 # 목표
# 목표
자바의 Input과 Ontput에 대해 학습하세요.
학습할 것 (필수)
스트림 (Stream) / 버퍼 (Buffer) / 채널 (Channel) 기반의 I/O
InputStream과 OutputStream
Byte와 Character 스트림
표준 스트림 (System.in, System.out, System.err)
파일 읽고 쓰기
1. 스트림 (Stream) / 버퍼 (Buffer) / 채널 (Channel) 기반의 I/O
입출력이란?
입출력(I/O)란 Input and Output의 약자로 입력과 출력, 간단히 입출력이라고 한다.
입출력은 컴퓨터 내부 또는 외부장치와 프로그램간의 데이터를 주고 받는것을 말한다.
- 키보드로부터 데이터를 입력받거나
- System.out.println)을 이용해 화면에 출력하거나.
스트림(Stream) 이란?
자바에서 어느 한 쪽에서 다른 쪽으로 데이터를 전달하려면, 두 대상을 연결하고, 데이터를 전송할 수 있는 통로가 필요한데, 이것을 스트림이라 정의한다.
(람다에서의 스트림과는 다른 개념이다.)
- 스트림은 TV와 DVD를 연결하는 입력선, 출력선과 같은 역할을 한다.
스트림이란 데이터를 운반하는데 사용되는 연결통로이다.
스트림은 연속적인 데이터의 흐름을 물에 비유해서 붙여진 이름인데, 여러가지로 물과 유사한 점이 많다.
- 물이 한 쪽 방향으로만 흐르는 것과 같이 스트림은 단방향통신만 가능하기 때문이다.
- 즉, 하나의 스트림으로 입력과 출력을 동시에 처리할수없다.
입력과 출력을 처리하기 위해 입력을 위한 입력 스트림(input stream)과 출력을 위한 출력 스트림(output stream) 모두 2개의 스트림이 필요하다.
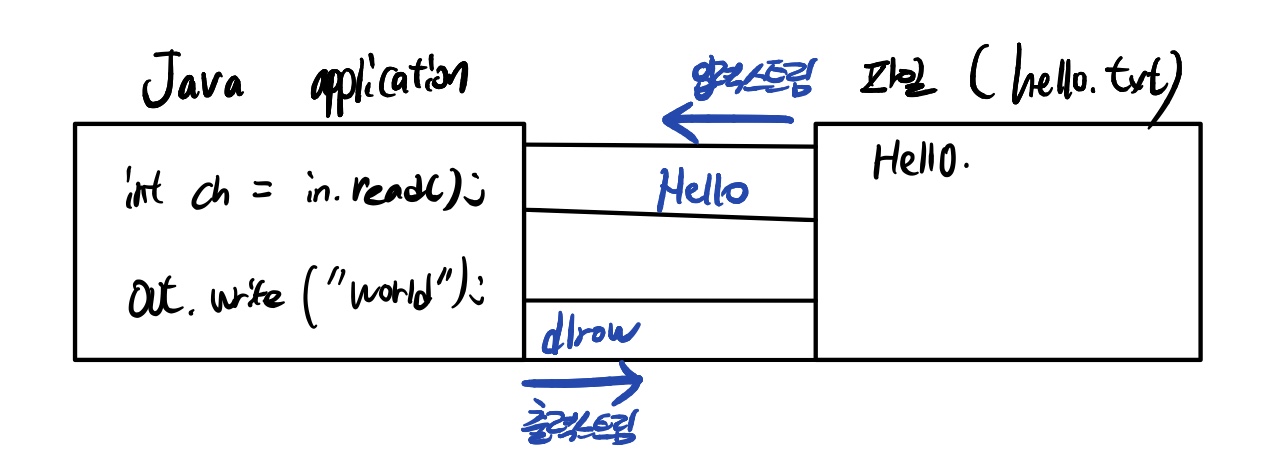
- 스트림은 먼저 보낸 데이터를 먼저 받게 되어 있으며(큐와 같은 FIFO 구조로 되어있다고 생각하면 이해하기 쉽다.)
- 중간에 건너뜀 없이 연속적으로 데이터를 주고 받는다.
- 연속된 데이터의 흐름으로 입출력 진행시 다른 작업을 할 수 업슨 블로킹(blocking) 상태가 된다.
- 입출력 대상을 변경하기 편하며 동일한 프로그램 구조를 유지할수있다.
자바 NIO (New I/O)란?
- 자바 1.4 버전부터 추가된 API로 넌블로킹(Non-blocking) 처리가 가능하며, 스트림이 아닌 채널(Channel)을 사용한다.
버퍼란?
- byte,char,int 등 기본 데이터 타입을 저장할 수 있는 저장소로써, 배열과 마찬가지로 제한된 크기에 순서대로 데이터를 저장한다.
- 버퍼는 데이터를 저장하기 위한 것이지만, 실제로 버퍼가 사용되는 것은 채널을 통해서 데이터를 주고 받을때 쓰인다.
- 채널을 통해서 소켓,파일 등에 데이터를 전송할 때나 읽어올 떄 버퍼를 사용하게 됨으로써 가비지량을 최소화 시킬수있게 되며, 이는 가비지 컬렉션 회수를 줄임으로서 서버의 전체 처리량을 증가시켜준다.
속성:
private int mark = -1;
private int position = 0;
private int limit;
private int capacity;| 속성 | 설명 |
|---|---|
| 용량(capacity) | 버퍼의 용량으로 버퍼의 총 크기를 의미한다. |
| 위치(position) | 버퍼에서 다음에 읽거나 쓰는 부분을 의미한다. |
| 제한(limit) | 실제 사용할수 있는 버퍼의 크기를 의미한다. |
| 마크(mark) | reset() 사용시 돌아갈 위치를 의미한다. |
Buffer 클래스 메서드
| 메서드 | 설명 |
|---|---|
| clear() | 모든 속성값 초기화 |
| rewind() | position 과 mark 값 초기화. |
| flip() | limit을 position으로 설정, position은 0으로 이동 mark 초기화 |
| reset() | position을 mark 위치로 이동 |
| mark() | 현재 위치를 mark에 저장 |
| capacity() | 버퍼의 전체 크기 리턴 |
기타 중요 메서드(ByteBuffer 클래스)
| 메서드 | 설명 |
|---|---|
| allocate(int capacity) | capacity 크기의 논다이렉트 버퍼를 생성 |
| allocateDirect(int capacity) | ByteBuffer 클래스에만 있는 메서드로 다이렉트 버퍼를 생성. |
| asXXXBuffer() | 다이렉트 버퍼생성은 ByteBuffer 클래스만 가능하지만 해당 함수를 사용하면 ByteBuffer를 다른 유형의 버퍼로 변환이 가능하다.(하단 그림참고, 다른 데이터타입의 버퍼가 다이렉트 버퍼가 가능하게 만들수있음) |
| wrap(byte[] array) | 바이트 배열을 사용하여 버퍼를 생성 |
| getXXX() /putXXX() | 클래스의 getter/setter라고 생각하면된다. get/put에는 상대적인 것과 절대적인 것이 존재하는데, 매개변수가 있을 경우 절대적인 것이다. (절대적: 해당 position에 직접 세팅) |
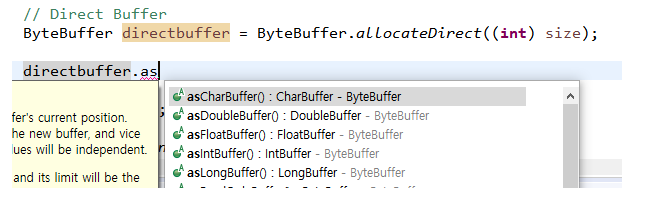
NIO 버퍼는 기본적으로 많은 메서드를 가지고 있따. 그러므로 여기서는 몇가지 속성과 메서드만을 참고하고 나머지는 아래 Java API 사이트를 참고하자.
채널이란?
데이터가 통과하는 쌍방향 통로이며, 채널에서 데이터를 주고 받을때 사용되는것이 버퍼이다.
스트림과 다르게 채널은 비동기적으로 닫고 중단할수있다.
