
학습할 것 (필수)
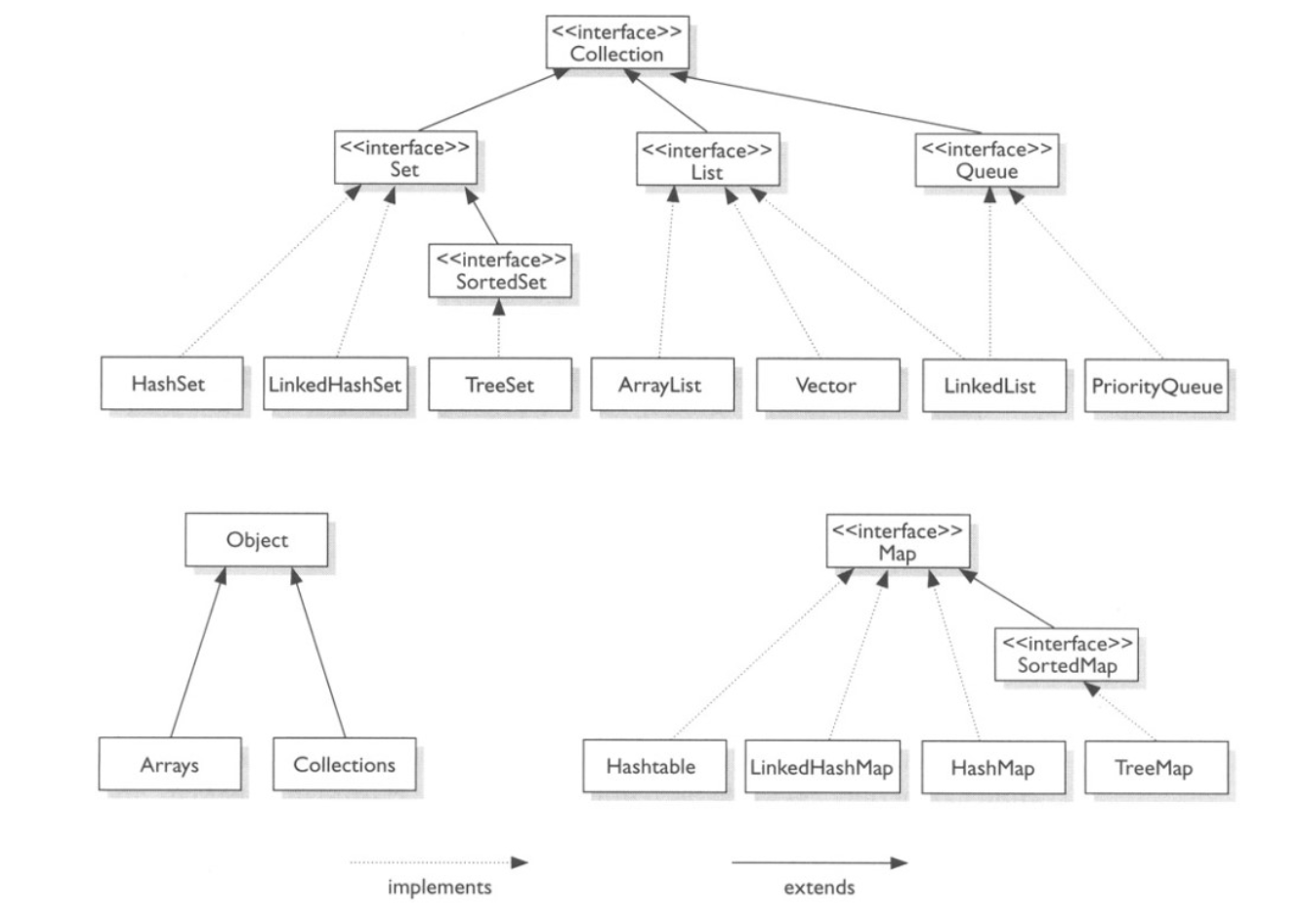
Collection이란?
Set 인터페이스
List 인터페이스
Map 인터페이스
유용한 컬렉션 메서드
Collections.sort()와 자바에서의 Comparator 사용
컬랙션 동기화
Collection이란?
- 자바는 객체를 배열로 저장할 수 있는데, 배열은 초기화 시점에 미리 정의된 크기로 초기화된다.
- 자바의 코어 라이브러리는 컬렉션 프레임워크(Collection FrameWork)를 사용하여 보다 융통성 있게 데이터를 담아서 처리하기 위한 자료구조를 제공한다.
- 컬렉션에 저장된 데이터는 캡슐화되며, 미리 정의된 메서드로만 데이터에 접근이 가능토록 한다
- 예를 들어, 개발자는 메서드를 통해서만 요소를 추가할수있다.
- 컬렉션은 내부 저장소로 배열을 사용하지만, 동적으로 배열 크기를 관리해야 하는 복잡한 부분은 개발자가 신경쓸 필요가 없다.
- 예를 들어, 애플리케이션에 여러 개의 People이란 타입의 객체를 저장하려면, 그냥 컬렉션에 저장하면된다.
컬렉션의 구성:
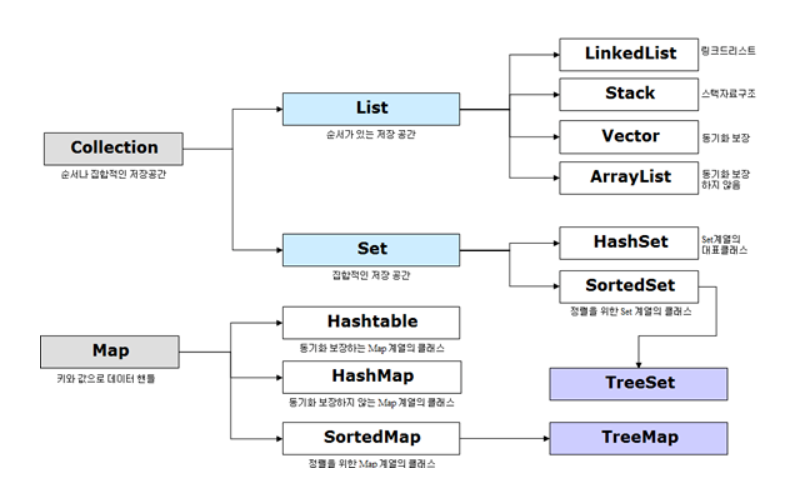
[참고]https://gangnam-americano.tistory.com/41
- 자바는 기본적으로 List와 같은 인터페이스를 구현한 하나 이상의 구현체를 제공한다.
- 예를 들어, ArrayList 혹은 LinkedList 클래스는 List 인터페이스의 구현체이다.
제네릭을 이용한 타입설정:
- 컬렉션은 제네릭을 통하여 데이터 타입을 일반화한다.
- 자바 컬렉션은 타입 정의를 매개변수로 받아야한다. 이는 컬렉션을 올바른 타입의 객체로 사용하는지 자바 컴파일러가 검증할수 있게 해주며, 다양한 종류의 객체를 조작하는 타입 혹은 메서드에게 컴파일 시점에 타입 안정성을 제공해준다.
컬렉션과 람다:
- 컬렉션 라이브러리는 람다 표현식을 지원하여 컬렉션 사용법이 어마어마하게 간단해졌다.
- forEach 루프를 사용하고, 람다를 사용하였다.
package me.whiteship.livestudy.Collections;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class App {
public static void main(String[] args) {
//List 생성
List<String> list = Arrays.asList("Lars","Simon");
//List를 이렇게도 생성할수있다.
// List는 인터페이스이므로 참조변수는 List 구현체를 가리켜야한다.
List<String> list1 = new ArrayList<>();
list1.add("LULU");
list1.add("LALA");
// 람다식을 이용하여 각 요소를 출력
list.forEach(i-> System.out.println(i));
list1.forEach(i-> System.out.println(i));
// or
list.forEach(System.out::println);
list1.forEach(System.out::println);
}
}List 인터페이스
List 인터페이스:
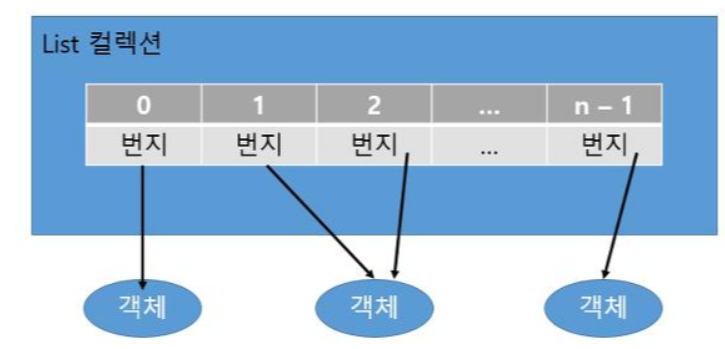
- List 인터페이스는 크기 조정이 가능한 컨테이너에 객체를 저장하는 컬렉션의 기본 인터페이스이다.
