else{
tempNode = tempNode.getLeft();
}
} else{
if(tempNode.getRight()==null){
tempNode.setRight(new Node(value));
break;
} else{
tempNode = tempNode.getRight();
}
}
}
}
}이진탐색트리 삭제
이진탐색트리의 노드 삭제에는 다음과 같은 세가지 경우가 존재한다.
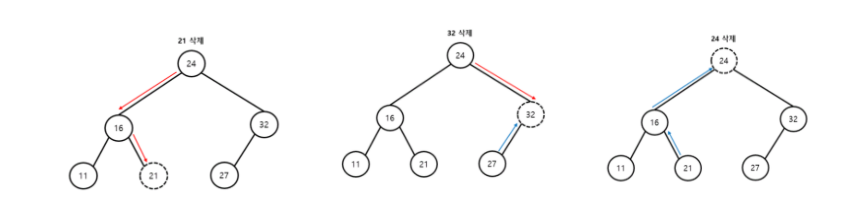
위 세가지 경우는 자신이 삭제하려는 노드가 자식을 몇개 가지고 있는지에 따라 달라지게 된다.
1) 자식이 없는 경우: 해당 노드 삭제, 부모 노드의 참조값 삭제
2) 자식이 1개인 경우: 부모 노드의 값을 자식노드의 값으로 대체해주어야 한다.
3) 자식이 2개인 경우: 자식이 2개인 경우 둘중하나의 기준을 잡아 노드를 처리해주어야 한다.
(삭제하려는 노드의 좌측 최댓값을 삭제노드로 올리거나 삭제하려는 노드의 우측 최솟값을 삭제노드로 올려야한다.)
public void deleteNode(int value){
if(root == null){
System.out.println("이진트리가 존재하지 않습니다.");
} else{
Node tempNode = root;
Node preNode = null;
// 노드 순회 시작
while(true){
// 노드 내 중복된 값은 존재할수 없다.
if(tempNode.getValue()==value){
break;
}else if(tempNode.getValue()>value){
// 값이 작아 좌측으로 빠지는 경우
if(tempNode.getLeft()==null){
System.out.println("삭제할 값이 존재하지 않습니다.");
break;
}else{
preNode = tempNode;
tempNode = tempNode.getLeft();
}
}else{
if(tempNode.getRight()==null){
System.out.println("삭제할 값이 존재하지 않습니다.");
break;
} else{
preNode = tempNode;
tempNode= tempNode.getRight();
}
}
}
// 삭제할 노드 = tempNode, 삭제할 노드의 부모= preNode
if(tempNode.getLeft()==null && tempNode.getRight()==null){
// 1)삭제할 노드의 자식이 없는 경우
if(preNode.getValue() > tempNode.getValue()){
preNode.setLeft(null);
} else{
preNode.setRight(null);
}
}else if(tempNode.getLeft()!= null && tempNode.getRight()!= null){
// 3)삭제할 노드의 자식이 2개인 경우
// 좌측 최솟값을 해당 값으로 올리는 것으로 한다.
Node rightNode = tempNode.getLeft();
preNode = tempNode;
while(true){
if(rightNode.getRight()== null){
break;
}
preNode = rightNode;
rightNode = rightNode.getRight();
}
tempNode.setValue(rightNode.getValue());
preNode.setRight(null);
} else{
//2)삭제할 노드의 자식이 1개인 경우 해당 노드에 값을 넣어주고 하단 삭제
if(tempNode.getLeft()!=null) tempNode=tempNode.getLeft();
else tempNode = tempNode.getRight();
}
}
}이진트리 순회
이진트리 순회방법에느 전위(pre-order), 중위(In-order),후위(post-order) 순회 3가지가 존재한다.