종류
| 종류 | 설명 |
|---|---|
| FileChannel | 파일 입출력 채널 |
| Pipe.SinkChannel | 파이프에 데이터를 출력하는 채널 |
| Pipe.SourceChannel | 파이프로부터 데이터를 입력받는 채널 |
| ServerSocketChannel | 클라이언트의 연결 요청을 처리하는 서버 소켓 채널 |
| SocketChannel | 소켓과 연결된 채널 |
| DatagramChannel | Datagram소켓과 연결된 채널 |
채널 블럭킹(Blocking) 서버예제
서버:
package me.whiteship.livestudy.week13;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.nio.charset.Charset;
public class Server {
static ServerSocketChannel serverSocketChannel = null;
public static void main(String[] args) {
try {
serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.configureBlocking(true);
serverSocketChannel.bind(new InetSocketAddress(10000));
while(true){
SocketChannel socketChannel = serverSocketChannel.accept();
System.out.println("connected :" + socketChannel.getRemoteAddress());
// 클라이언트로부터 입출력받기
Charset charset = Charset.forName("UTF-8");
ByteBuffer byteBuffer = ByteBuffer.allocate(128);
socketChannel.read(byteBuffer);
byteBuffer.flip();
System.out.println("received Data: " + charset.decode(byteBuffer).toString());
byteBuffer = charset.encode("hello, My Client!");
socketChannel.write(byteBuffer);
System.out.println("Sending success");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
클라이언트:
package me.whiteship.livestudy.week13;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SocketChannel;
import java.nio.charset.Charset;
public class Client {
static SocketChannel socketChannel = null;
public static void main(String[] args) {
try {
socketChannel = SocketChannel.open();
socketChannel.configureBlocking(true);
// 서버연결
socketChannel.connect(new InetSocketAddress(10000));
Charset charset = Charset.forName("UTF-8");
// 서버에 입출력
ByteBuffer byteBuffer = charset.encode("Hello Server!");
socketChannel.write(byteBuffer);
byteBuffer = ByteBuffer.allocate(128);
socketChannel.read(byteBuffer);
byteBuffer.flip();
System.out.println("received Data : " + charset.decode(byteBuffer).toString());
// 소켓 닫기
if(socketChannel.isOpen()){
socketChannel.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}채널에 대한 예제로 서버와 클라이언트 간의 입출력을 보여주는 예제이다.
셀럭터를 사용하지 않은 Blocking 방식으로 서버는 accept() 메서드가 호출되는 순간부터 클라이언트를 기다려야한다. 다시 말하면 이는 클라이언트 하나당 하나의 스레드를 할당해줘야하는 말과 같은데 이는 매우 비효율적인 방법이다. 그래서 셀렉터를 사용하여 넌블럭킹되게 변경해주자.
Selector
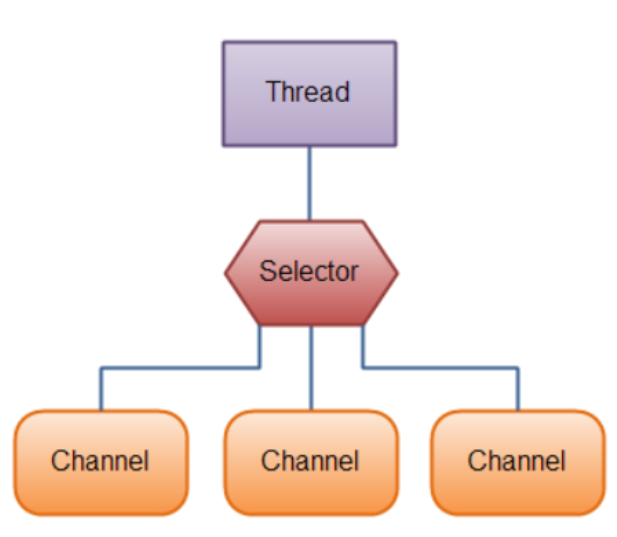
셀렉터는 하나의 쓰레드에서 다수의 채널을 처리할 수 있는 기술을 의미한다. 멀티플렉스 IO를 할수있게 만드는 기술로 이를 통해 우리는 좀더 적은 CPU와 자원으로 채널을 관리할수있다.
I/O VS NIO
-
IO의 방식으로 각각의 스트림에서 read()와 write()가 호출이 되면 데이터가 입력되고, 데이터가 출력되기전까지 쓰레드는 블로킹(멈춤) 상태가 된다. 이렇게 되면 작업이 끝날때까지 기다려야하며, 그 이전에는 해당 IO스레드는 사용할수없게되고, 인터럽트도 할 수 없다. 블로킹을 빠져나오려면 스트림을 닫는 방법 밖에 없다.
-
NIO의 블로킹 상태에서는 Interrupt를 이용하여 빠져나올 수 있다.
| 구분 | I/O | NIO |
|---|---|---|
| 입출력 방식 | 스트림 | 채널 |
| 버퍼방식 | Non-buffer | buffer |
| 비동거 방식 지원 | X | O |
| Blocking/Non-Blocking 방식 | Blocking Only | Both |
| 사용케이스 | 연결 클라이언트가 적고, IO가 큰 경우(대용량) | 연결 클라이언트가 많고, IO 처리가 작은 경우(저용량) |
1. 스트림 vs 채널트림 vs 채널
-
I/O는 스트림 기반이다.
- 스트림은 입력 스트림과 출력 스트림으로 구분되어 있기 때문에 데이터를 입출력하기 위해서 입출력 스트림을 생성해야 한다.
-
NIO는 채널 기반이다.
- 채널은 스트림과 달리 양방향으로 입출력이 가능하다. 그렇기 때문에 입출력을 위한 별도의 채널을 만들 필요가 없다.
2. Buffer vs non-buffer:
- I/O에서 출력 스트림이 1바이트를 쓰면 입력 스트림이 1바이트를 읽는다. 이러한 시스템은 대체로 느리다.
- 이것보다 버퍼(메모리 저장소)를 사용해서 복수 개의 바이트를 한꺼번에 입력받고 출력하는 것이 성능에 이점을 가지게 된다.
- 그래서 I/O는 버퍼를 제공해주는 보조 스트림인 BufferedInputStream,OutputStream을 연결해 사용한다.
- NIO는 기본적으로 버퍼를 사용해서 입출력을 하기 때문에 I/O보다 높은 성능을 가진다.
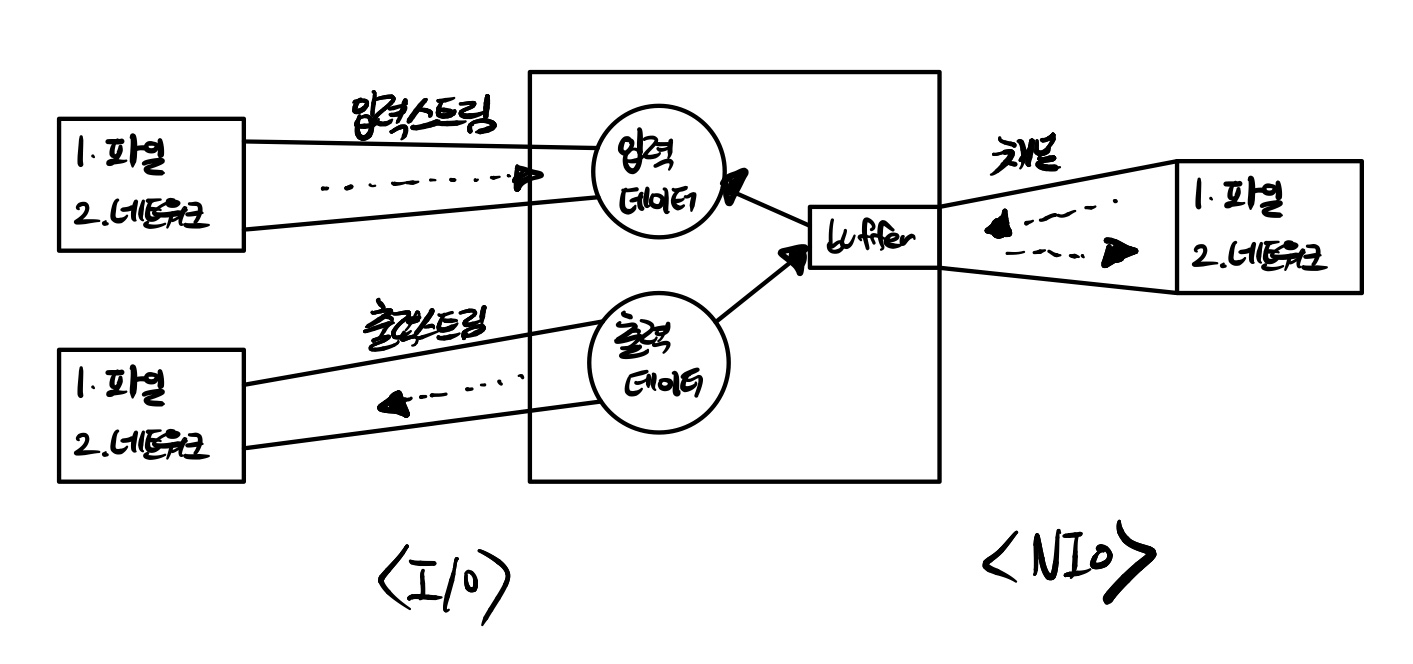
- I/O는 스트림에서 읽은 데이터를 즉시 처리한다.