- 컬렉션 프레임워크를 상속받고 있는 List컬렉션은 객체를 일렬로 늘어놓은 구조를 가지고 있다.
- List 인터페이스는 객체를 인덱스로 관리하기 때문에 객체를 저장하면 자동 인덱스가 부여되고 인덱스로 객체를 검색,삭제할 수 있는 기능을 제공한다.
- List 컬렉션은 객체 자체를 저장하는 것이 아니라 위와 같이 객체의 번지를 참조한다.
- 동일한 객체를 저장할 수 있는데 이 경우 동일한 번지가 참조된다.
- null도 저장이 가능한데 이 경우 해당 인덱스는 객체를 참조하지 않는다.
구현체:
ArrayList
- ArrayList는 요소들을 동적으로 추가 및 삭제가 가능한 List 인터페이스의 구현체이다.
- 만약 ArrayList에 초기크기보다 더 많은 요소가 추가되는 경우에는 크기가 동적으로 증가된다.
- ArrayList는 배열을 기반으로 구현되어 있기 때문에 인덱스로 객체를 관리함으로써, 인덱스를 사용하여 내부에 담긴 요소들을 get()과 set() 메서드를 사용하여 빠르고 효율적으로 접근할수있다.
- 일반적으로 ArrayList는 List 인터페이스의 구체 클래스로 많이 사용된다.
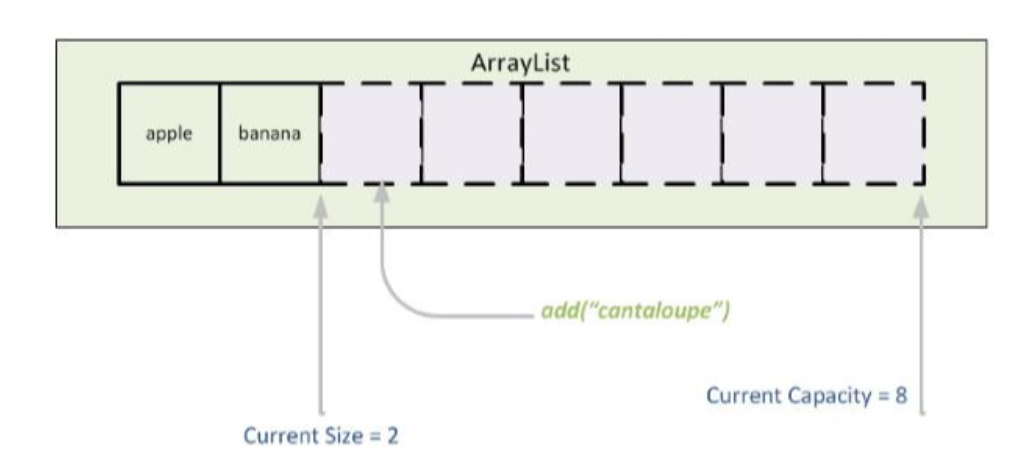
ArrayList 선언
package me.whiteship.livestudy.Collections;
import me.whiteship.livestudy.review6.Student;
import java.util.ArrayList;
import java.util.Arrays;
public class ArrayListExample {
public static void main(String[] args) {
ArrayList list= new ArrayList(); // 타입 미설정 object로 선언된다.
ArrayList<Student> list1 = new ArrayList<Student>(); // 타입설정 Student객체만
ArrayList<Integer> list2 = new ArrayList<Integer>(); // 타입설정 int타입만 사용가능
ArrayList<Integer> list3 = new ArrayList<>(); // new에서 타입파라미터 생략가능.
ArrayList<Integer> list4 = new ArrayList<Integer>(10); // 초기용량 지정
ArrayList<Integer> list5 = new ArrayList<Integer>(Arrays.asList(1,2,3)); // 생성값 추가
}
}- ArrayList 선언시 ArrayList list = new ArrayList()로 선언후 내부에 임의의 값을 넣고 사용할 수 있지만 이렇게 사용할 경우 값을 뽑아내기 위해서는 캐스팅(casting) 연산이 필요하고 잘못된 타입으로 캐스팅을 하는 경우에는 에러가 발생하기에 위 방식은 추천하지 않는다.
- ArrayList를 사용할시에는 ArrayList에 타입(제네릭스)을 명시해주는 것이 좋다.
- 제네릭스는 선언할 수 있는 타입이 객체 타입이다.
- 따라서 primitive 자료형은 사용할 수 없기 때문에 int를 객체화시킨 wrapper 클래스인 Integer를 사용해야한다.
ArrayList 값 추가
package me.whiteship.livestudy.Collections;
import java.util.ArrayList;
import java.util.Arrays;
public class ArrayListExample {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
list.add(3); // 값 추가
list.add(null); // null값도 add 가능
list.add(1,10); // index 1 위치에 10 insert
}
}- ArrayList에 값을 추가하려면 ArrayList의 add(index,value) 메서드를 사용하면 된다
- 인덱스를 생략하면 ArrayList 맨 뒤에 데이터가 추가되며 index 중간에 값을 추가하면 해당 인덱스부터 마지막 인덱스까지 모두 1씩 뒤로 밀려난다.
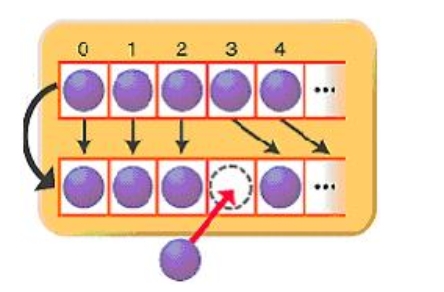
- 이 경우에 데이터가 늘어나면 늘어날 수록 성능에 악영향이 미치기에 중간에 데이터를 insert 해야할 경우가 많다면 ArrayList 보다 LinkedList를 활용하는 것이 더 낫다.
ArrayList 값 삭제
ArrayList<Integer> arrayList = new ArrayList<>(Arrays.asList(1,2,3));
arrayList.remove(1); // index 1 제거
arrayList.clear(); // 모든 값 제거- ArrayList에 값을 제거하려면 ArrayList의 remove(index) 메서드를 사용하면 된다.
- remove 메서드를 사용하면 특정 인덱스의 객체를 제거하고 바로 뒤 인덱스부터 마지막 인덱스까지 모두 앞으로 1씩 당겨진다.
- 모든 값을 제거하려면 clear()를 사용하면 된다.
ArrayList 크기 구하기
ArrayList<Integer> arrayList = new ArrayList<>(Arrays.asList(1,2,3));
System.out.println(arrayList.size()); // 3 출력ArrayList 값 출력
package me.whiteship.livestudy.Collections;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
public class ArrayListExample {
public static void main(String[] args) {
ArrayList<Integer> arrayList = new ArrayList<>(Arrays.asList(1,2,3));
System.out.println(arrayList.get(0)); // 0번째 인덱스 출력
for (Integer integer : arrayList) { // for문을 통한 전체 출력
System.out.println(integer);
}
Iterator iterator = arrayList.iterator(); // Iterator 선언
while(iterator.hasNext()){ // 다음값이 있는지 체크
System.out.println(iterator.next()); // 값 출력
}
}
}output
1
1
2
3
1
2
3- ArrayList의 get함수를 통해 특정 index의 값을 가져올수있다.
- 전체출력은 Iterator 혹은 for문을 이용하여 출력할수있다.
ArrayList 값 검색
package me.whiteship.livestudy.Collections;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
public class ArrayListExample {
public static void main(String[] args) {
ArrayList<Integer> arrayList = new ArrayList<>(Arrays.asList(1,2,3,1));
System.out.println(arrayList.contains(1)); // list에 1이 있는지 검색: true
System.out.println(arrayList.indexOf(1)); // 1이 있는 index 반환 없으면 -1
}
}output
true
0- ArrayList에서 찾고자 하는 값을 검색하려면 ArrayList의 contains(value) 메서드를 사용하면 된다. 만약 값이 있다면 true를 아니면 false를 리턴한다.
- 값이 존재하는 index를 찾으려면 indexOf(value) 메서드를 사용하면 된다. 존재하면 인덱스를 존재하지 않으면 -1을 리턴한다.
LinkedList
- LinkedList는 이중연결리스트(double linked list)로 구현되어 있는데, 이는 add()와 remove() 메서드의 경우 ArrayList보다 더 나은 성능을 발휘한다.
- 반면에 LinkedList는 멤버에 대한 직접 접근을 제공하지 않기 때문에 순차탐색이 필요로 하여 탐색 속도가 떨어지고, get()과 set() 메서드는 ArrayList보다 성능이 떨어진다.
- 그러므로 탐색 또는 정렬을 자주하는 경우엔 ArrayList를 데이터의 추가 혹은 삭제가 많은 경우 연결 리스트를 사용하는 것이 좋다.
