❗️❗️ [미완성] 아직 학습과 함께 작성 중인 포스팅입니다!
before
캐시에 대해 알아보기 전에 왜 캐시에 대해 알아야될까? 에 관해 알아보자면,
아주 간단한 서비스의 경우 구조는 대부분 다음과 같이 이루어져있다.
WEB - WAS - DB
그래서 다들 DB로 MySQL을 연결해서 간단한 웹 프로젝트를 진행해본 경험이 있을 것이다.
이런 프로젝트의 경우 대부분 사용자가 많지 않아 데이터 베이스에 딱히 무리가 가지 않는다.
하지만, 사용자가 많아진다면 데이터 베이스는 과부하가 될 가능성이 있다. (scalability 이슈에 직면하게 된다.)
이런 경우를 방지하기 위해 캐시(Cache) 라는 개념을 적용하게 된다.
캐시(Cache)란?
캐시 메모리는 CPU 칩 안에 들어간 작고 빠른 메모리로,
이전에 요청했던 결과를 임의로 저장해둔 뒤 빠르게 서비스해주는 것을 의미한다.
원래대로라면, 프로세서가 매번 메인 메모리에 접근하여 데이터를 받아오게 된다.
하지만! 매번 그렇게 진행하게 된다면 계속 같은 데이터를 요청할 경우 시간이 낭비되기 때문에, 자주 사용하는 데이터의 경우 캐시에 담아두고 프로세서가 메인 메모리 대신 캐시에 접근하도록 하여 처리 속도를 높여주는 것이다.
한마디로, 백엔드를 통해서 계속해서 같은 데이터를 DB에 요청하는 것이 아니라, 읽어온 데이터를 '임의의 공간' 에 저장하여 나중에 동일한 요청이 오면 DB(또는 API)를 참조하지 않고 요청을 처리하는 기법이다.
캐시 서버(Cache Server)는 이때 위에서 말한 임의의 공간이다.
클라이언트와 서버 사이에 위치하며 임의로 저장하는 Middlebox로서, 다음번 요청시 DB에 요청하지 않고 캐시 서버를 통해서 결과값을 빠르게 받을 수 있도록 도와주는 공간이다.
언제 필요할까?
- 파레토 법칙에 의하여 자주 조회되는 기능(20%)을 캐시로 적용한다면 효율을 끌어올릴 수 있다.
- 원본 데이터에 접근하는 시간이 오래 걸리는 경우 시간을 절약할 수 있다.
- 동일한 입력에 대해서 항상 동일한 결과를 반환하는 기능에 적합하다.
- 데이터를 동기화를 자주 시켜야 하는 변경이 잦은 데이터는 적합하지 않다.
- 요약) 자주 조회되고, 수정이 자주 발생하지 않는 정보들. ex) 세계 top10 기업,대도시..
자주 사용하는 데이터란?
'자주 사용하는 데이터'에 관한 판단은 지역성 원리를 따른다.
지역성 원리란 시간 지역성, 공간 지역성으로 구분할 수 있는데, 먼저시간 지역성이란 최근 접근한 데이터에 다시 접근하는 경향을 뜻하며공간 지역성은 최근 접근한 데이터의 주변 공간에 다시 접근하는 경향을 말한다.
관련 포스팅 참조
유사하게 생각해볼 수 있던 쿠키&세션,캐시 관련 포스팅을 참조해볼 수 있다.