- 스트림으로 부터 입력된 전체 데이터를 별도로 저장하지않으면, 입력된 데이터의 위치를 이동해가면서 자유롭게 이용할수없다.
- NIO는 읽은 데이터를 무조건 버퍼에 저장한다.
- 버퍼내에서 데이터의 위치이동을 해가면서 필요한 부분만 읽고 쓸수있다.
3. Blocking vs Non-blocking
- I/O는 블로킹된다.
- 입력스트림의 read() 메서드를 호출하면 데이터가 입력되기 전까지 Thread는 블로킹(대기상태)가 된다.
- 마찬가지로 출력 스트림의 write() 메서드를 호출하면 데이터가 출력되기 전까지 Thread는 블로킹된다.
- I/O Thread가 블로킹되면 다른 일을 할수없고 블로킹을 빠져나오기 위해 인터럽트도 할수없다.
- 블로킹을 빠져나오는 유일한 방법은 스트림을 닫는것이다.
- NIO는 블로킹과 넌블로킹 특징을 모두 가진다.
- I/O 블로킹과 NIO 블로킹의 차이점은 NIO 블로킹은 Thread를 인터럽트함으로써 바져나올수있다.
- NIO의 넌블로킹은 입출력 작업 준비가 완료된 채널만 선택해서 작업 Thread가 처리하기 때문에 작업 Thread가 블로킹 되지 않는다
- 작업준비가 완료되었다는 뜻은 지금 바로 읽고 쓸수있는 상태를 말한다.
-> NIO 넌블로킹의 핵심 객체는 mutiplexor인 셀렉터이다. 셀렉터는 복수 개의 채널 중에서 준비 완료된 채널을 선택하는 방법을 제공해준다.
4. 기존 IO의 단점(속도가 느리다.)

(https://www.youtube.com/watch?v=LmWvwbjynhg&t=3647s)
유저 영역은 실행 중인 프로그램이 존재하는 제한된 영역(하드웨어에 직접 접근 불가)을 말한다. 반대로 커널 영역은 하드웨어에 직접 접근이 가능하고 다른 프로세스를 제어할 수 있는 영역을 말한다.
자바 IO 프로세스
- 프로세스가 커널에 파일 읽기 명령을 내림
- 커널은 시스템콜(read())을 이용해 디스크 컨트롤러가 물리적 디스크로 부터 읽어온 파일 데이터를 커널 영역안의 버퍼에 쓴다
(DMA: CPU의 도움없이 물리적 디스크에서 커널영역의 버퍼로 데이터를 읽어오는것) - 모든 파일 데이터가 버퍼에 복사되면 다시 프로세스 안의 버퍼로 복사한다.
- 프로세스 안의 버퍼의 내용을 사용한다.
위의 프로세스에서 3번 과정이 너무나 비효율적이다. 커널안의 버퍼 데이터를 프로세스 안으로 다시 복사하기 때문이다.
5. Direct vs Non-direct buffer:
| 구분 | Direct Buffer | Non Direct Buffer |
|---|---|---|
| 사용공간 | OS의 메모리 | JVM 힙 메모리 |
| 버퍼의 생성속도 | 느리다 | 빠르다 |
| 버퍼의 크기 | 크다 | 작다 |
| I/O 성능 | 높다 | 낮다 |
| Use | 한번생성한뒤재사용을 할경우 | 빈번하게 계속해서 사용해야 할 경우 |
Direct와 Non Direct의 속도차이를 비교
package me.whiteship.livestudy.week13;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
//Direct와 Non Direct의 속도차이를 비교하는 예제
public class Input {
public static void main(String[] args) {
try {
Path path = Paths.get("C:\\test.txt");
long size = Files.size(path);
FileChannel fileChannel = FileChannel.open(path);
// Non-Direct Buffer
ByteBuffer nonDirectBuffer = ByteBuffer.allocate((int) size);
// Direct Buffer
ByteBuffer directBuffer = ByteBuffer.allocateDirect((int) size);
long start,end;
start = System.nanoTime();
for (int i = 0; i < 100; i++) {
fileChannel.read(nonDirectBuffer);
nonDirectBuffer.flip();
}
end = System.nanoTime();
System.out.println("Non-Direct Buffer : " + (end-start)+ "ns");
start = System.nanoTime();
for (int i = 0; i < 100; i++) {
fileChannel.read(directBuffer);
directBuffer.flip();
}
end = System.nanoTime();
System.out.println("Direct Buffer : " + (end-start)+ "ns");
fileChannel.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}output:
Non-Direct Buffer : 3326400ns
Direct Buffer : 421300ns추가. 커널 Buffer
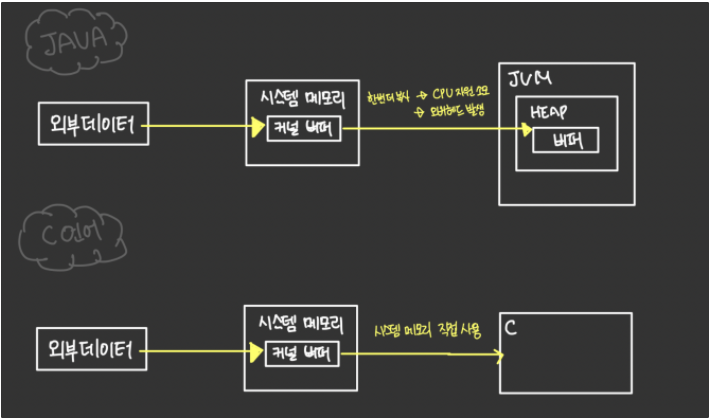
(https://www.notion.so/I-O-094fb5c7f8fa41fcb9876586ed3d92db)
커널 버퍼란 운영체제가 관리하는 메모리 영역에 생성되는 버퍼 공간으로,
자바는 외부데이터를 가져올때 OS의 메모리 버퍼에 먼저 담았다가 JVM 내의 버퍼에 한번 더 옮겨줘야하기 때문에 시스템 메모리를 직접 다루는 C언어에 비해 입출력이 느리다.
이러한 단점을 개선하기 위해 나온 ByteBuffer 클래스의 allocateDirect() 메서드를 사용하면 커널 버퍼를 사용할 수 있다. 그 외로 만들어지는 버퍼는 모두 JVM 내에 생성되는 버퍼이다.
2. InputStream과 OutputStream
바이트 기반 스트림
입출력 스트림의 부모 InputStream,OutputStream
- InputStream:
- 바이트 기반 입력 스트림의 최상위 추상 클래스- 모든 바이트 기반 입력 스트림은 이 클래스를 상속 받아서 만들어진다.
- 버퍼, 파일, 네트워크 단에서 입력되는 데이터를 읽어오는 기능을 수행한다.
| 메서드 | 설명 |
|---|---|
| read() | 입력 스트림으로 부터 1바이트를 읽어서 바이트를 리턴 |
| read(byte[] b) | 입력 스트림으로부터 읽은 바이트들을 매개값으로 주어진 바이트 배열 b에 저장하고 실제로 읽은 바이트 수를 리턴 |
| read(byte[] b, int off,int len) | 입력 스트림으로 부터 len개의 바이트만큼 읽고 매개값으로 주어진 배열 b[off]부터 len개까지 저장. 그리고 실제로 읽은 바이트 수인 len개를 리턴. 만약 len개를 모두 읽지 못하면 실제로 읽은 바이트 수를 리턴 |
| close() | 사용한 시스템 자원을 반납하고 입력 스트림 닫기 |
- InputStream의 메서드:

이미 읽은 데이터를 되돌려서 다시 읽을 수 있는 방법
-> mark(), reset()
- OutputStream:
- 바이트 기반 출력 스트림의 최상위 추상 클래스
- 모든 바이트 기반 출력 스트림은 이 클래스를 상속받아서 만들어진다.
- 버퍼, 파일 ,네트워크 단으로 데이터를 내보내는 기능을 수행한다.
| 메서드 | 설명 |
|---|---|
| write(int b) | 출력 스트림으로부터 1바이트를 보낸다. b의 끝 1바이트 |
| write(byte[] b | 출력 스트림으로부터 주어진 바이트 배열 b의 모든 바이트를 보낸다. |
| write(byte[] b,int off,int len | 출력 스트림으로 주어진 바이트 배열 b[off] 부터 len 개까지의 바이트를 보낸다. |
| flush() | 버퍼에 잔류하는 모든 바이트를 출력한다. |
| close() | 사용한 시스템 자원을 반납하고 출력 스트림 닫기 |
-
OutputStream의 메서드:

-
버퍼가 있는 출력스트림이 있는 경우 flush()를 이용해 버퍼에 있는 모든 내용을 출력 소스에 쓴다. -> 버퍼가 있는 출력스트림에만 의미가 있으며, OutputStream에 정의된 flush()는 의미가 없다.