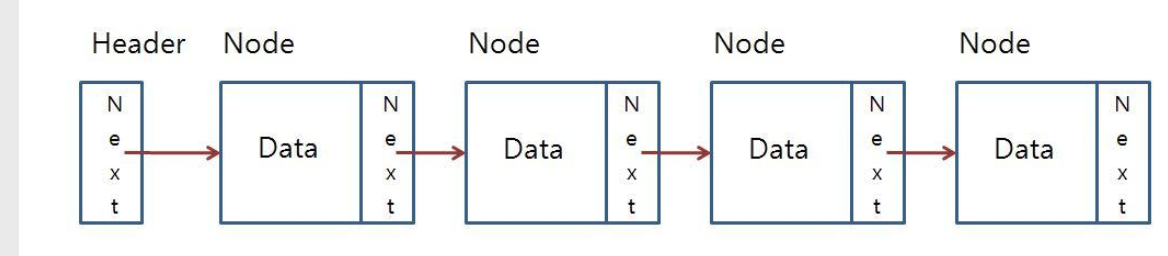
LinkedList 선언
package me.whiteship.livestudy.Collections;
import java.util.Arrays;
import java.util.LinkedList;
public class LinkedListExample {
public static void main(String[] args) {
LinkedList list = new LinkedList(); // 타입 미설정 Object로 선언된다.
LinkedList<Integer> list1= new LinkedList<Integer>(); // 타입설정 int타입만 사용가능하다
LinkedList<Integer> list2 = new LinkedList<>(); // new에서 타입 파라미터 생략가능
LinkedList<Integer> list3 = new LinkedList<Integer>(Arrays.asList(1,2,3)); // 생성시 값추가
}
}- LinkedList는 ArrayList 선언 방식과 동일하다. 다만 LinkedList에서는 초기의 크기를 미리 생성할수는 없다.
- LinkedList 선언시 LinkedList list = new LinkedList()로 선언하고 내부에 임의의 값을 넣어 사용할수도 있지만 이렇게 사용할 경우 내부의 값을 사용할 때 캐스팅을 해야하고 잘못된 타입으로 캐스팅을 할 경우에는 에러가 발생하기에 위와 같은 방식은 추천하지 않는다.
- LinkedList를 생성할대 LinkedList에 사용 타입을 명시해주는 것이 좋다.
LinkedList 값 추가
package me.whiteship.livestudy.Collections;
import java.util.Arrays;
import java.util.LinkedList;
public class LinkedListExample {
public static void main(String[] args) {
LinkedList<Integer> list= new LinkedList<Integer>();
list.addFirst(1); // 가장 앞에 데이터를 추가
list.addLast(2); // 가장 뒤에 데이터 추가
list.add(3); // 데이터 추가
list.add(1,10); // 1번쨰 index에 데이터 10추가
}
}
- LinkedList에 값을 추가하는 방법은 여러 개가 있는데 대중적으로 add(index,value) 메서드를 사용한다.
- index를 생략하면 가장 마지막에 데이터가 추가된다.
- addFirst(value) 메서드를 사용하게 되면 가장 앞에 있는 Header의 값이 변경되고,
addLast(value) 메서드르 ㄹ사용하면 LinkedList 맨 뒤에 데이터가 추가된다.
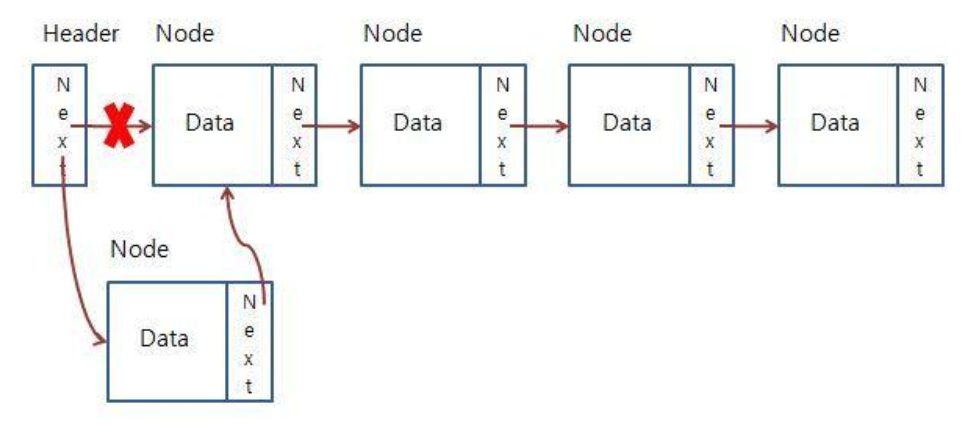
- List에 값이 추가되는 방식은 위의 그림과 같다. 먼저 인자로 받은 값을 가지고 Node를 생성하고, 이전 노드는 추가되는 노드를 가리키게 하고 추가되는 노드는 이전 노드가 가리켰던 그 다음 노드를 가리키도록 지정한다.
LinkedList 값 삭제
package me.whiteship.livestudy.Collections;
import java.util.Arrays;
import java.util.LinkedList;
public class LinkedListExample {
public static void main(String[] args) {
LinkedList<Integer> list= new LinkedList<Integer>(Arrays.asList(1,2,3,4,5));
list.removeFirst(); // 가장 앞의 데이터 제거
list.removeLast(); // 가장 뒤의 데이터 제거
list.remove(); // index 생략시 0번째 index 제거
list.remove(1); // 1번째 index 제거
list.clear(); // 모든 값 제거
}
}- LinkedList에 값을 제거하는 방법도 값을 추가하는 것과 유사하다.
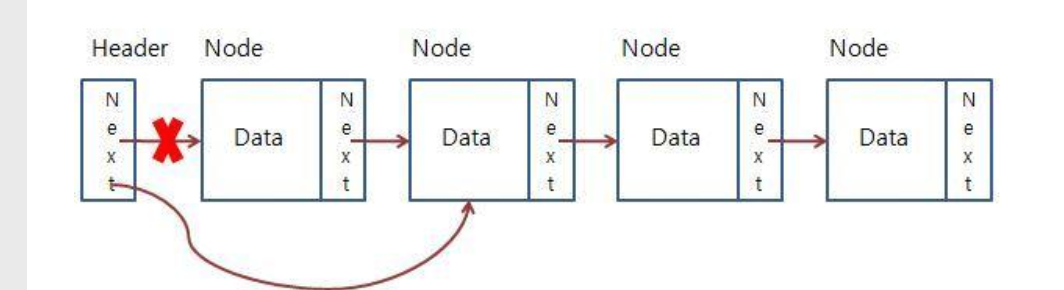
LinkedList 크기 구하기
LinkedList<Integer> list= new LinkedList<Integer>(Arrays.asList(1,2,3,4,5));
System.out.println(list.size());LinkedList 값 출력
LinkedList<Integer> list= new LinkedList<Integer>(Arrays.asList(1,2,3,4,5));
System.out.println(list.get(0)); // 0번째 index 출력
System.out.println();
for (Integer integer : list) { // for문을 이용한 전체 출력
System.out.println(list);
}
Iterator iterator = list.iterator();
while(iterator.hasNext()){ // iterator를 이용한 전체 출력
System.out.println(iterator.next());
}LinkedList 값 검색
LinkedList<Integer> list= new LinkedList<Integer>(Arrays.asList(1,2,3,4,5));
System.out.println(list.contains(1)); // true 출력
System.out.println(list.indexOf(3)); // 2 출력예제코드:
package me.whiteship.livestudy.Collections;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class App {
public static void main(String[] args) {
//ArrayList에 대한 타입 추론
List<Integer> list = Arrays.asList(3,2,1,4,5,6,6);
//또는 다음과 같이 선언가능
// List<Integer> list = new ArrayList<>();
// list.add(element);
for (Integer integer : list) {
System.out.println(integer);
}
}
}output
3
2
1
4
5
6
6정렬:
- 람다를 이용한 Comparator.compare()을 정의하여 자연스러운 순서로 리스트를 정렬할수 있다.
- 일반적으로 자바8에서는 compare() 메서드를 정의할대 람다 표현식 혹은 메서드 참조를 사용한다.
예제코드
package me.whiteship.livestudy.Collections;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class App {
public static void main(String[] args) {
// natural order로 sorting
List<String> list = createList();
list.sort(null);
list.forEach((i)-> System.out.println(i));
System.out.println();
// 람다를 사용하여 sorting
List<String> list1 = createList();
list1.sort((s1,s2)->s1.compareToIgnoreCase(s2)); // 대소문자 구분없이 정렬
list1.forEach((i)-> System.out.println(i));
System.out.println();
// 메서드참조를 사용하여 sorting
List<String> list2 = createList();
list2.sort(String::compareToIgnoreCase);
list2.forEach(System.out::println);
}
private static List<String> createList(){
return Arrays.asList("ios","android","apple","samsung");
}
}
output
android
apple
ios
samsung
android
apple
ios
samsung
android
apple
ios
samsung조건부삭제:
- removelf() 메서드를 사용하면 조건에 따라 list의 항목을 제거할 수 있다.
package me.whiteship.livestudy.Collections;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class App {
public static void main(String[] args) {
List<String> list = createList();
list.removeIf(s-> s.toLowerCase().contains("x"));
list.forEach(System.out::println);
}
private static List<String> createList(){
List<String> newList = new ArrayList<>();
newList.addAll(Arrays.asList("iPhone","Ubuntu","Andriod","MAC OS X"));
return newList;
}
}output
iPhone
Ubuntu
AndriodMap 인터페이스
Map과 HashMap:
- Map 컬랙션은 키와 값으로 구성된 객체를 저장하는 구조를 가지고 있는 자료구조이다.