캐시 서버 동작 방식
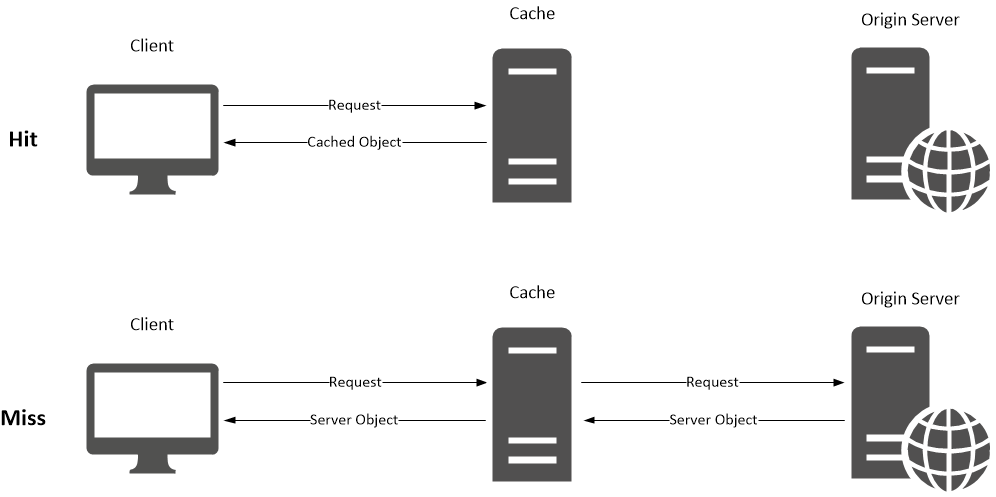
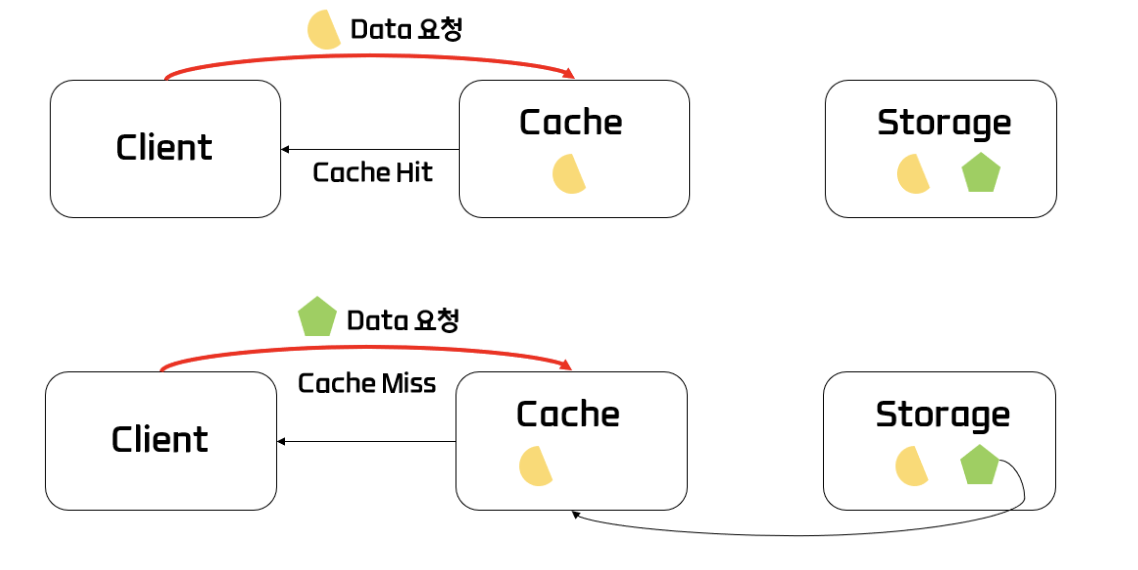{kind=link}
- 이때 만약 Client에서 요청한 Data가 Cache Server에 있을 경우, 이를
Cache hit라고 한다.- 이때 만약 Client에서 요청한 Data가 Cache Server에 없을 경우. 이를
Cache miss라고 하며 웹 서버에 데이터를 요청해서 받아오게 된다.
캐시 종류(방식)

1. Local Cache
Local Cache는 로컬 서버 내부 저장소 에 데이터를 보관한다.
Application에서 바로 접근하기 때문에 속도가 빠르다는 장점이 있지만,
Application이 Scale-out 된 다중 서버 환경에서는 각 서버에 중복된 데이터를 보관해야 하며, 동기화되지 않기 때문에 데이터의 정합성 문제가 발생할 수 있다.
ex) Cache Abstraction, Caffeine, EhCache…
2. Global Cache
서버와 분리된 별도 저장소(Cache Server) 에 데이터를 보관한다.
Application에서 접근할 때 네트워크 I/O가 발생하기 때문에 Local Cache보다 속도가 느리지만, 중복 데이터 및 데이터 정합성 문제를 해결하는 장점이 있다.
ex) Redis...
예제
- 데이터의 양이 많지 않고, 중복으로 저장되더라도 부하가 적으며, 데이터의 일관성이 깨져도 비즈니스에 큰 영향이 없는 기능(데이터) 일 때는
Local Caching방식 선택- 데이터의 양이 많아서, 중복으로 저장하게 되면 자원을 낭비하며, 비즈니스 관점에서 데이터의 일관성이 중요한 기능(데이터) 일 때는
Global Caching방식 선택
캐싱 전략(구조)
캐시를 어떻게 사용하는가?! 캐시 서버는 2가지 패턴이 존재한다.