-
전위순회:
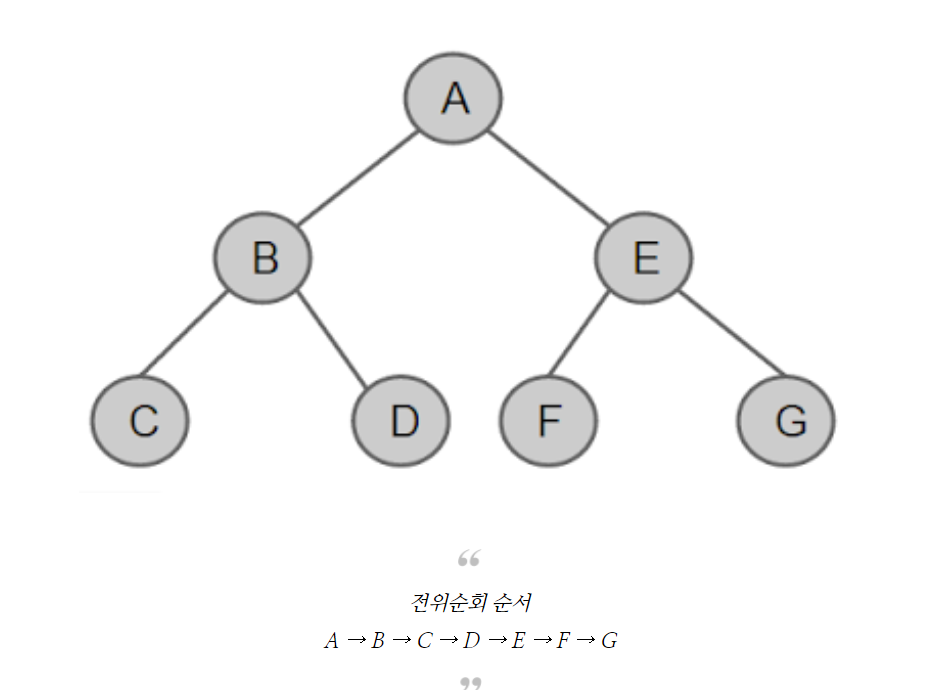
-
중위순회:
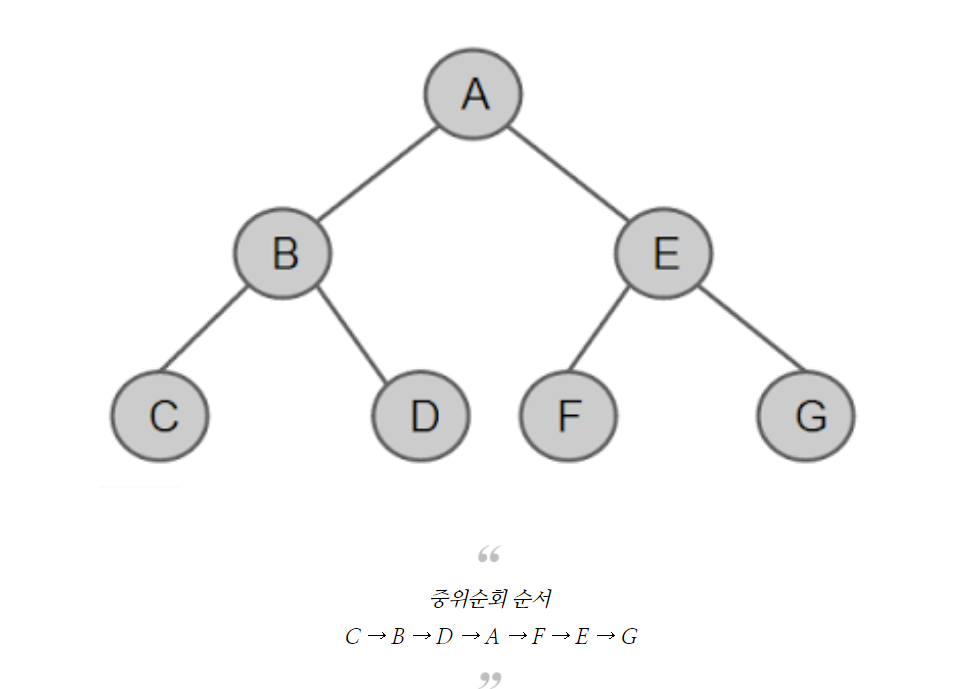
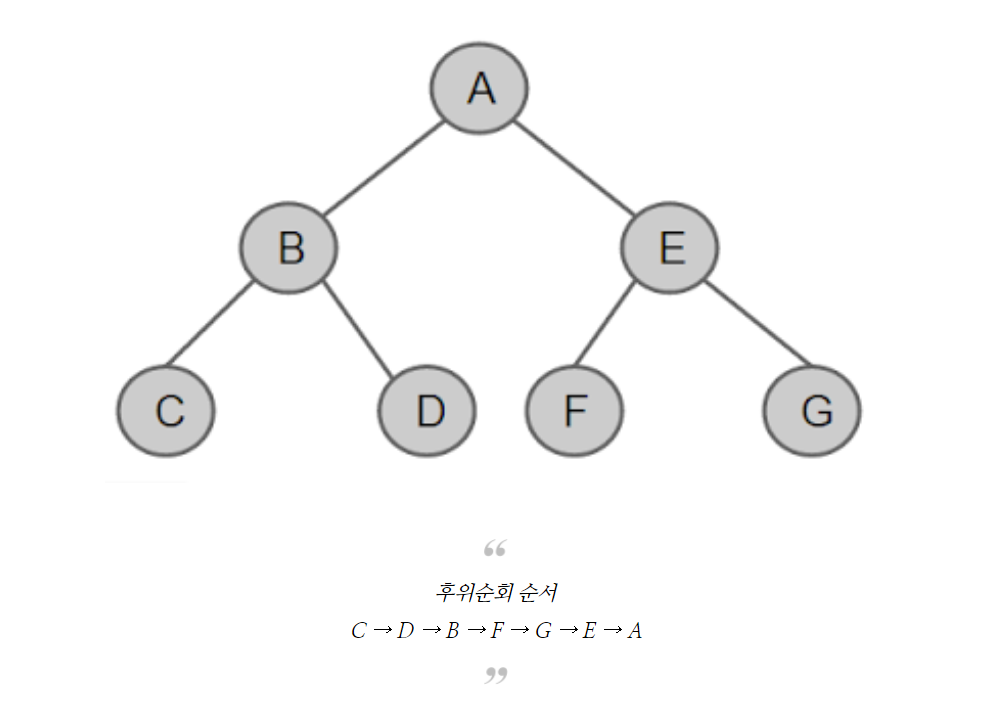
- 후위순회:
// 전위 순회
public void preorderSearch(Node node,int depth){
if(node!=null){
System.out.println(node.getValue()+"->");
preorderSearch(node.getLeft(),depth+1);
preorderSearch(node.getRight(),depth+1);
}
}
// 중위 순회
public void inorderSearch(Node node,int depth){
if(node!=null){
inorderSearch(node.getLeft(),depth+1);
System.out.println(node.getValue()+"->");
inorderSearch(node.getRight(),depth+1);
}
}
// 후위 순회
public void postorderSearch(Node node,int depth){
if(node!=null){
postorderSearch(node.getLeft(),depth+1);
postorderSearch(node.getRight(),depth+1);
System.out.println(node.getValue()+"->");
}
}BFS(넓이우선탐색)
장점:
1. 노드의 수가 적고 깊이가 얕은 경우 빠르게 동작.
2. 깊은우선탐색(DFS)보다 단순 검색 속도가 빠르다.
3. 너비를 우선 탐색하기에 답이 되는 경로가 여로개인 경우에도 최단경로를 보장한다.
4. 최단경로가 존재하면 어느 한경로가 무한히 깊어진다해도 최단경로를 반드시 찾아낸다.
단점:
1. 노드의 수가 많아지면 탐색해야하는 노드가 많아진다.
2.재귀호출을 이용하는 DFS와는 달리 큐에 다음에 탐색할 노드를 저장하기 때문에 저장공간을 많이 차지한다.
public void bfs(Node node) {
//LEFT, RIGHT를 체크할 배열
int [] check_bfs = {0,0};
//BFS는 Queue를 이용한다.