- 키는 중복으로 저장할 수 없고 값은 중복으로 저장할 수 있으며 중복된 key값이 들어온다면 기존의 값은 없어지고 새로운 값으로 대치된다.
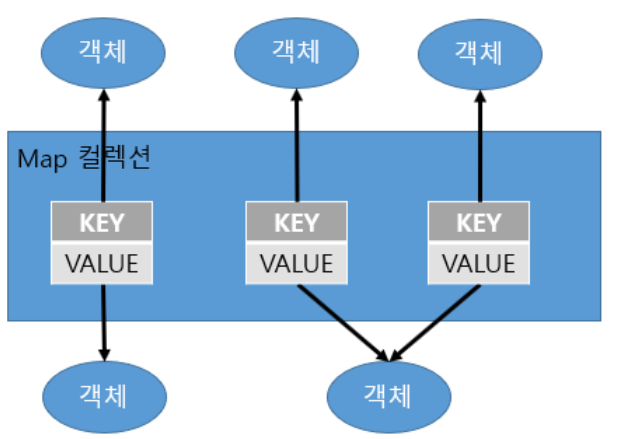
- Map 인터페이스는 키에 값을 매핑하는 객체를 정의한다.
- Map은 중복된 키를 가질 수 없고, 각각의 키는 최대 하나의 값에만 매핑할 수 있다.
- 값의 데이터 중복은 가능하다.
- Map은 리스트나 배열처럼 순차적으로 해당 요소 값을 구하지 않고 key를 통해 value를 얻는다.
- HashMap 클래스는 Map 인터페이스를 구현한 구현체 클래스이다.
HashMap:
- HashMap은 Map인터페이스를 구현한 대표적인 Map 컬랙션이다.
- Map 인터페이스를 상속하기 있기에 Map의 성질을 그대로 가지고있다.
- Map은 키와 값으로 구성된 Entry객체를 저장하는 구조를 가지고 있는 자료구조이다.
- 여기서 키와 값은 모두 객체이다.
- 값은 중복저장될수있지만 키는 중복저장될수없다.
- 만약 기존에 저장된 키와 동일한 키로 저장하면 기존의 값은 없어지고 새로운 값으로 대치된다.
- HashMap은 이름그대로 해싱(Hashing)을 사용하기 때문에 많은 양의 데이터를 검색하는데 있어서 뛰어난 성능을 보인다.
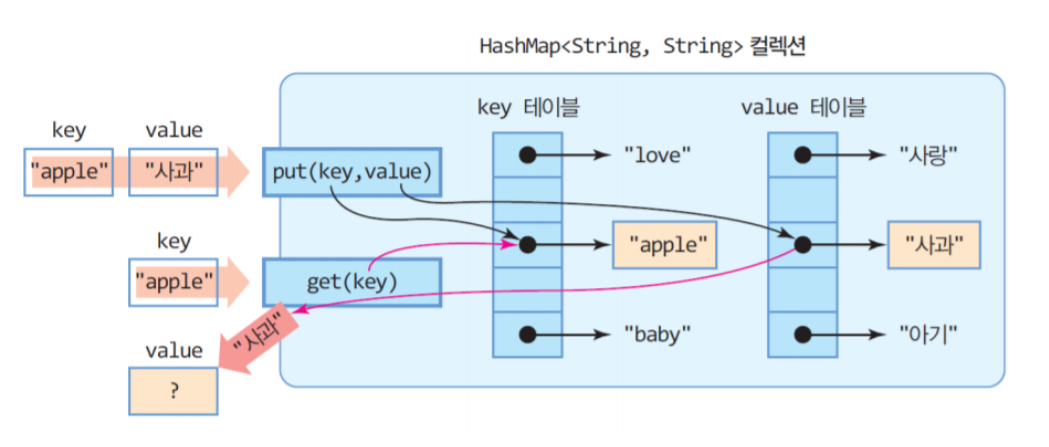
- 위와 같이 HashMap은 내부에 키와 값을 저장하는 자료구조를 가지고 있다. HashMap은 해시 함수를 통해 키와 값이 저장되는 위치를 결정하므로, 사용자는 그 위치를 알수없고, 삽입되는 순서와 들어있는 위치 또한 관계가 없다.
HashMap 선언
HashMap<String,String> hashMap = new HashMap<String,String>(); // HashMap 생성
HashMap<String,String> hashMap1 = new HashMap<>(); // new에서 타입 파라미터 생략가능
HashMap<String,String> hashMap2 = new HashMap<>(hashMap); // map의 모든 값을 가진 HashMap 생성
HashMap<String,String> hashMap3 = new HashMap<>(10); // 초기 용량 지정
HashMap<String,String> hashMap4 = new HashMap<>(10,0.7f); // 초기 용량 지정, load factor 지정
HashMap<String,String> hashMap5 = new HashMap<String,String>(){{put("a","b");}
}; // 초기값 지정- HashMap을 생성하려면 키 타입과 값 타입을 파라미터로 주고 기본생성자를 호출하면 된다.
- HashMap은 저장공간보다 값이 추가로 들어오면 List처럼 저장종간을 추가로 늘리는데 List처럼 저장공간을 한 칸씩 늘리지 않고 약 두배로 늘린다. 여기서 과부하가 많이 발생한다
- 따라서 초기에 저장할 데이터 개수를 알고 있다면 Map의 초기 용량을 지정해주는 것이 좋다.
★★★해당내용참고링크
HashMap 값 추가
HashMap<Integer,String> hashMap = new HashMap<>(); // HashMap 생성
hashMap.put(1,"사과");
hashMap.put(2,"사과");
hashMap.put(3,"바나나");- HashMap에 값을 추가하려면 put(key,value) 메서드를 사용하면 된다.
- 선언 시 HashMap에 설정해준 타입과 같은 타입의 Key와 Value 값을 넣어야하며 만약 입력되는 키 값이 HashMap 내부에 존재한다면 기존의 값은 새로 입력되는 값으로 대치된다.
HashMap 값 삭제
HashMap<Integer,String> hashMap = new HashMap<Integer,String>(){{
put(1,"사과");
put(2,"사과");
put(3,"바나나");
}};
hashMap.remove(1); // key값 1 제거
hashMap.clear(); // 모든 값 제거HashMap 값 출력
package me.whiteship.livestudy.Collections;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class HashMapExample {
public static void main(String[] args) {
HashMap<Integer,String> hashMap = new HashMap<Integer,String>(){{
put(1,"사과");
put(2,"사과");
put(3,"바나나");
}};
System.out.println(hashMap); // 전체출력
System.out.println(hashMap.get(1)); // 키값1 출력
System.out.println();
// entrySet() 활용
// for문 사용
for (Map.Entry<Integer, String> integerStringEntry : hashMap.entrySet()) {
System.out.println(integerStringEntry.getKey() + " " + integerStringEntry.getValue());
}
System.out.println();
// iterator 사용
Iterator<Map.Entry<Integer,String>> entryIterator = hashMap.entrySet().iterator();
while(entryIterator.hasNext()){
Map.Entry<Integer,String> map = entryIterator.next();
System.out.println(map.getKey() + " " + map.getValue());
}
System.out.println();
// KeySet() 활용
// for문 사용
for (Integer integer : hashMap.keySet()) {
System.out.println(integer + " " + hashMap.get(integer));
}
System.out.println();
// iterator 사용
Iterator<Integer> iterator = hashMap.keySet().iterator();
while(iterator.hasNext()){
int key = iterator.next();
System.out.println(key + " " + hashMap.get(key));
}
}
}
- HashMap을 출력하는 방법에는 다양한 방법이있다.
- 그냥 print하게 되면 {}로 묶어 Map의 전체 key,value를 출력한다
- 특정 key값의 value를 가져오고 싶다면 get(key)를 사용하면 되고 전체를 출력하려면
entrySet() 이나 keySet() 메서드를 활용하여 Map 객체를 반환받은 후 출력하면 된다 - entrySet은 키와 값 모두가 필요한 경우 사용하며,
- keySet 은 key 값만 필요할 경우 사용하는데 key값을 이용하여 get()함수를 호출할수있기 때문에 value도 출력할수있기 때문에 두개다 모든 원소에 대해 출력이 가능하다.
- 허나, key값을 이용하여 get() 메서드를 호출하는 것은 value를 찾는 과정에서 시간이 많이 소모되므로 많은 양의 데이터를 가져와야 한다면 entrySet()이 더 좋다(약 20%~200% 성능 저하가 있다.)