1. Look Aside (Lazy Loading)
캐시를 옆에 두고 필요할 때만 데이터를 캐시에 로드 하는 방식이다.
- 클라이언트가 데이터를 요청
- 웹 서버가 데이터가 존재하는지 Cache 서버에서 확인
- Cache 서버에 데이터가 존재한다면 바로 반환(
Cache Hit), 없다면 DB에서 데이터 조회(Cache Miss)
장점
이 구조를 사용한다면 실제로 사용되는 데이터만 캐시할 수 있고, Redis의 장애가 애플리케이션에 치명적인 영향을 주지 않을 수 있다.
단점
캐시에 없는 데이터를 쿼리할 때 시간이 더 오래 소요될 수 있고, 캐시가 최신 데이터로 업데이트 되어있지 않을 수 있다. (Redis도 같이 update하여 동기화가 필요해진다.)
2. Write Back
데이터를 모두 캐시로 미리 저장 해놓고, 특정 시점마다 캐시 내 데이터를 DB에 insert, update 하는 방식이다.
- 웹 서버는 모든 데이터를 Cache 서버에 저장 (특정 시간 동안 데이터가 저장)
- Cache 서버에 있는 데이터를 일정 주기마다 DB에 저장 (배치)
- DB에 저장된 Cache 서버의 데이터를 삭제
장점
DB에서 디스크를 접근하는 횟수가 줄어들기 때문에 성능 향상을 기대할 수 있다.
주로 쓰기 작업이 많아서 insert 쿼리를 일일이 날리지 않고 한꺼번에 배치 처리를 하기 위해 사용한다. (insert 쿼리를 한 번씩 500번 날리는 것보다 insert 쿼리 500개를 붙여서 한 번에 날리는 것이 더 효율적이라는 원리)
단점
서버가 장애로 다운된다면 메모리 공간이므로 데이터가 손실 될 수 있다.
(때문에 이 방식은 무겁거나, 재생 가능한 데이터일 때 사용된다.)
Redis
Remote 외부 + dictionary HashMap<key,value> + server 서버
외부 저장 장치에 데이터를 저장하지 않고 메모리상에 데이터를 저장하는 구조의 In-Memory 데이터베이스이다.
네트워크를 타지 않는 Local caching에 비해서는 느리지만, 메모리와 디스크 간 병목이 없기 때문에 disk-based DB보다 속도가 빠르다는 장점이 있다.
(→ 이것에 관해 더 자세히 이해하고자 한다면 메모리 계층구조(Memory Hierarchy)에 대해 학습해보기를 권장한다.)
언제 사용할까?
여러 서버에서 같은 데이터를 공유 할때, Cache 등의 기능을 사용할 때 주로 사용된다.
자료구조
Redis 는 기본적으로 Key - value 형식을 따르는데,
이때 Key-Value 스토리지에서 Value는 단순한 Object가 아니라 다양한 자료구조를 제공받고 있다.
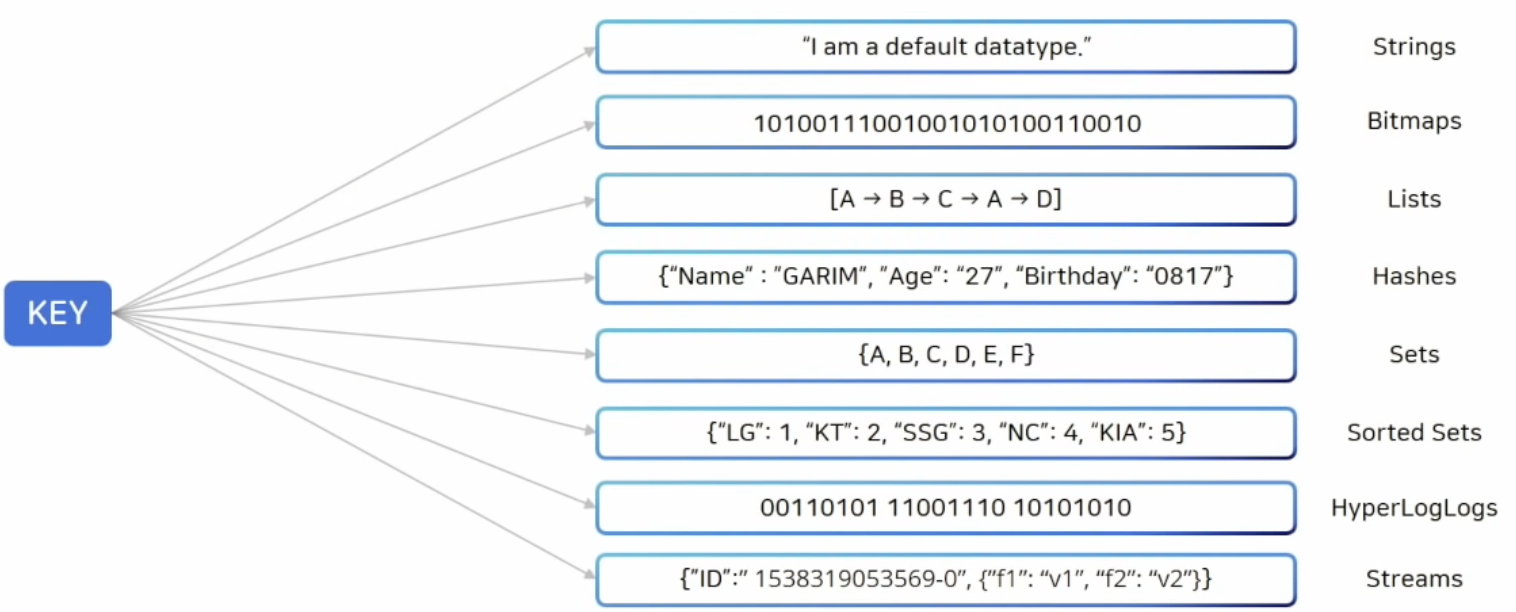
- Strings : Vinary-safe한 기본적인 key-value 구조