Queue<Node> queue = new LinkedList<Node>();
Node searchNode = root;
//root를 Queue에 넣고 시작
queue.add(searchNode);
Node tempNode = searchNode;
while(true) {
if(check_bfs[0] == 0) {
/**좌측을 조사하지 않았다면 좌측 조사**/
tempNode = queue.poll();
if(tempNode == null ) {
System.out.println("찾으려는 데이터가 없습니다.");
break;
}else if(tempNode.getValue() == node.getValue()){
System.out.print(tempNode.getValue());
break;
}else{
System.out.print(tempNode.getValue() +" → ");
}
searchNode = tempNode.getLeft();
check_bfs[0] = 1; //LEFT 체크
//노드가 null이면 queue에 넣지 않는다.
if(searchNode !=null) {
queue.add(searchNode);
}
}else if(check_bfs[0] == 1 && check_bfs[1] == 0) {
/**우측을 조사하지 않았다면 우측 조사**/
searchNode = tempNode.getRight();
check_bfs[1] = 1; //RIGHT 체크
//노드가 null이면 queue에 넣지 않는다.
if(searchNode !=null) {
queue.add(searchNode);
}
}else {
//LEFT, RIGHT 체크값 초기화
check_bfs[0] = 0;
check_bfs[1] = 0;
}
}
}
DFS(깊이 우선 탐색)
장점:
1. 한 경로상의 노드만을 기억하면 되므로 저장공간의 수요가 적다.
2. 목표노드가 같은 단계에 있을 경우 결과를 빠르게 구할수있다.
단점:
1. 결과 값이 없는 경로에 깊이 빠질 가능성이 있다.
2. 결과 값이 다수 존재할 경우 해당 값이 최단 경로라는 보장이 없다.
public void dfs(Node node) {
//DFS 스택구현
Stack<Node> stack = new Stack<Node>();
//Root로 부터 시작
stack.push(root);
System.out.print(root.getValue() + " → ");
//해당노드를 방문했는지 여부(왼쪽, 오른쪽 모두 체크했을때 해당 맵에 데이터 PUT)
HashMap<Node, Integer> checkMap = new HashMap<Node,Integer>();
//탐색시작
while (true) {
//스택이 비었을 경우 모든 데이터 탐색 완료.
if(stack.isEmpty()) {
System.out.print(" 찾으려는 데이터가 없습니다.");
break;
}
Node curr = stack.peek();
//LEFT 값이 결과 값이면 break;
if((curr.getLeft() != null && curr.getLeft().getValue() == node.getValue())) {
System.out.print(curr.getLeft().getValue());
break;
}
//LEFT가 존재하면서 LEFT에 방문한적이 없으면 PUSH
if (curr.getLeft() != null && !checkMap.containsKey(curr.getLeft())) {
System.out.print(curr.getLeft().getValue() + " → ");
stack.push(curr.getLeft());
continue;
}
//RIGHT 값이 결과 값이면 break;
if((curr.getRight() != null && curr.getRight().getValue() == node.getValue())) {
System.out.print(curr.getRight().getValue());
break;
}
//RIGHT가 존재하면서 RIGHT에 방문한적이 없으면 PUSH
if (curr.getRight() != null && !checkMap.containsKey(curr.getRight())) {
System.out.print(curr.getRight().getValue() + " → ");
stack.push(curr.getRight());
continue;
}
//양쪽에 모두 존재하지 않을 경우 스택에서 POP
checkMap.put(curr, 1);
stack.pop();
}
}
Binary 기본형태
public class BinaryTree {
private Node root = null; // rootNode
/**
* root에 대한 getter/setter
* */
public void setRoot(Node root) {
this.root = root;
}
public Node getRoot() {
return root;
}
/**
* 순회 결과 출력
* */
public void printNode(){
System.out.print("전위순회 시작 : ");
preOrderSearch(root, 0);
System.out.println("종료");
System.out.print("중위순회 시작 : ");
inOrderSearch(root, 0);
System.out.println("종료");
System.out.print("후위순회 시작 : ");
postOrderSearch(root, 0);
System.out.println("종료");
}
}
Test 코드:
package week5;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.*;
class BinarySearchTreeTest {
public BinarySearchTree bTree;
public Node root;
@Test
public void createTree(){
bTree = new BinarySearchTree();
root = new Node(6);
bTree.insertNode(10);
bTree.insertNode(5);
bTree.insertNode(3);
bTree.insertNode(6);
bTree.insertNode(15);
bTree.insertNode(13);
bTree.insertNode(11);
bTree.insertNode(14);
bTree.insertNode(16);
System.out.print("BFS탐색 = ");
bTree.bfs(root);
System.out.print("DFS탐색 = ");
bTree.dfs(root);
System.out.println();
bTree.printNode();
}
}