TreeMap:
- TreeMap은 이진트리를 기반으로 한 Map 컬랙션이다. 같은 Tree 구조로 이루어진 TreeSet과의 차이점은 TreeSet은 그냥 값만 저장한다면 TreeMap은 키와 값이 저장된 Map.entry를 저장한다는 점이다.
- TreeMap에 객체를 저장하면 자동으로 정렬되는데, 키는 저장과 동시에 자동 오름차순으로 정렬되고 숫자 타입일 겨웅에는 값으로, 문자열 타입일 경우에는 유니코드로 정렬한다.
- 정렬 순서는 기본적으로 부모 키값과 비교해서 키 값이 낮은 것은 왼쪽 자식 노드에 키 값이 높은 것은 오른쪽 자식 노드에 Map.Entry 객체를 저장한다.
- TreeMap은 일반적으로 Map의 성능으로써 HashMap보다 떨어진다. TreeMap은 데이터를 저장할 때 즉시 정렬하기에 추가나 삭제가 HashMap보다 오래 걸린다.
- 하지만 정렬된 상태로 Map을 유지해야 하거나 정렬된 데이터를 조회해야 하는 범위 검색이 필요한 경우 TreeMap을 사용하는 것이 효율성 면에 좋다.
레드블랙트리
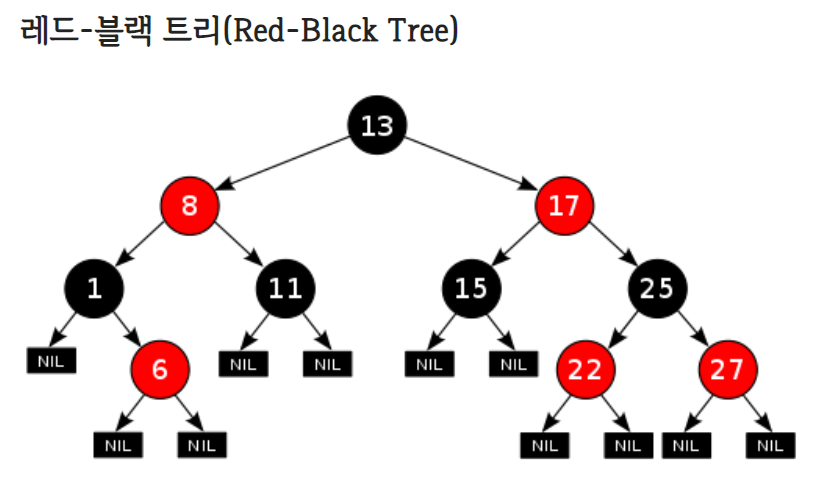
- TreeMap은 이진탐색트리의 문제점을 보완한 레드 블랙 트리로 이루어져 있다.
- 일반적인 이진탐색트리는 트리의 높이 만큼 시간이 필요하다.
- 값이 전체 트리에 잘 분산되어 있다면 효율성에 있어 크게 문제가 없으나 데이터가 들어올 대 한쪽 방면으로 편향되게 들어올 경우 한쪽 으로 크게 치우쳐진 트리가 되어 굉장히 비효율적인 퍼포먼스를 낸다.
- 이 문제를 보완하기 위해 레드 블랙 트리가 등장하였다.
TreeMap 선언
TreeMap<Integer,String> treeMap1 = new TreeMap<Integer,String> (); // TreeMap 생성
TreeMap<Integer,String> treeMap2 = new TreeMap<> (); // new에서 파라미터 생략가능
TreeMap<Integer,String> treeMap3 = new TreeMap<> (treeMap1); // treeMap1의 모든값을 가진 TreeMap 생성
TreeMap<Integer,String> treeMap4 = new TreeMap<Integer,String>(){{ // 초기값 설정
put(1,"사과");
put(2,"사과");
put(3,"바나나");
}};- 생성하는 명령어는 HashMap과 크게 다르지 않으나 선언 시 크기를 지정해줄수는 없다.
TreeMap 값 추가
TreeMap<Integer,String> treeMap1 = new TreeMap<Integer,String> (); // TreeMap 생성
treeMap1.put(1,"사과");
treeMap1.put(2,"사과");
treeMap1.put(3,"바나나");- TreeMap은 HashMap과 구조만 다를뿐이지 기본적으로 Map인터페이스를 같이 상속받고 있으므로 기본적인 메서드의 사용법 자체는 HashMap과 동일하다.
TreeMap 값 삭제
TreeMap<Integer,String> treeMap = new TreeMap<Integer,String>(){{
put(1,"사과");
put(2,"사과");
put(3,"바나나");
}};
treeMap.remove(1); // key값 1제거
treeMap.clear(); // 모든 값 제거
TreeMap 단일값 출력
TreeMap<Integer,String> treeMap = new TreeMap<Integer,String>(){{
put(1,"사과");
put(2,"사과");
put(3,"바나나");
}};
System.out.println(treeMap); // 전체출력
System.out.println(treeMap.get(1)); // key값 1의 value 출력
System.out.println(treeMap.firstEntry()); // 최소 entry 출력 : 1,사과
System.out.println(treeMap.firstKey()); // 최소 key 출력 : 1
System.out.println(treeMap.lastEntry()); // 최대 entry 출력 : 3,바나나
System.out.println(treeMap.lastKey()); // 최대 key 출력 : 3
output
{1=사과, 2=사과, 3=바나나}
사과
1=사과
1
3=바나나
3- TreeMap 은 해쉬맵과 달리 트리구조로 이루어져있고 항상 정렬이 되어있어 최솟값,최댓값을 바로 가져오는 다양한 메서드를 지원한다.
- firstEntry는 최소 entry값,firstkey는 최소 Key값, lastEntry는 최대 entry값, lastKey는 최대 Key값을 리턴한다.
TreeMap 모든값 출력
TreeMap<Integer,String> treeMap = new TreeMap<Integer,String>(){{
put(1,"사과");
put(2,"사과");
put(3,"바나나");
}};
//entrySet() 활용
//for문 활용
for (Map.Entry<Integer, String> integerStringEntry : treeMap.entrySet()) {
System.out.println(integerStringEntry.getKey()+ " " + integerStringEntry.getValue());
}
System.out.println();
//Iterator 활용
Iterator<Map.Entry<Integer,String>> iterator = treeMap.entrySet().iterator();
while(iterator.hasNext()){
Map.Entry<Integer,String> entry = iterator.next();
System.out.println(entry.getKey()+ " "+ entry.getValue());
}
System.out.println();
//keySet() 활용
//for문 활용
for (Integer integer : treeMap.keySet()) {
System.out.println(integer + " " + treeMap.get(integer));
}
System.out.println();
//iterator 활용
Iterator<Integer> iterator1 = treeMap.keySet().iterator();
while(iterator1.hasNext()){
int key = iterator1.next();
System.out.println(key + " " + treeMap.get(key));
}`output
1 사과
2 사과
3 바나나
1 사과
2 사과
3 바나나
1 사과
2 사과
3 바나나
1 사과
2 사과
3 바나나- TreeMap의 전체요소를 출력하려면 HashMap과 마찬가지로 entrySet()이나 keySet() 메서드를 활용하여 map의 객체를 반환받은 후 출력하면 된다.
- key값을 이용해서 value를 찾는 과정에서 시간이 많이 소모되므로 많은양의 데이터를 가져와야 한다면 entrySet이 좋다.
예제코드
package me.whiteship.livestudy.Collections;
import java.util.HashMap;
import java.util.Map;
public class App {
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
fillData(map);
map.put("Python","joa");
map.forEach((k,v)-> System.out.format("%s %s%n", k , v));
System.out.println();
map.remove("IOS");
map.forEach((k,v)-> System.out.format("%s %s%n", k , v));
}
private static void fillData(Map<String,String> map){
map.put("Android","SamSung");
map.put("IOS","Apple");
map.put("JAVA","Oracle");
}
}output
JAVA Oracle
IOS Apple
Android SamSung
Python joa
JAVA Oracle
Android SamSung
Python joaMap의 키를 배열 혹은 리스트로 전환
package me.whiteship.livestudy.Collections;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class App {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
fillData(map);
String[] strings = keyAsArray(map);
for (String string : strings) {
System.out.print(string+" ");
}
System.out.println();
List<String> list = keyAsList(map);
list.forEach(s -> System.out.print(s+ " "));
}
private static void fillData(Map<String,String> map){
map.put("Android","SamSung");
map.put("IOS","Apple");
map.put("JAVA","Oracle");
map.put("Python","Rossum");
}
private static String[] keyAsArray(Map<String,String> map){
return map.keySet().toArray(new String[map.keySet().size()]);
}
private static List<String> keyAsList(Map<String,String> map){
List<String> newList = new ArrayList<String>(map.keySet());
return newList;
}
}output
JAVA IOS Android Python
JAVA IOS Android Python Map의 모든 요소를 처리하기
- 매개변수로 람다를 이용하는 forEach() 메서드를 사용할 수 있다.
map의 현재 값 또는 기본값 가져오기
- 자바8에 소개된 getOrDefault() 메서드를 이용하면, map에 키에 해당하는 값이 없으면 기본값을 반환한다.