- Lists : String element의 모음, 순서는 삽입된 순서를 유지하며 기본적인 자료구로 Linked List를 사용
- Sets : 유일한 값들의 모임인 자료구조, 순서는 유지되지 않음
- Sorted sets : Sets 자료구조에 score라는 값을 추가로 두어 해당 값을 기준으로 순서를 유지
- Hahses : 내부에 key-value 구조를 하나더 가지는 Reids 자료구조
- Bit arrays(bitMaps) : bit array를 다를 수 있는 자료구조
- HyperLogLogs : HyperLogLog는 집합의 원소의 개수를 추정하는 방법, Set 개선된 방법
- Streams : Redis 5.0 에서 Log나 IoT 신호와 같이 지속적으로 빠르게 발생하는 데이터를 처리하기 위해서 도입된 자료구조
이때, Redis Collections 를 사용할 때 주의점은, 하나의 컬렉션에 너무 많은 아이템을 담으면 좋지 않않으므로 적당한 수준의 데이터 셋을 유지하는게 Redis 성능에 영향주지 않는다.
주의사항
- Single Thread 서버 이므로 시간 복잡도를 고려해서 명령어를 사용해야한다.
- In-memory 특성상 메모리 파편화, 가상 메모리등의 이해가 필요하다.
[참고] 메모리 관리
- 메모리 파편화
메모리를 할당받고 해제하는 과정에서 공간이 남고 사용하기가 어렵게 되는데, 그래서 redis를 사용할 때는 메모리를 적당히 여유있게 사용해야한다.
- 가상 메모리 swap
실제로 프로세스를 올릴 때 일부만 올리고 나머지는 필요할 때 올리게 되는데, 이 과정에서 latency가 발생하게 되고 그 latency가 길어지게 되면 single thread 환경이기 때문에 문제가 발생할 가능성이 있다. 때문에 swap과 관련하여 이를 고려해봐야한다.
- Replication - Fork
휘발성을 가지고 있는 In-Memory 이기 때문에 복사 기능을 제공하는데 이 과정에서 fork 방식을 사용하게 되는데, 이 과정에서 메모리가 가득 차있다면 복사본이 제대로 생성되지 않고 서버가 죽을 수 있으므로 메모리를 여유있게 사용해야한다.
EhCache
EhCache는 Spring에서 간단하게 사용할 수 있는 Java기반 오픈소스 캐시 라이브러리이다.
위의 Redis같은 캐시 엔진들도 있지만, EhCache는 데몬을 가지지 않고 Spring 내부적으로 동작하여 캐싱 처리 를 한다.
(즉, Spring Application과 동일하게 프로세스 라이프 사이클을 가져간다.)
Redis의 경우 별도의 서버를 사용하기 때문에 네트워크 지연,단절같은 이슈가 발생할 위험이 있는데,
EhCache는 위의 위험에서 자유롭고, 같은 로컬 환경 일지라도 별도로 구동하는 memcached 와는 다르게 서버 어플리케이션과 라이프사이클을 같이 하므로 사용하기 간편하다는 장점이 있다.