-
close():
프로그램이 종료될 떄 사용하고 닫지 않은 스트림을 jvm이 자동적으로 닫아주지만, 스트림을 사용해서 모든 작업을 마치고 난후에는 close()를 호출해서 반드시 닫아주어야 한다. -
InputStream 과 OutputStream 비교:
| InputStream | OutputStream |
|---|---|
| abstract int read() | abstract void write(int b) |
| int read(byte[] b) | void write(byte[] b) |
| int read(byte[] b, int off, int len) | void write(byte[] b , int off ,int len ) |
스트림은 바이트단위로 데이터를 전송하며 입출력 대상에 따라서 다음과 같은 입출력 스트림이 있다.
입력 스트림과 출력 스트림의 종류:
| 입력 스트림 | 출력 스트림 | 입출력 대상의 종류 |
|---|---|---|
| FileInputStream | FileOutputStream | 파일 |
| ByteArrayInputStream | ByteArrayOutputStream | 메모리(byte)배열 |
| PipedInputStream | PipedOutputStream | 프로세스(프로세스간 통신) |
| AudtioInputStream | AudioOutputStream | 오디오 장치 |
어떠한 대상에 대해 작업을 할 것인지,
입력을 할 것인지 출력을 할 것인지에 따라 해당 스트림을 선택해서 사용할 수 있다.
위 입출력 스트림은 각각 InputStream 과 OutputStream의 자손들이며, 각각 읽고 쓰는데 필요한 추상 메서드를 자신에 맞게 구현해놓은 구현체이다.
InputStream과 OutputStream에 정의된 읽기와 쓰기를 수행하는 메소드
read의 반환타입이 byte가 아니고 int인 이유?
read() 반환값의 범위가 0~255 와 -1 이기 때문이다.
위 Input, OutputStream의 메소드 사용법만 잘 알고 있다면, 데이터를 읽고 쓰는 것은 대상의 종류에 관계없이 간단할 일이 될것이다.
-
InputStream의 read()와 OutputStream의 write(int b) 는 입출력의 대상에 따라 읽고 쓰는 방법이 다를 것이기 때문에, 각 상황에 알맞게 구현하라는 의미에서 추상 메서드로 정의되어있다.
-
read()와 write(int b)를 제외한 나머지 메서드들은 추상 메서드가 아니니까 굳이 추상메서드인 read()와 write(int b)를 구현하지 않아도 이들을 사용하면 될 것이라고 생각할수있지만,
-
사실 추상메서드인 read()와 write(int b)를 이용해서 구현한 것들임으로 read()와 write(int b)가 구현되어 있지 않으면 이들은 아무런 의미가 없다.
InputStream의 실제코드 일부분
public abstract class InputStream{
...
// 입력스트림으로 부터 1byte를 읽어서 반환한다. 읽을 수 없으면 -1을 반환한다.
abstract int read();
// 입력스트림으로부터 len개의 byte를 읽어서 byte배열 b의 off위치부터 저장한다.
int read(byte[] b, int off, int len){
...
for(int i = off ; i < off + len ; i++){
// read()를 호출해서 데이터를 읽어서 배열을 채운다.
b[i] = (byte)read();
}
...
// 입력스트림으로부터 byte배열 b의 크기만큼 데이터를 읽어서 배열 b에 저장한다.
int read(byte[] b){
return read(b, 0, b.length);
}
}
...
}read(byte[] b, int off, int len) 코드를 보면 read()를 호출하고 있음을 볼 수 있다.
read()가 추상메서드이지만, 이처럼 read(byte[] b, int off, int len) 내에서 read()를 호출할수 있다.
read(byte[] b)도 read(byte[] b, int off, int len)를 호출하지만, read(byte[] b, int off, int len)가 다시 추상메서드 read()를 호출하기 때문에 read(byte[] b)도 추상메서드 read()를 호출한다고 할 수 있다.
결론적으로, read()는 반드시 구현되어야 하는 핵심적인 메서드이고, read()없이는 다른 메서드는 의미가 없다.
ByteArrayInputStream 과 ByteArrayOutputStream
ByteArrayInputStream 과 ByteArrayOutputStream은 메모리, 즉 바이트배열에 데이터를 입출력하는데 사용된다.
주로 다른 곳에 입출력하기 전에 데이터를 임시로 바이트 배열에 담아서 변환 등의 작업을 하는데 사용된다.
(스트림의 종류가 달라도 읽고 쓰는 방법은 동일함으로 스트림에 읽고 쓰는 방법을 잘 익혀두자.)
package me.whiteship.livestudy.week13;
import java.io.*;
import java.util.Arrays;
public class Example1 {
public static void main(String[] args) {
System.out.println("hi");
byte[] arr1 = {0,1,2,3,4,5,6,7,8,9};
ByteArrayInputStream inputStream = new ByteArrayInputStream(arr1);
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
int data;
while((data = inputStream.read())!=-1){
outputStream.write(data);
}
byte[] arr2 = outputStream.toByteArray();
System.out.println(Arrays.toString(arr1));
System.out.println(Arrays.toString(arr2));
}
}output:
hi
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Process finished with exit code 0- 바이트 배열은 사용하는 자원이 메모리 밖에 없으므로 가비지컬렉터에 의해 자동적으로 자원을 반환함으로 close()를 이용해 스트림을 닫지 않아도된다.
- 하지만, read()와 write(int b)를 사용하기 때문에 한 번에 1byte만 읽고 쓰는게 좀 아깝다.
그래서 read(byte[] b, int off, int len) 와 void write(byte[] b, int off, int len) 활용해보자.
package me.whiteship.livestudy.week13;
import java.io.*;
import java.util.Arrays;
public class Example1 {
public static void main(String[] args) {
System.out.println("hi");
byte[] arr1 = {0,1,2,3,4,5,6,7,8,9};
ByteArrayInputStream inputStream = new ByteArrayInputStream(arr1);
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
int data;
byte[] temp = new byte[arr1.length];
// 읽어온 데이터를 배열 temp에 담는다.
inputStream.read(temp,0,temp.length);
// temp[5]부터 5개의 데이터를 outputStream에 write한다.
outputStream.write(temp,5,5);
byte[] arr2 = outputStream.toByteArray();
System.out.println(Arrays.toString(arr1));
System.out.println(Arrays.toString(temp));
System.out.println(Arrays.toString(arr2));
}
}hi
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[5, 6, 7, 8, 9]
Process finished with exit code 0배열을 이용한 입출력은 작업의 효율을 증가시키므로 가능하면 입출력 대상에 따라 알맞은 크기의 배열을 사용하는 것이 좋다.
고정된 배열크기를 활용해 위 예제를 변형해보자.
package me.whiteship.livestudy.week13;
import java.io.*;
import java.util.Arrays;
public class Example1 {
public static void main(String[] args) {
System.out.println("hi");
byte[] arr1 = {0,1,2,3,4,5,6,7,8,9};
ByteArrayInputStream inputStream = new ByteArrayInputStream(arr1);
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
byte[] temp = new byte[4];
byte[] arr2= null;
System.out.println(Arrays.toString(arr1));
try {
while(inputStream.available()>0){
inputStream.read(temp);
System.out.println(Arrays.toString(temp));
outputStream.write(temp);
arr2 = outputStream.toByteArray();
System.out.println(Arrays.toString(arr2));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}output:
hi
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[0, 1, 2, 3]
[0, 1, 2, 3]
[4, 5, 6, 7]
[0, 1, 2, 3, 4, 5, 6, 7]
[8, 9, 6, 7]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 6, 7]
Process finished with exit code 0- available()은 blocking없이 읽어 올 수 있는 바이트의 수를 반환한다.
위 예제의 결과가 원하는 대로 나왔나?
마지막 while loop 단계의 temp 배열과 output source 출력결과를 보자.
[8, 9, 6, 7]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 6, 7]- 마지막에 읽은 배열의 9번째와 10번째 즉 8,9만 출력해야되는데
- temp 배열에 남아있던 6,7까지 출력되었다.
- 바로 직전의 loop에서 temp 배열에 담긴 내용은 [4,5,6,7]
- 이후 읽어들인 8,9 이후 temp 배열에 담긴 내용은 [8,9,6,7]이 된다.