package me.whiteship.livestudy.Collections;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class App {
public static void main(String[] args) {
Map<String,String> map = createMap();
map.put("NAVER",map.getOrDefault("qweqwe","helllo"));
map.put("NAVER2",map.getOrDefault("Android","helllo"));
map.forEach((k,v)-> System.out.println(k+ " "+ v + " "));
}
private static Map<String,String> createMap(){
Map<String,String> map = new HashMap<>();
map.put("Android","SamSung");
map.put("IOS","Apple");
map.put("JAVA","Oracle");
map.put("Python","Rossum");
return map;
}
}
output
JAVA Oracle
NAVER2 SamSung
NAVER helllo
IOS Apple
Android SamSung
Python Rossum - map에 존재하지 않을 때만 새로운 항목을 추가해야 하는 경우라면, computeIfAbsent() 메서드를 사용하면 자동으로 값을 계산하여 map에 추가할수있다.
package me.whiteship.livestudy.Collections;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class App {
public static void main(String[] args) {
Map<String,String> map = createMap();
String value = map.computeIfAbsent("JAVA", it->"good");
System.out.println(value);
value = map.computeIfAbsent("Java", it->"good");
System.out.println(value);
System.out.println();
map.forEach((k,v)-> System.out.println(k+ " "+ v + " "));
}
private static Map<String,String> createMap(){
Map<String,String> map = new HashMap<>();
map.put("Android","SamSung");
map.put("IOS","Apple");
map.put("JAVA","Oracle");
map.put("Python","Rossum");
return map;
}
}output
Oracle
good
JAVA Oracle
Java good
IOS Apple
Android SamSung
Python Rossum Set 인터페이스:
Set이란?
- 앞서 살펴본 List 컬렉션은 선형구조를 가지고 있으므로 추가한 순서대로 저장이 되어 순서를 유지하였지만 set컬랙션의 경우에는 저장 순서가 유지되지 않는다.
- 그러므로 set컬렉션은 순서 자체가 없으므로 인덱스로 객체를 검색해서 가져오는 get(index)가 존재하지 않는다.
- 대신 전체 객체를 대상으로 한번식 반복해서 가져오는 반복자(iterator)를 제공한다.
- 반복자(iterator)는 iterator()메서드를 호출하면 얻을수있다.
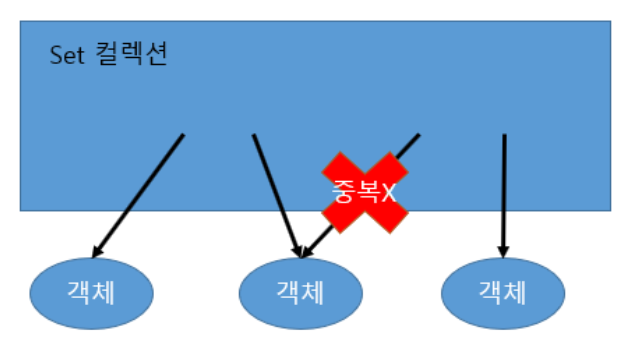
-
또한 set은 객체를 중복해서 저장할 수 없고 하나의 중복 저장이 안되기에 null값도 하나만 저장할수있다.
-
대표적으로 HashSet과 TreeSet 클래스가 있다.
-
HashSet 클래스를 보면 ArrayList와 마찬가지로 동기화를 제공하지 않는다. 또한 추가되는 요소들의 순서도 보장하지 않는다.
-
Set에 추가되는 요소의 순서를 부여하기 위해서는 JDK1.4버전부터 도입된 LinkedHashSet이 있다. 이 클래스의 생성자를 살펴보면 HashSet 클래스와는 조금 다른것을 알 수 있다.
HashSet
- HashSet은 set 인터페이스의 구현 클래스이다.
- Set은 객체를 중복해서 저장할 수 없고 하나의 null 값만 저장할 수 있다.
- 또한 저장 순서가 유지되지 않는다.
- 만약 요소의 저장 순서를 유지해야 한다면 JDK1.4 부터 제공하는 LinkedHashSet 클래스를 사용하면 된다.
- HashSET의 경우 정렬을 해주지 않고 TreeSet의 경우 자동정렬을 해준다는 차이점이 있다.
- Set의 가장 큰 장점은 중복을 자동으로 제거해준다는 것에 있다.
- 만약 한 편의점에서 오늘 방문한 손님의 총숫자를 계산하고 싶을 경우도 있을 것이다.
- 이럴 경우 오늘 하루 동안 편의점을 여러번 방문한 손님은 한 번으로 체크해주어야 정확한 손님의 숫자가 나올것이다.
- 이럴대 SET을 유용하게 사용할수있다.
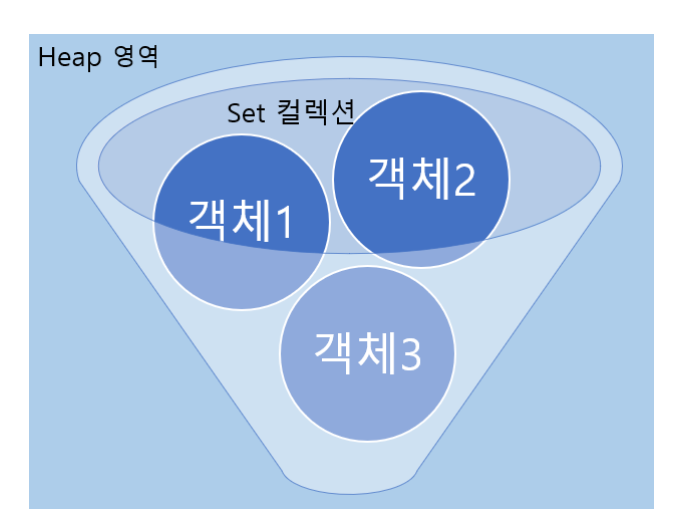
- Set은 위 그림과 같이 주머니 형태로 되어 있다.
- 비선형 구조이기에 순서가 없으며 그렇기에 인덱스도 존재하지 않는다.
- 그렇기에 값을 추가하거나 삭제할 때에는 내가 추가 혹은 삭제하고자 하는 값이 Set에 있는지 검색 한뒤 추가나 삭제를 해야 하므로 속도가 List구조에 비해 느리다.
중복을 걸러내는 과정
- HashSet은 객체를 저장하기 전에 먼저 객체의 hashCode() 메서드를 호출해서 해시 코드를 얻어낸 다음 저장되어 있는 객체들의 해시코드와 비교한 뒤 같은 해쉬 코드가 있다면 다시 equals() 메서드로 두 객체를 비교해서 true가 나오면 동일한 객체로 판단하고 중복 저장을 하지않는다.
- 문자열을 HashSet에 저장할 경우, 같은 문자열을 갖는 String 객체는 동일한 객체로 간주되고 다른 문자열을 갖는 String 객체는 다른 객체로 간주되는데 그 이유는 String 클래스가 hashCode()와 eqauls() 메서드를 재정의해서 같은 문자열일 경우 hashCode()의 리턴 값을 같게, equals() 리턴값은 true가 나오도록 했기 때문이다.
HashSet 사용법
HashSet<Integer> set1 = new HashSet<Integer>(); // HashSet 생성
HashSet<Integer> set2 = new HashSet<>(); // new에서 타입 파라미터 생략가능
HashSet<Integer> set3 = new HashSet<Integer>(set1); // set1의 모든 값을 가진 HashSet 생성
HashSet<Integer> set4 = new HashSet<Integer>(10); // 초기 용량 지정
HashSet<Integer> set5 = new HashSet<Integer>(10,0.7f); // 초기용량,load factor 지정
HashSet<Integer> set6 = new HashSet<Integer>(Arrays.asList(1,2,3)); // 초기값 지정
- HashSet을 기본으로 생성했을때는 초기용량은 16, load factor은 0.75의 값을 가진 HashSet객체가 생성된다.
- HashSet도 저장공간보다 값이 추가로 들어오면 List처럼 저장공간을 늘리는데 Set은 한칸씩 저장공간을 늘리지 않고 저장용량을 약 두배로 늘린다.
- 여기서 과부하가 많이 발생한다.
- 따라서 초기에 저장할 데이터 갯수를 알고 있다면 Set의 초기용량을 지정해주는 것이 좋다
HashSet 값 추가
HashSet<Integer> set = new HashSet<Integer>(); // HashSet 생성
set.add(1);
set.add(2);
set.add(3);
set.add(1); // 컴파일 오류나 런타임오류가 발생하지는 않는다- HashSet에 값을 추가할때 add() 메서드를 사용하면 된다.
- 입력되는 값이 HashSet 내부에 존재하지 않는다면 그 값을 HashSet에 추가해주고 true를 반환하고 HashSet에 값이 존재한다면 HashSet에 추가하지않고 false를 반환한다.