언제 사용할까?
위에서 언급했던 Global Cache, Local Cache 중 어떤 캐시 방식을 선택할 것인가에 따라 고려된다.
Spring Caching
Spring은 캐시 관련 기능을 추상화하여 편리하게 개발할 수 있도록 지원하고 있다.
추상화를 제공했다는 말은, 인터페이스를 제공해서 거기서 다양한 캐시 구현체를 사용할 수 있도록 한 것이다.
만약 스프링이 캐싱 기능을 제공해주지 않았다면, 우리는 직접 Redis 를 통해 구현해야할 것이다.
@Autowired
StringRedisTemplate redisTemplate;
public void getBookTitle(String bookId) {
ValueOperation<String, String> ops = redisTemplate.opsForValue();
String value = ops.get("bookKey:"+bookId); //직접 데이터를 조회하고,
if(value==null){
value = bookRepository.getBookTitle(bookId);
ops.set("bookKey:"+bookId, value, 5, TimeUnit.SECONDS); //직접 데이터를 추가한다.
}
return value;
}하지만 스프링이 캐싱 기능을 제공해준 덕분에, 우리는 이제 @Annotation을 사용해 손쉽게 메소드에 캐싱 적용이 가능하다.
스프링이 캐시 서비스를 적용하는 기능을 제공하는 방식은 AOP 방식 을 사용하고 있다. 덕분에 개발자는 애플리케이션 코드를 수정하지 않고 캐시 부가기능을 추가할 수 있다.
(추가적으로, 스프링부트 자체에서 스프링부트 어플리케이션을 실행하면 캐시 공간을 마련하기도 한다. 다만, 이 공간은 한정적이므로 많은 캐시를 저장하는 것에는 적합하지 않다.)
기본적으로 Spring에서 Cache를 사용하기 앞서서는 캐싱 기능을 사용할 스프링부트 어플리케이션에 @EnableCaching 이라는 어노테이션을 붙여주면 된다. (세부적으로 설정하기 위해서는 별도로 CacheManager를 빈으로 등록하여 사용할 수 있다.)
@Annotation
Spring은 AOP 기반으로 메소드에 적용할 수 있는 어노테이션들을 제공해주는데, 해당 어노테이션을 통해 별도의 캐시 메서드를 정의하지 않고도 캐시를 제어할 수 있다.
-
@Cacheable: 캐시를 저장/조회
해당 어노테이션이 있으면 캐시에 데이터가 있을 경우 캐시의 데이터를 반환시켜주고, 캐시에 데이터가 없을 경우 로직을 실행한 후에 반환 값을 캐시에 데이터를 추가해준다. -
@CachePut: 캐시 저장
해당 어노테이션은 위와 유사하게 실행 결과를 캐시에 저장하지만, 조회 시에 저장된 캐시의 내용을 사용하지 않고 항상 메소드의 로직을 실행한다는 점이 다르다. -
@CacheEvict: 캐시 제거
해당 어노테이션은 캐시 이름을 넣어주면 메소드가 실행될 때 캐시의 내용이 제거된다. 데이터의 값이 달라진다면 잘못된 값을 반환할 수 있기 때문에 일정한 주기 혹은 데이터의 값이 변경 시점에 제거 되어야한다.
더 자세한 설명에 관해 아직 정리를 마무리 짓지 못한 상태입니다.
[참조]
https://wildeveloperetrain.tistory.com/21
https://steady-coding.tistory.com/586
https://parksb.github.io/article/29.html
https://wonyong-jang.github.io/bigdata/2021/05/10/BigData-Redis-Caching.html
https://velog.io/@qotndus43/Cache - 그림 참조
https://2kindsofcs.tistory.com/40 - In-Memory
https://youtu.be/Gimv7hroM8A - Redis 테코톡
https://inpa.tistory.com/entry/REDIS-%F0%9F%93%9A-%EB%8D%B0%EC%9D%B4%ED%84%B0-%ED%83%80%EC%9E%85Collection-%EC%A2%85%EB%A5%98-%EC%A0%95%EB%A6%AC#top - Redis 자료구조
https://velog.io/@noakafka/Redis-vs-Ehcache-무엇을-쓸까
https://jaehun2841.github.io/2018/11/07/2018-10-03-spring-ehcache/ - Ehcache
https://mangkyu.tistory.com/179 - spring cache
파피의 Caching 캐싱 테코톡