원하는 결과를 얻기 위해서는 배열 전체를 출력하는 코드에서 읽어온 만큼만 출력하는 코드로 변경되어야 한다.
int len = inputStream.read(temp);
System.out.println(Arrays.toString(temp));
outputStream.write(temp,0,len);FileInputStream과 FileOutputStream
파일에 입출력을 하기 위한 스트림이다.

package me.whiteship.livestudy.week13;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class Example2 {
public static void main(String[] args) throws IOException {
FileInputStream fileInputStream = new FileInputStream(args[0]);
int data = 0;
while( (data=fileInputStream.read())!=-1){
char c = (char)data;
System.out.println(c);
}
}
}실행시 program arguments(파일경로)를 추가하여 실행
output:
I will be a best
I am gonna great
Process finished with exit code 0- read() 메서드의 반환값이 int형(4byte)이지만, 입력값이 없음을 알리는 -1을 제외하고는 0~255(1byte)범위의 정수값임으로,
- char형(2byte)으로 변환하여도 손실되는 데이터는 없다.
package me.whiteship.livestudy.week13;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class Example2 {
public static void main(String[] args) throws IOException {
FileInputStream fileInputStream = new FileInputStream(args[0]);
FileOutputStream fileOutputStream = new FileOutputStream(args[1]);
int data = 0;
while( (data=fileInputStream.read())!=-1){
fileOutputStream.write(data);
}
FileInputStream fileInputStream1 = new FileInputStream(args[1]);
while(( data= fileInputStream1.read())!=-1){
char c = (char)data;
System.out.print(c);
}
fileInputStream.close();
fileOutputStream.close();
}
}
output:
I will be a best
I am gonna great
Process finished with exit code 0
데코레이터 패턴:
객체에 추가적인 요건을 동적으로 첨가한다. 데코레이터는 서브클래스를 만든는것을 통해서 기능을 유연하게 확장할 수 있는 방법을 제공한다.
- java.io 패키지는 데코레이터 패턴으로 만들어졌다.
- 데코레이터 패턴이란, A클래스에서 B클래스를 생성자로 받아와서, B클래스에 추가적인 기능을 덧붙여서 제공하는 패턴이다.
BufferedReader 클래스
private Reader in;
public BufferedReader(Reader in){
this(in,defaultCharBufferSize)
}- BufferedReader는 Reader의 하위 클래스 중 하나를 받아와서, 버퍼를 이용한 기능을 추가한 기능을 제공한다.
- BufferedReader처럼 출력을 담당하는 래퍼 클래슨느 출력을 하는 주체가 아니라 도와주는 역할이다.
- Stream을 사용한 클래스들에서 이렇게 도와주는 클래스들을 보조 스트림이라 한다.
보조 스트림:
- 스트림의 기능을 보완하기 위해 보조 스트림이라는 것이 제공된다.
- 보조스트림은 실제 데이터를 주고받는 스트림이 아니기 때문에 데이터를 입출력할수 있는 기능은 없지만 스트림의 기능을 향상시키거나 새로운 기능을 추가할수있다.
- 즉, 스트림을 먼저 생성한 다음에 이를 이용해 보조스트림을 생성해서 활용한다.
Buffer를 사용하면 좋은이유 에대한 근본적인 이유를 고민해보자
Buffer를 사용하면 좋은이유: 차이점과 성능상의 장점이 있는지에 대한 이유가 중요
- 속도가 왜 빨라질까?
- 모아서 보내면 왜 빨라질까?
- 한 바이트씩 바로바로 보내는 것이 아니라 버퍼에 담았다가 한번에 모아서 보내는 방법인데 왜 이렇게 하는걸까?
- 입출력횟수가 포인트이다.
- 단순히 모아서 보낸다고 이점이 있는 것이 아니다 -> 시스템콜의 횟수가 줄어들었기 때문에 성능상 이점이 생기는 것이다.
- OS 레벨에 있는 시스템 콜의 횟수 자체를 줄이기 때문에 성능이 빨라지는 것이다.
예)
test.txt라는 파일을 읽기 위해 FileInputStream을 입력성능을 향상시키기 위해 버퍼를 사용하는 보조스트림인 BufferedInputStream을 사용할수있다.
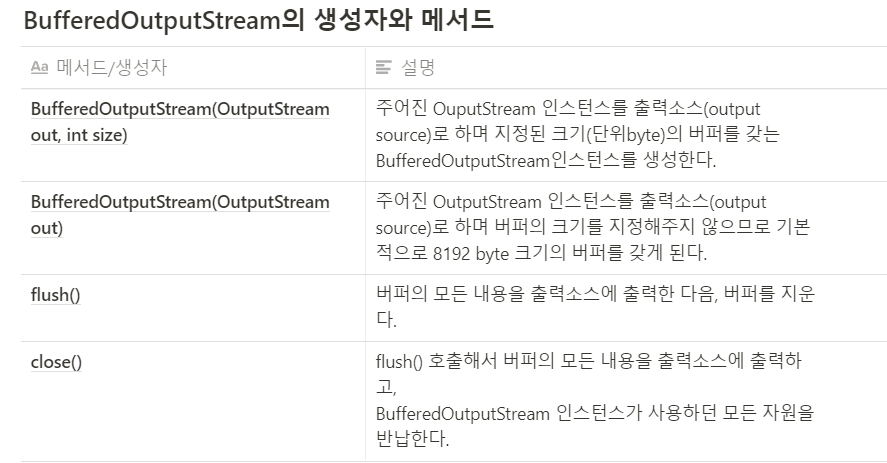
BufferedInputStream과 BufferedOutputStream:
스트림의 입출력 효율을 높이기 위해 버퍼를 사용하는 보조스트림
한 바이트씩 입출력하는 것보다 버퍼(바이트배열)을 이용해 한 번에 여러바이트를 입출력하는 것이 성능상 이점이 있으므로, 대부분의 입출력 작업에 사용된다.

버퍼의 크기는 입력소스로부터 한 번에 가져올 수 있는 데이터의 크기로 지정하면 좋다.
보통, 입력소스가 파일인 경우 8192(8kb)정도의 크기로 하는것이 보통이며, 버퍼의 크기를 변경해가며 테스트하면 최적의 크기를 알아낼수있다.
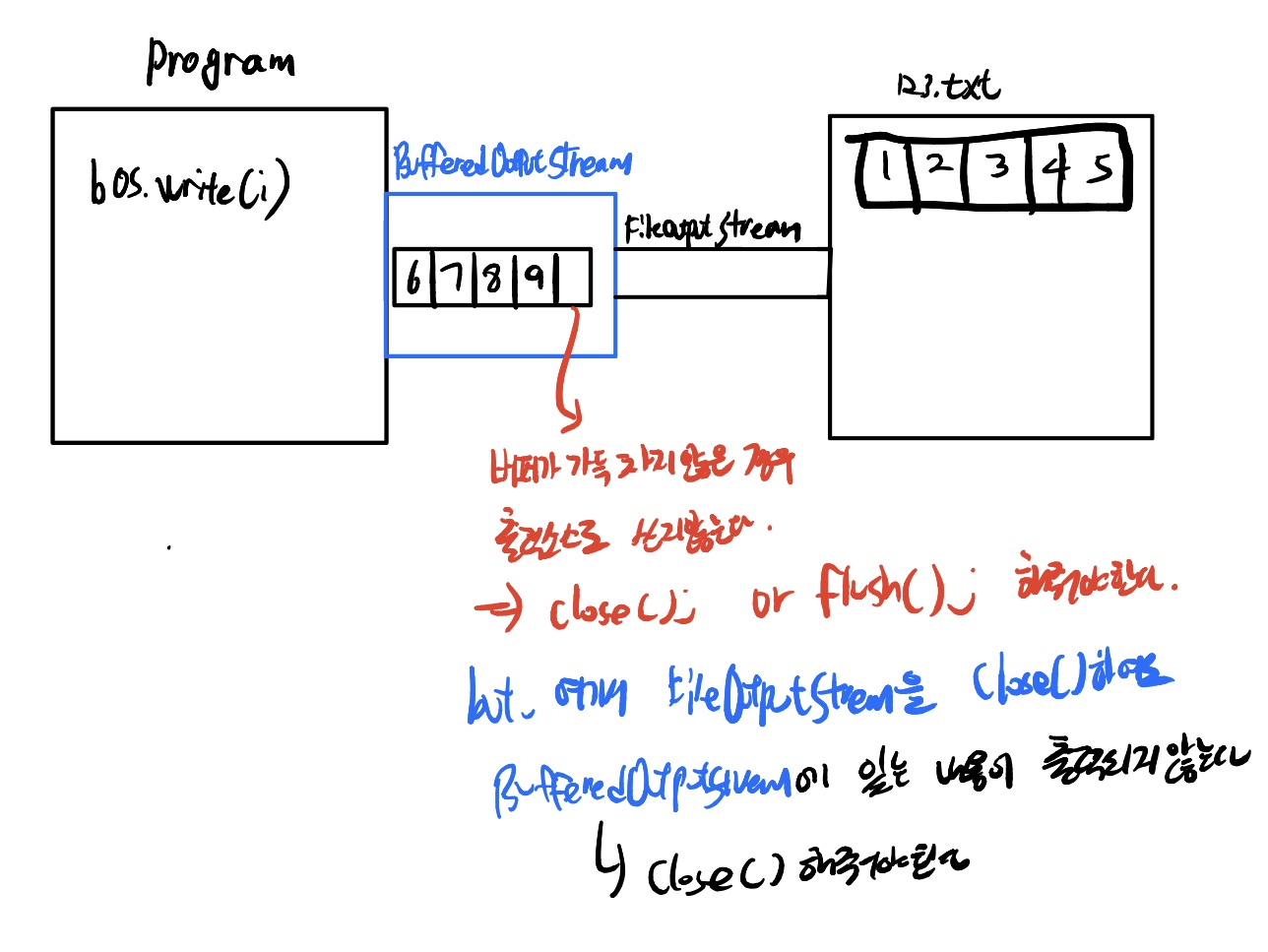
Input의 입력소스로부터 데이터를 읽을때와는 반대로,
프로그램에서 write메서드를 이용한 출력이 BufferedOutputStream의 버퍼에 저장된다
버퍼가 가득 차면, 그 떄 버퍼의 모든 내용을 출력소스에 출력하며, 그 이후 버 퍼를 다시 비우고 다시 프로그램으로부터의 출력을 저장할 준비를 한다.
버퍼가 가득 찼을때만 출력소스에 출력을 하기 때문에, 마지막 출력부분이 출력소스에 쓰이지 못하고 BufferedOutputStream의 버퍼에 남아 있는 채로 프로그램이 종료될수있다는 점을 주의해야 한다.
-> 작업을 마치면 close()나 flush()를 호출해서 마지막 버퍼에 있는 모든 내용이 출려곳스에 출력되도록 해야한다.
package me.whiteship.livestudy.week13;
import java.io.*;
public class Example1 {
public static void main(String[] args) {
try {
// 먼저 기반 스트림을 생성한다.
FileInputStream fileInputStream = new FileInputStream("test.txt");
// 기반 스트림을 이용해 보조 스트림을 생성한다.
BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream);
// Buffered** Stream 생성시 사이즈도 정의하여 생성할수 있다. 2번째 파라미터에 넣어주면 된다.
// default : 8192
BufferedInputStream bis = new BufferedInputStream(fileInputStream,8192);
try {
bufferedInputStream.read();
} catch (IOException e) {
e.printStackTrace();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}코드만 보았을때 보조스트림인 BufferedInputStream이 입력 기능을 수행하는 것처럼 보이지만,
실제 입력 기능은 BufferedInputStream과 연결된 FileInputStream이 수행한다.
BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream);- BufferedInputStream은 버퍼만 제공한다. 버퍼를 사용한 입출력과 사용하지 않은 입출력은 성능상 상당한 차이가 나기 때문에 대부분 버퍼를 이용한 보조 스트림을 사용하게 된다.
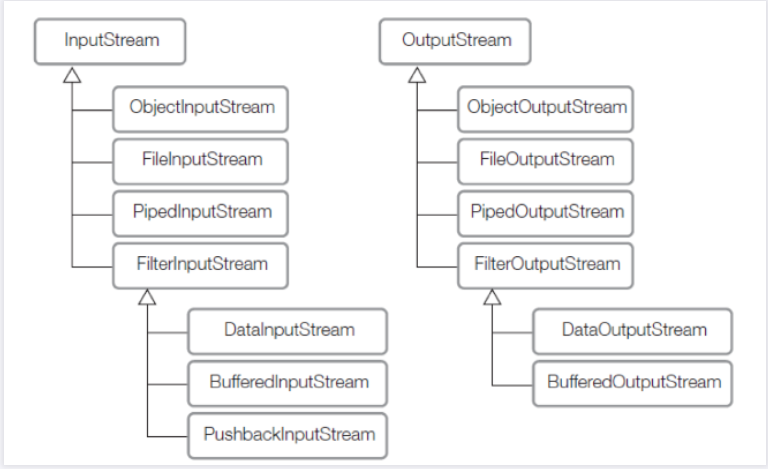
보조스트림 그 자체로 존재하는 것이 아니라 부모/자식 관계를 이루고 있는것임으로, 보조스트림 역시 부모의 입출력 방법과 같다.
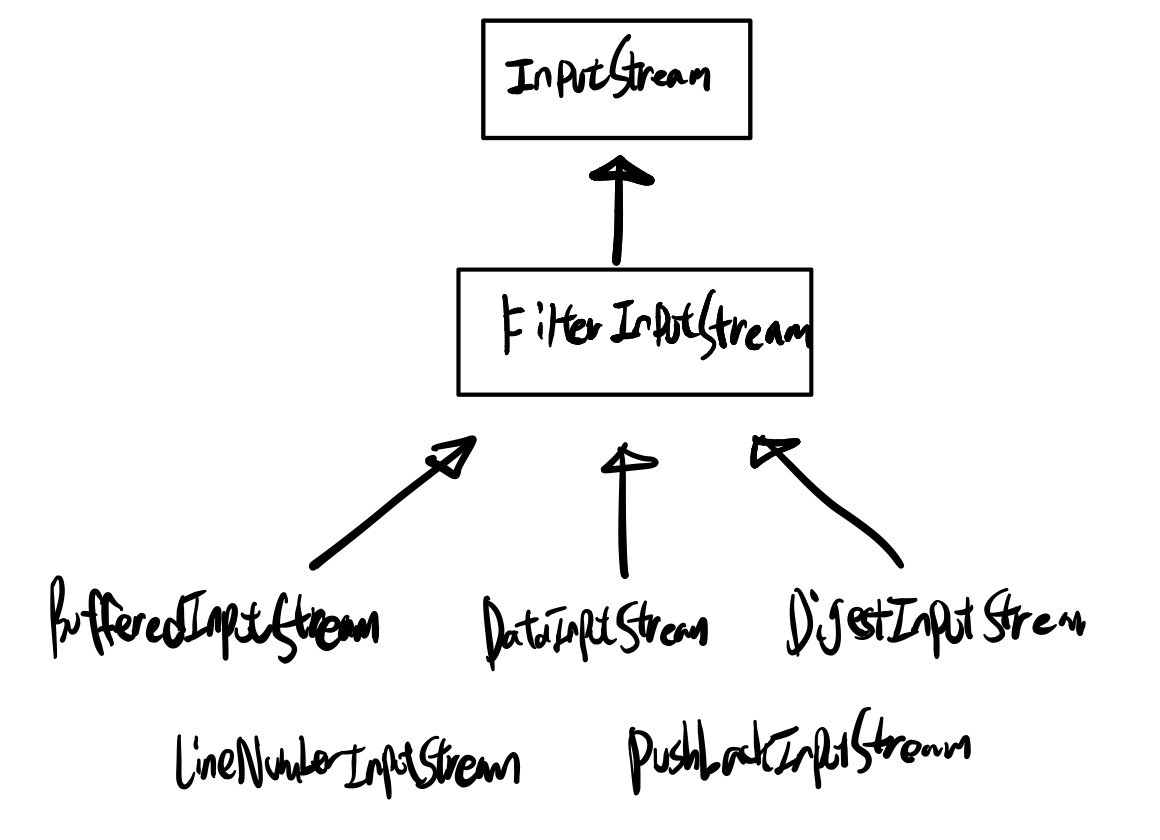
보조스트림을 이용해 조립하는 것이 가능하다. -> 데코레이터 패턴
(참조: 참조링크 )
java.io - 데코레이터 패턴
자기자신의 타입을 감싸는 패턴이라고 보면 된다.
보조 스트림의 종류
| 입력 | 출력 | 설명 |
|---|---|---|
| FilterInputStream | FilterOutputStream | 필터를 이용한 입출력 처리 |
| BufferedInputStream | BufferedOutputStream | 버퍼를 이용한 입출력 성능향상 |
| DataInputStream | DataOutputStream | int,float와 같은 Primitive Type으로 데이터를primitive Type으로 데이터를 처리하는 기능 |
| SequenceInputStream | 없음 | 두개의 스트림을 하나로 연결 |
| LineNumberInputStream | 없음 | 읽어온 데이터의 라인번호를 카운트(jdk 1.1부터 LineNumberReader로 대체) |
| ObjectInputStream | ObjectOutputStream | 데이터를 객체단위로 읽고쓰는데 사용, 주로 파일을 이용하여 객체 직렬화와 관련 |
| 없음 | PrintStream | 버퍼를 이용하여, 추가적인 print관련 기능(print,printf,println 메서드 |
| PushbackInputStream | 없음 | 버퍼를 이용해서 읽어온 데이터를 다시 되돌리는 기능(unread,push back to buffer) |
직렬화(Serialization)
객체를 컴퓨터에 저장했다가 다음에 다시 꺼낼수없을까?
네트워크를 통해 컴퓨터 간에 서로 객체를 주고받을 수 없을까?
있다 ! 직렬화가 가능하게 해준다.
직렬화란?
- 객체를 데이터 스트림으로 만드는것
- 객체에 저장된 데이터를 스트림에 쓰기 위해 연속적인(serial) 데이터로 변환
- 반대로 스트림으로부터 데이터를 읽어서 객체를 만드는 것을 역직렬화(deserialization)라고 한다.
- 직렬화 시 변환되는 것은 필드들이고, 생성자 및 메서드는 직려로하에 포함되지 않음.
- 필드 선언에 static, transient가 붙은 경우는 직렬화 되지 않는다.
ObjectInputStream, ObjectOutputStream
직렬화(스트림에 객체를 출력) -> ObjectOutputStream
역직렬화(스트림으로부터 객체를 입력) -> ObjectInputStream
둘다 보조 스트림이므로 입출력(직렬화/역직렬화) 스트림으로 지정해주어야 한다.
- ObjectOutputStream
FileOutputStream fos = new FileOutputStream("objectfile.ser");
ObjectOutputStream out = new ObjectOutputStream(fos);
out.writeObject(new UserInfo());- 파일에 객체를 저장(직렬화)하고 싶다면 위와 같이 하면된다.
- objectfile.ser이라는 파일에 UserInfo 객체를 직렬화하여 저장한다.
- 출력할 스트림(FileOutputStream)을 생성해서 이를 기반스트림으로 하는 ObjectOutputStream을 생성한다.
- writeObject(Object obj)를 사용해서 객체를 출력하면, 객체가 파일에 직렬화되어 저장된다.
- ObjectInputStream
FileInputStream fis = new FileInputStream("objectfile.ser");
ObjectInputStream in = new ObjectInputStream(fis);
UserInfo info = (UserInfo)in.readObject();- 역직렬화도 마찬가지이다. writeObject() 대신 readObject()를 사용하여 읽으면 된다.
- readObject()의 반환타입 -> Object 이므로 원래타입으로 형변환이 필요하다.
Serializable, transient
직렬화가 가능한 클래스를 만드는 방법은 직렬화하고자 하는 클래스가 java.io.Serializable 인터페이스를 구현하도록 하면 된다.
public class UserInfo implements Serializable{
}클래스를 직렬화 가능하도록 하려면 위와같이 Serializable 인터페이스를 구현하면 된다.
public interface Serializable{}Serializable 인터페이스를 확인해보면 아무런 내용이 없는 빈 인터페이스인데 직렬화를 고려하여 작성한 클래스인지를 판단하는 기준이 된다.
public class SuperUserInfo implements Serializable{
String name;
String password;
}
public class UserInfo extends SuperUserInfo{
int age;
}- Serializable을 구현한 클래스를 상속받으면 ,Serializable을 구현하지 않아도 된디
- 위의 예제에서 UserInfo는 SuperUserInfo를 상속받았으므로 UserInfo도 직렬화가 가능하다.
- 조상 클래스의 필드멤버인 name,password 도 함께 직렬화가 된다.
- 만약, SuperUserInfo 에서 Serializable를 구현하지 않고 UserInfo에서만 구현했다면?
-> name과 password는 직렬화대상에서 제외된다.
public class UserInfo implements Serializable{
String name;
String password;
int age;
Object obj = new Object(); // Object는 직렬화 될수없다
}위의 클래스를 직렬화하면 java.io.NotSerializableException 발생한다.
그 이유는 직렬화 할수없는 Object클래스를 인스턴스 변수로 참조하기 때문이다.
public class UserInfo implements Serializable{
String name;
String password;
int age;
Object obj = new String("hello"); // String은 직렬화될 수 있다.
}위으 클래스를 직렬화하면 이번에는 성공한다. 인스턴스 변수 Obj의 타입이 직렬화가 안되는 오브젝트더라도 실제로 저장된 객체는 직렬화가 가능한 String 인스턴스이기 때문에 가능하다.
-> 인스턴스 변수의 타입이 아닌 실제로 연결된 객체의 종류에 의해 결정된다는 것!
public class UserInfo implements Serializable {
String name;
transient String password; // 직렬화 대상에서 제외
int age;
transient Object obj = new Object(); // 직렬화 대상에서 제외
}직렬화하려는 객체의 클래스에 제어자:transient를 붙여서 직렬화 대상에서 제외시킬수있다.
그리고 transient가 붙은 인스턴스 변수의 값은 그 타입의 기본값으로 직렬화된다.
-> UserInfo 객체를 역직렬화하면 참조변수인 obj와 password의 값은 null이된다.
public class UserInfo implements Serializable {
String name;
String password;
int age;
public UserInfo() {
this("Unknown", "1111", 0);
}
public UserInfo(String name, String password, int age) {
this.name = name;
this.password = password;
this.age = age;
}
@Override
public String toString() {
return "UserInfo{" +
"name='" + name + '\'' +
", password='" + password + '\'' +
", age=" + age +
'}';
}
}직렬화 대상 테스트 클래스인 UserInfo를 만든다.
package me.whiteship.livestudy.week13;
import java.io.*;
import java.util.ArrayList;
public class SerialEx1 {
public static void main(String[] args) {
String fileName = "UserInfo.ser";
try(FileOutputStream fos = new FileOutputStream(fileName);
BufferedOutputStream bos = new BufferedOutputStream(fos);
ObjectOutputStream out = new ObjectOutputStream(bos);
){
UserInfo u1 = new UserInfo("Kim","12345",30);
UserInfo u2 = new UserInfo("Lee","3333",20);
ArrayList<UserInfo> list = new ArrayList<>();
list.add(u1);
list.add(u2);
out.writeObject(u1);
out.writeObject(u2);
out.writeObject(list);
System.out.println("직렬화 끝.");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}위에서 만든 UserInfo 객체를 직렬화하여 파일(UserInfo.ser)에 저장하는 예제이다.
FileOutputStream을 기반으로 한 ObjectOutputStream을 생성후, writeObject()를 이용해서 객체를 출력하면 UserInfo.ser 파일에 객체가 직렬화되어 저장된다.
package me.whiteship.livestudy.week13;
import java.io.*;
import java.util.ArrayList;
public class SerialEx2 {
String fileName = "UserInfo.ser";
try(FileInputStream fis = new FileInputStream(fileName);BufferedInputStream bis = new BufferedInputStream(fis);
ObjectInputStream in = new ObjectInputStream(bis)){
UserInfo u1 = (UserInfo) in.readObject();
UserInfo u2 = (UserInfo) in.readObject();
ArrayList<UserInfo> list = (ArrayList<UserInfo>) in.readObject();
System.out.println(u1);
System.out.println(u2);
System.out.println(list);
}catch(Exception e){
e.printStackTrace();
}
}
앞의 예제인 직렬화된 객체를 역직렬화하는 예제이다.
- readObject()의 리턴타입이 Object 이므로 원래의 타입으로 형변환해주어야한다.
- 객체를 역직렬화할때는 직렬화 할때의 순서와 일치해야 한다.
writeObject(),readObject() 메서드
부모클래스가 Serializable 인터페이스를 구현하면 자식 클래스도 직렬화가 가능하다고 했다.
그런데 부모클래스는 Serializable을 구현하지 않고 자식 클래스만 구현했다면?
자식 클래스의 필드만 직렬화가 된다.
만약 이런 상황에서 부모 클래스의 필드도 직렬화하고 싶다면 어떻게 해야할까?
- 부모클래스가 Serializable 인터페이스를 구현
- 자클래스에서 writeObject()와 readObject() 메서드를 선언해서 부모 객체의 필드를 직접출력
두 방법이 있는데 ,첫번째가 편리하겠지만 그럴수없는 상황이라면 두번째 방법을 사용해야 한다.
- writeObject(): 직렬화할때 자동호출
- readObject() : 역직렬화할때 자동호출
private void writeObject(ObjectOutputStream out) throws IOEXception {
// 부모 객체의 필드값을 출력
out.writeXXX(부모필드);
...
out.defaultWriteObject(); // 자식 객체의 필드값을 직렬화
}
private void readObject(ObjectInputStream in) throws IOEXception, ClassNotFoundException {
// 부모 객체의 필드값을 입력
부모필드 = in.readXXX();
...
out.defaultWriteObject(); // 자식 객체의 필드값을 역직렬화
}두 메서드의 선언방법이다
주의할점은 접근 제한자가 private가 아니면 자동호출이 되지않으므로 반드시 private으로 해주어야한다
아래는 예제코드이다.
public class Parent{
String field1;
}public class Child extends Parent implements Serializable{
String field2;
private void writeObject(ObjectOutputStream out) throws IOEXception {
out.writeXXX(field1);
out.defaultWriteObject();
}
private void readObject(ObjectInputStream in) throws IOEXception, ClassNotFoundException {
// 부모 객체의 필드값을 입력
field1 = in.readXXX();
out.defaultWriteObject();
}
}직렬화 가능한 클래스의 버전관리
- 직렬화된 객체를 역직렬화할때는 직렬화 했을 떄와 같은 클래스를 사용해야 한다.
- 클래스 이름이 같아도 클래스의 내용이 변경됐다면 역직렬화는 실패하고 에러가 발생한다.
위에서 만든 UserInfo 클래스에 인스턴스 변수를 하나 추가해보자
public class UserInfo implements Serializable{
double weight;
...
}몸무게 weight 변수를 추가하였다.
위의 SerialEx2 예제인 역직렬화를 다시 실행시켜보자
java.io.InvalidClassException:
local class incompatible: stream classdesc serialVersionUID = 6546280052364076434, local class serialVersionUID = -3670788073303903862
...직렬화 할때와 역질렬활 때의 클래스의 버전이 다르다는 에러가 발생한다
객체가 직렬화될때 클래스에 정의된 멤버들의 정보를 이용해서 serialVersionUID 라는 클래스의 버전을 자동생성해서 직렬화 내용에 포함된다
그래서 역직렬화 할때 클래스의 버전을 비교하고 직렬화할때의 클래스의 버전과 일치하는지 비교할수있었고 에러가 발생한것이다
public UserInfo implements Serializable{
private static final long serialVersionUID = 1L;
...
}이렇게 클래스내에 serialVersionUID를 정의해주면 클래스의 내용이 바뀌어도 클래스의 버전이 자동생성된 값으로 변경되지 않는다.
컴파일 후 다시 직렬화 -> 인스턴스변수 추가 -> 역직렬화를 진행하여도 에러없이 정상적으로 동작한다.
3. Byte와 Character 스트림
지금까지 알아본 스트림은 모두 바이트 기반의 스트림이다.
바이트기반이라 하는것은 입출력의 단위가 1byte라는 의미이다.
Byte Stream
- binary 데이터를 입출력하는 스트림
- 데이터는 1바이트 단위로 처리
- 이미지, 동영상 등을 송수신할때 주로 사용
But,
Java에서는 한문자를 의미하는 char형이 1byte가 아니라 2byte이기 때문에 바이트 기반의 스트림으로 2byte인 문자를 처리하는데에 어려움이 있다.
문자기반 스트림 - Reader,Writer
바이트기반의 입출력 스트림의 단점(1byte -> 2byte)을 보완하기 위해 문자기반의 스트림을 제공한다.
문자데이터를 입출력할때는 바이트기반 스트림 대신 문자 기반 스트림을 사용하도록 하자.
Character Stream
- text 데이터를 입출력하는 스트림
- 데이터는 2바이트 단위로 처리
- 일반적인 텍스트 및 JSON, HTML 등을 송수신할때 주로 사용

InputStream -> Reader
OutputStream -> Writer
바이트기반과 문자기반 스트림 비교
| 바이트기반스트림 | 문자기반스트림 |
|---|---|
| FileInputStream | FileReader |
| FileOutputStream | FileWriter |
| ByteArrayInputStream | CharArrayReader |
| ByteArrayOutputStream | CharArrayWriter |
| PipedInputStream | PipedReader |
| PipedOutputStream | PipedWriter |
| StringBufferInputStream(deprecated) | StringReader |
| StringBufferOutputStream(deprecated) | StringWriter |
StringBufferInputStream,StringBufferOutputStream은 StringReader,StringWriter로 대체되어 더이상 사용안함.
네이밍규칙만 보면 문자기반 스트림은 바이트기반스트림의 네이밍 중 InputStream은 Reader로 OutputStream은 writer로 바꾸면된다.
단, ByteArrayInputStream에 대응하는 문자기반 스트림은 char배열을 사용하는 CharArrayReader이다.
이와 같은 맥락으로 byte배열 대신 char 배열을 사용한다는 것과 추상메서드가 달라졌다.
이름만 다소 다를뿐 활용 방법은 동일하다고 보면 된다.
InputStream과 Reader
| InputStream | Reader |
|---|---|
| abstract int read() | int read() |
| int read(byte[] b) | int read(char[] cbuf) |
| int read(byte[] b, int off, int len) | abstract int read(char[] cbuf,int off,int len) |
OutputStream과 Writer
| OutputStream과 | Writer |
|---|---|
| abstract void write(int b) | void write(int c) |
| void write(byte[] b) | void write(char[] cbuf) |
| void write(byte[] b,int off,int len) | abstract void write(char[] cbuf,int off,int len) |
| void write(String str) | |
| void write(String str,int off,int len) |
보조스트림 역시 문자 기반 보조 스트림이 존재하여 사용목적과 방식은 바이트 기반 보조 스트림과 같다.
PrintStream:
PrintStream은 데이터를 문자기반스트림에 다양한 형태로 출력할 수 있는 print,println,printf와 같은 메서드를 오버로딩하여 제공한다.
PrintStream은 데이터를 적절한 문자로 출력하는 것이기 때문에 문자기반 스트림의 역할을 수행한다.
(JDK 1.1에서 부터 PrintStream보다 향상된 기능의 문자 기반 스트림인 PrintWriter가 추가되었으나 그 동안 매우 빈번하게 사용되던 System.out이 PrintStream이다 보니 둘다 사용할 수 밖에 없게 되었다.)
PrintStream과 PrintWrite는 거의 같은 기능을 가지고 있지만 PrintWriter가 PrintStream에 비해 다양한 언어의 문자를 처리하는데 적합하기 떄문에 가능하다면 PrintWriter를 사용하는 것이 좋다.
PrintStream은 지금까지 알게 모르게 많이 사용해왔다.
System 클래스의 Static 멤버인 out과 err, 즉 System.out, System.err이 PrintStream 이다.
print() 나 println() 을 이용해 출력하는 중에 PrintStream의 기반스트림에서 IOException이 발생하면 **checkError()**를 통해서 인지할 수 있다.
- println()이나 print()는 예외를 던지지 않고 내부에서 처리하도록 정의되어 있는데, 그 이유는 매우 자주 사용되는 것이기 때문이다.
- 만약, 예외를 던지도록 정의되었다면 print(), println()을 사용하는 모든곳에서 try/catch문을 사용해야 할 것이다.
4. 표준 스트림 (System.in, System.out, System.err)
- 표준 입출력 스트림의 종류는 java.lang 패키지의 System 클래스 내부에 static 으로 선언되어 있으며 다음과 같다.
public final class System {
public static final InputStream in;
public static final OutputStream out;
public static final PrintStream err;
}- System.in은 키보드의 입력을 받아들이기 위해서 사용되는 입력스트림이다.
- System.out은 콘솔화면에 문자열을 출력하기 위한 용도로 사용되는 출력 스트림이다.
- System.out 과 System.err
- 둘다 출력 스트림이다.
- err 은 버퍼링을 지원하지 않는다. 이것은 err이 보다 정확하고 빠르게 출력되어야 하기 때문이라고 한다. 버퍼링을 하던 도중 프로그램이 멈추면 버퍼링된 내용은 출력되지 않기 때문이다.
5. 파일 읽고 쓰기
- 텍스트 파일인 경우 문자 스트림 클래스들을 사용하면되고, 바이너리 파일인 경우 바이트 스트림을 기본적으로 사용한다.
- 입출력 효율을 위해 Buffered 계열의 보조 스트림을 함께 사용하는 것이 좋다
- 텍스트 파일인 경우
BufferedWriter bw = new BufferedWriter(new FileWriter("b.txt"));
BufferedReader br = new BufferedReader(new FileReader("a.txt"));
String s;
while ( (s = br.readLine()) != null){
bw.write(s+ "\n");- 바이너리 파일인 경우
BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("a.jpg"));
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream("b.jpg"))
byte[] buffer = new byte[14444];
while(bufferedInputStream.read(buffer)!=-1){
bufferedOutputStream.write(buffer);
}