HashSet 값 삭제
HashSet<Integer> set = new HashSet<Integer>(Arrays.asList(1,2,3)); // HashSet 생성
set.remove(1); // 값 1 제거
set.clear(); // 모든 값 제거- HashSet에 값을 추가할때 remove() 메서드를 사용하면 된다.
- 값이 HashSet 내부에 존재하지 않는다면 False를 반환하고 HashSet에 값이 존재한다면 HashSet에서 제거하고 true를 반환한다.
HashSet 크기 구하기
HashSet<Integer> set = new HashSet<Integer>(Arrays.asList(1,2,3));//HashSet생성
System.out.println(set.size());//set 크기 : 3HashSet 값 출력
HashSet<Integer> set = new HashSet<Integer>(Arrays.asList(1,2,3)); // HashSet 생성
System.out.println(set);
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}- 리스트처럼 인덱스로 객체를 가져오는 get()메서드가 존재하지 않는다.
- 대신 전체 객체를 대상으로 한 번씩 반복해서 가져오는 반복자를 제공한다.
HashSet 값 검색
HashSet<Integer> set = new HashSet<Integer>(Arrays.asList(1,2,3));//HashSet생성
System.out.println(set.contains(1)); //set내부에 값 1이 있는지 check : trueTreeSet
- JDK 1.2부터 제공되고 있는 TreeSet은 HashSet과 달리 이진탐색트리 구조로 이루어져있다.
- 이진탐색트리는 추가와 삭제에는 시간이 조금 더 걸리지만 정렬,검색에 높은 성능을 보이는 자료 구조이다.
- 그렇기에 HashSet보다 추가,삭제는 시간이 더 걸리지만 검색과 정렬에는 유리하다.
- TreeSet은 데이터를 저장할시 인진탐색트리의 형태로 데이터를 저장하기에 기본적으로 nature ordering을 지원하며 생성자의 매개변수로 Comparator 객체를 입력하여 정렬 방법을 임의로 지정해 줄수도 있다.

- TreeSet 역시 TreeMap과 마찬가지로 이진탐색트리 중에서도 성능을 향상시킨 레드 블랙 트리로 구현되어있다.
- 레드 블랙 트리는 부모노드보다 작은 값을 가지는 노드는 왼쪽 자식으로, 큰 값을 가지는 노드는 오른쪽 자식으로 배치하여 데이터의 추가나 삭제 시 트리가 한쪽으로 치우쳐지지 않도록 균형을 맞추어준다.
TreeSet 사용법
TreeSet<Integer> treeSet1 = new TreeSet<Integer>(); // TreeSet 생성
TreeSet<Integer> treeSet2 = new TreeSet<>(); // new에서 타입 파라미터 생략가능
TreeSet<Integer> treeSet3 = new TreeSet<Integer>(treeSet1); // treeSet1의 모든 값을 가진 treeSet 생성
TreeSet<Integer> treeSet4 = new TreeSet<Integer>(Arrays.asList(1,2,3)); // 초기값 지정
- 생성하는 명령어는 HashSet과 크게 다르지 않으나 선언 시 크기를 지정해줄 수는 없다.
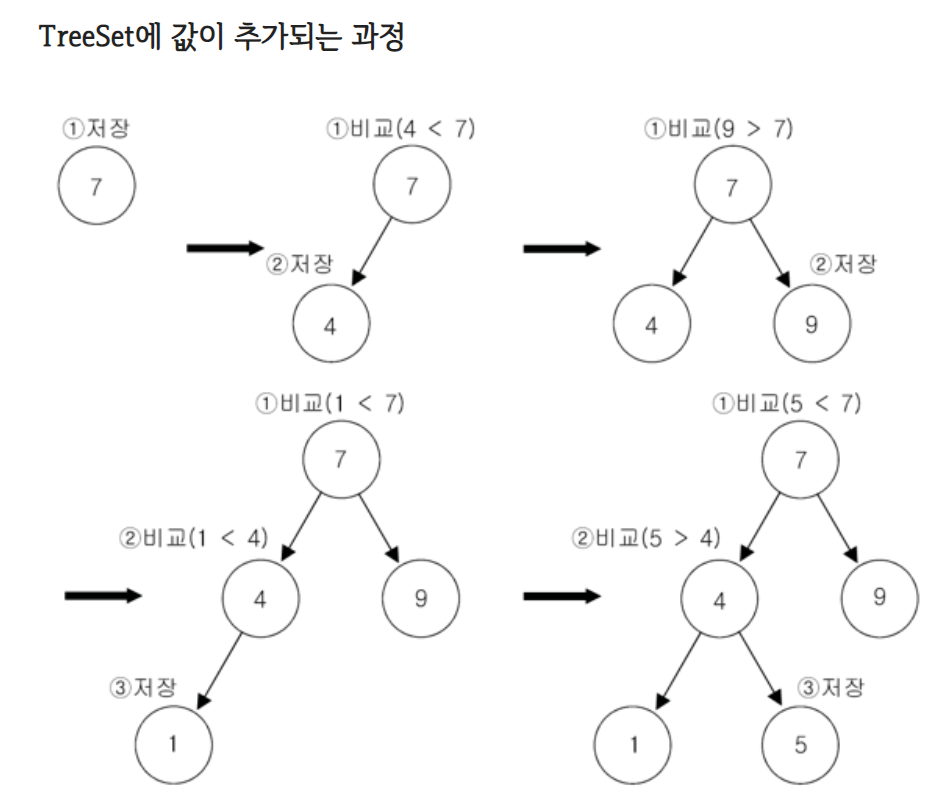
TreeSet 값 추가
TreeSet<Integer> set = new TreeSet<Integer>();//TreeSet생성
set.add(7); //값추가
set.add(4);
set.add(9);
set.add(1);
set.add(5);- 입력되는 값이 TreeSet 내부에 존재하지 않는다면 그 값을 추가한 뒤 true를 반환하고 내부에 값이 존재한다면 false를 반환한다.
TreeSet 값 삭제
TreeSet<Integer> set = new TreeSet<Integer>();//TreeSet생성
set.remove(1);//값 1 제거
set.clear();//모든 값 제거- 매개변수 value의 값이 존재한다면 그 값을 삭제한 후 true를 반환하고 없으면 false를 반환한다. 모든 값을 제거하려면 clear() 메서드를 사용하면 된다.
TreeSet 크기 구하기
TreeSet<Integer> set = new TreeSet<Integer>(Arrays.asList(1,2,3));//초기값 지정
System.out.println(set.size());//크기 : 3TreeSet 값 출력
TreeSet<Integer> set = new TreeSet<Integer>(Arrays.asList(4,2,3));//초기값 지정
System.out.println(set); //전체출력 [2,3,4]
System.out.println(set.first());//최소값 출력
System.out.println(set.last());//최대값 출력
System.out.println(set.higher(3));//입력값보다 큰 데이터중 최소값 출력 없으면 null
System.out.println(set.lower(3));//입력값보다 작은 데이터중 최대값 출력 없으면 null
Iterator iter = set.iterator(); // Iterator 사용
while(iter.hasNext()) {//값이 있으면 true 없으면 false
System.out.println(iter.next());
}output
[2, 3, 4]
2
4
4
2
2
3
4예제코드
/* LinkedHashSet Class */
public class LinkedHashSet<E> extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
...
public LinkedHashSet() {
super(16, .75f, true);
}
...
}
/* 여기서 부모 클래스의 생성인 super, 즉 HashSet의 오버로딩 생성자로 진입해보면 */
public class HashSet<E> extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
...
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
...
}- LinkedHashSet은 상위클래스인 HashSet을 만들고 내부적으로는 LinkedHashSet을 만들고 있다. TreeSet의 경우 정렬방법을 지장하여 순서대로 저장할수있다.
package me.whiteship.livestudy.Collections;
import java.util.*;
public class App {
public static void main(String[] args) {
// 오름차순으로 정렬하는 TreeSet
TreeSet<Integer> treeSet = new TreeSet<Integer>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1<o2 ? -1 : ((o1==o2) ? 0:1);
}
});
treeSet.add(3); treeSet.add(1); treeSet.add(2);
Iterator<Integer> iterator = treeSet.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
System.out.println();
// Using JAVA 8
TreeSet<Integer> treeSet1 = new TreeSet<>(
((o1, o2) -> o1<o2 ? -1: (o1==o2 ? 0:1))
);
treeSet1.add(3);
treeSet1.add(1);
treeSet.add(2);
treeSet.forEach(System.out::println);
}
}output
1
2
3
1
2
3- 위 코드의 출력은 입력된 <3, 1, 2> 의 순서와 다르게 정렬된 <1, 2, 3>의 순서로 출력된다.
output
유용한 컬렉션 메서드:
-
java.util.Collections의 클래스는 컬렉션을 다루는 작업에 유용한 기능들을 제공해준다.
-
Collections.copy(list,list): 복사본 만들기
-
Collections.reverse(list): 역순으로 정렬하기
-
Collections.shuffle(list): 무작위로 섞기
-
Collections.sort(list): 정렬하기
package me.whiteship.livestudy.Collections;
import java.util.*;
public class App {
public static void main(String[] args) {
List<String> list = createList();
List<String> list1 = new ArrayList<>();
Collections.shuffle(list);
list.forEach(System.out::println);
System.out.println();
Collections.sort(list);
list.forEach(System.out::println);
System.out.println();
Collections.reverse(list);
list.forEach(System.out::println);
System.out.println();
Collections.copy(list,list1);
list1.forEach(System.out::println);
System.out.println();
}
private static List<String> createList(){
List<String> list = new ArrayList<>();
list.add("hello");
list.add("hi");
list.add("good");
return list;
}
}output
good
hi
hello
good
hello
hi
hi
hello
goodCollections.sort()와 자바에서의 Comparator 사용
package me.whiteship.livestudy.Collections;
import java.util.*;
public class App {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(3,2,1,5,4,6,7);
Collections.sort(list);
list.forEach(System.out::println);
}
}output
1
2
3
4
5
6
7- 위는 Interger가 Comparable 인터페이스를 구현했기 때문에 가능하다.
- Comparable 인터페이스는 비교 대상보다 작으면 음수를, 같으면 0, 크면 양수를 반환하는 요소들의 쌍(pairwise) 비교를 수행하는 메서드를 정의한다.
- 이와 다르게 정렬하고 싶다면, 람다표현식을 사용해서 Comparator 인터페이스에 기반한 별도의 구현을 정의할수있다.
package me.whiteship.livestudy.Collections;
import java.util.*;
public class App {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(3,2,1,5,4,6,7);
Collections.sort(list,((o1, o2) -> o1>o2 ? -1 : (o1==o2)? 0:1 ));
list.forEach(System.out::println);
}
}
output
7
6
5
4
3
2
1- 어떠한 속성이라도 혹은 심지어 속성 조합 기준으로도 정렬가능하다.
- 예를 들어, income과 dataOfBirth라는 속성을 가진 Person 타입의 객체가 있다면, 필요에 따라 Comprator의 다른 구현을 정의하여 객체를 정렬할수있다.
컬랙션 동기화:
- 동기화는 작업들 사이의 수행 시기를 맞추는 것을 말한다.
- 동기화가 제공되는 것이 무조건적으로 좋은 것이 아니라 실행 속도 측면에서의 성능의 차이가 있기 때문에 상황에 따라서 적절하게 사용하는 것이 좋다.
리스트:
ArrayList:

- ArrayList는 동기화를 제공하지 않는다.
- 위 코드를 보면 알수있듯이 동기화를 위한 코드가 없다.
다음 벡터를 살펴보자.

- vector 클래스에서 요소를 추가하는 addElement 메서드를 보면 동기화를 제공하는
synchronized키워드가 있다. - 즉 내부적으로 Vector에서 요소 삽입 연산이 진행될 때 동기화가 보장된다는 것이다.
- 그러면 ArrayList 클래스도 동기화가 필요하다면 아래와 같이 코드를 변경하면 된다.
List<String> list = Collections.synchronizedList(new ArrayList<String>());
list.add("hi");
list.add("hallo");
list.add("hello");
synchronized (list){
Iterator iterator = list.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}HashSet:
- HashSet 클래스를 보면 ArrayList와 마찬가지로 동기화를 제공하지 않는다.
- 또한 추가되는 요소들의 순서도 보장하지 않는다.
- JDK 1.4 버전 부터 이를 보완하여 나온 클래스가 LinkedHashSet이 있다.
- 이 클래스의 생성자를 살펴보면 HasSet 클래스와는 조금 다른 것을 알수있다.

- 위 코드를 보면 LinkedHashSet은 상위클래스인 HashSet을 만들고 내부적으로 LinkedHashMap을 만들고 있다.
- 동기화를 제공하지 않는 Set은 앞서 살펴본 SynchronizeList 처럼 변환할수있다.
HashSet<String> hashSet = new HashSet<>();
Set<String> set = Collections.synchronizedSet(hashSet);HashTable:
- HashTable도 역시 중복을 허용하지는 않지만 HashMap과 다르게 Key와 Value의 값으로 null을 허용하지 않는다. HashMap 보다는 느리지만 동기화를 제공한다

- HashMap 역시 Collections.SynchronizedMap 메서드를 사용해서 동기화를 적용할수있다.
- 하지만 위 메서드를 사용하지 않는 동기화를 제공하지 않는 HashMap의 경우 ketSet을 순회하다가 새로운 값이 추가되는 경우에 이슈가 발생할수있다.
- 동기화를 제공하는 컬렉션은 이러한 경우 문제가 발생하지 않을 것이다.
Concurrent
-
java 1.5 버전 부터 등장한
java.util.concurrent패키지는 다양한 동시성 기능을 제공한다. -
HashMap에 동기화 기능을 적용한 ConcurrentMap이 여기에 속해있다.
-
동기화를 위해 SynchronizedMap을 사용할수있지만 지금 살펴볼 ConcurrentMap의 성능이 더 좋다.
-
그 이유는 바로 동기화 블록 범위에 있다.
-
ConcurrentMap은 동기화를 진행하는 경우 Map 전체에 락(Lock)을 걸지않고 Map을 여러 조각으로 나누어서 부분적으로 락을 거는 형태로 구현되어 있기 때문이다.
-
이러한 특징은 멀티쓰레드 환경에서 더 효율적인 성능을 보인다. 테스트를 해보자
package me.whiteship.livestudy.Collections;
import java.util.*;
import java.util.concurrent.*;
import java.util.stream.IntStream;
public class ConcurrentExample {
private static final int MAX_THREAD_POOL_SIZE = 5;
private static final int MAX_TEST_COUNT = 5;
private static final int MAX_OPERATE_COUNT = 100_000;
public static Map<String,Integer> testHashTable = null;
public static Map<String,Integer> testSyncMap = null;
public static Map<String,Integer> testConcMap = null;
public static void collectionPerformTest() throws InterruptedException{
testHashTable = new Hashtable<>();
runSomethinTest(testHashTable);
testConcMap = new ConcurrentHashMap<>();
runSomethinTest(testConcMap);
testSyncMap = Collections.synchronizedMap(new HashMap<>());
runSomethinTest(testSyncMap);
}
private static void runSomethinTest(Map<String, Integer> testTarget) throws InterruptedException {
System.out.println("Target Class" + testTarget.getClass());
long testAverageTime = 0L;
for (int testCount = 0; testCount < MAX_TEST_COUNT; testCount++) {
long testStartTime = System.nanoTime();
ExecutorService executorService = Executors.newFixedThreadPool(MAX_THREAD_POOL_SIZE);
// rangeClosed 는 마지막 값을 포함하여 Looping
IntStream.range(0,MAX_THREAD_POOL_SIZE).forEach(count -> executorService.execute(()->{
for (int i = 0; i < MAX_OPERATE_COUNT; i++) {
Integer randomValue =(int) Math.ceil(Math.random()*MAX_OPERATE_COUNT);
testTarget.put(String.valueOf(randomValue), randomValue);
}
}));
// 수행 종료. 이미 수행중인 것은 마저 진행하지만 새 작업은 허용하지 않는다.
executorService.shutdown();
// shutdown 이후에 모든 작업이 종료되기까지 대기한다.
executorService.awaitTermination(Long.MAX_VALUE,TimeUnit.DAYS);
long testEndTime = System.nanoTime();
long testTime = (testEndTime - testStartTime) / 1_000_000L;
testAverageTime += testTime;
System.out.println(testTarget.getClass()+"'s Test" + (testCount-1)+":"+testTime);
}
System.out.println(testTarget.getClass()+"'s average time is "+ testAverageTime);
System.out.println();
}
public static void main(String[] args) throws InterruptedException {
collectionPerformTest();
}
}output
arget Classclass java.util.Hashtable
class java.util.Hashtable's Test-1:376
class java.util.Hashtable's Test0:209
class java.util.Hashtable's Test1:168
class java.util.Hashtable's Test2:218
class java.util.Hashtable's Test3:194
class java.util.Hashtable's average time is 1165
Target Classclass java.util.concurrent.ConcurrentHashMap
class java.util.concurrent.ConcurrentHashMap's Test-1:165
class java.util.concurrent.ConcurrentHashMap's Test0:132
class java.util.concurrent.ConcurrentHashMap's Test1:107
class java.util.concurrent.ConcurrentHashMap's Test2:115
class java.util.concurrent.ConcurrentHashMap's Test3:110
class java.util.concurrent.ConcurrentHashMap's average time is 629
Target Classclass java.util.Collections$SynchronizedMap
class java.util.Collections$SynchronizedMap's Test-1:287
class java.util.Collections$SynchronizedMap's Test0:207
class java.util.Collections$SynchronizedMap's Test1:221
class java.util.Collections$SynchronizedMap's Test2:201
class java.util.Collections$SynchronizedMap's Test3:226
class java.util.Collections$SynchronizedMap's average time is 1142- ConcurrentHashMap이 압도적으로 빠른것을 확인할수있다.
정리:

