
MongoDB (개념)
MongoDB는 고성능, 고가용성 및 쉬운 확장성을 제공하는 NoSQL, Document 지향 데이터베이스이다.
웹 서비스가 발전하면서 데이터 무결성을 버리면서까지 더 많은 데이터, 빠른 성능, 수평 확장이 필요한 데이터베이스가 필요해졌다. 그런 요구 사항으로 인해 MongoDB가 탄생했다.
Document
이때, Document는 JSON과 유사한 형식인 BSON(Binary JSON)으로 되어있다.
이를 통해 데이터를 배열 및 중첩 Document와 같은 복잡한 데이터 유형을 효율적으로 저장할 수 있다.
{
name: "kim", <-- {filed}:{value}
age: 20, <-- {filed}:{value}
groups: ["student", "girl"] <-- {filed}:{value}
}BSON
BSON이란,
filed와vlaue값을 가지고 있는 데이터 구조이다.
일반 JSON에 비해 BSON 은 문서 자체의 여백을 줄여 데이터 용량을 절약하고 로우 레벨(c언어)의 데이터 형태이기 때문에 인코딩 디코딩도 무척 빨라 성능에 큰 지장을 주지 않는다.
MongoDB에서 사용되는 이진 직렬화 형식으로 데이터를 이진 형태로 변환하여 저장 및 전송하기 때문에 텍스트 형식보다 적은 용량을 사용하며, 처리 속도가 빠르다는 장점이 있다. 또한 이진 직렬화 형식은 데이터 구조를 순회하거나 탐색하는 것이 쉽다는 장점이 있다.
ObjectId 구조
MySQL의 PK 처럼 MongoDB에는 ObjectId 라는 고유한 키 개념이 존재한다.
차이점은 Primary Key는 DBMS가 부여한다면 ObjectId는 클라이언트에서 직접 생성한다는 점이다.
때문에, ObjectId에 대한 전략도 직접 정할 수 있으며 (ex.TSID) 만약 ObjectId를 넣지않고 저장한다면 데이터가 그대로 저장된다.
또한 주의할 부분으로, ObjectId 값은 초 단위 이상까지는 ObjectId의 생성 시점과 ObjectId 값의 순서가 보장되지만,
같은 초(Single second)에 생성된 ObjectId 값은 반드시 순서가 보장되지는 않는다는 점이다. (마지막 3byte에서 일정 값 이후에는 auto increment가 처음으로 초기화되기 때문이다.)
mongo> var oid = ObjectId()
mongo> print(oid.getTimeStamp()) //생성된 ObjectId에서 Timestamp 부분 출력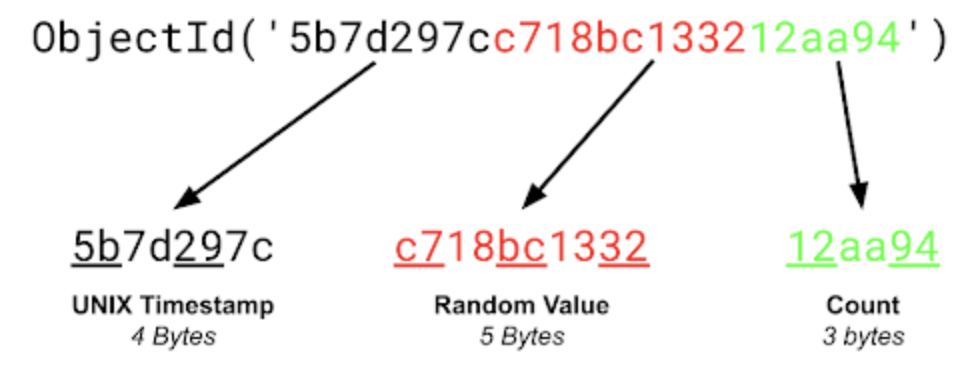
ObjectId는 12바이트의 Binary Data 데이터 타입으로 총 세 영역으로 나눠져있다.
- 첫번째 4 Byte : UNIX Timestamp 정보 (이를 통해 생성 시각별 정렬이 가능하다)
- 둘째 5 Byte : 난수 또는 무작위 값 (서버, 프로세스 아이디)
- 마지막 3 Byte : 무작위 값에서 Auto Increment 되는 값으로 구성된다.
네임스페이스
MongoDB 에서는 데이터베이스 이름과 컬렉션 이름의 조합을 네임스페이스(Namespace)라고 한다.
ex) user.loginInfo 는 user 데이터베이스의 loginInfo 컬렉션을 지칭하는 네임스페이스이다.
네임스페이스가 중요한 이유는 MongoDB 내부적으로 데이터베이스 이름이나 컬렉션 이름이 단독으로 사용되지 않고 항상 데이터베이스와 컬렉션을 붙인 네임스페이스로 각 객체가 관리 참조되기 때문이다.
쿼리
쿼리 언어는 MySQL이 SQL을 사용하는 것과 다르게 JavaScript 기반의 쿼리 언어를 사용한다.
간단하게 다음 예제에서와 같이 MongoDB 명령들은 JSON 도큐먼트를 인자로 사용한다.
// insert into users (name, age) values ('kim', 20);
db.users.insert(
{
name: 'kim',
age: 20
}
)
// update users set age = 20 where id = bcd100232sdes;
db.users.updateOne(
{ id: 'bcd100232sdes' },
{ $set: { age: 20 } }
)
// select * from users where id = bcd100232sdes;
db.users.find(
{
id : 'bcd100232sdes'
}
)스토리지 엔진
스토리지 엔진은 사용자의 데이터를 디스크와 메모리에 저장하고 읽어오는 역할을 담당한다.
사용자가 데이터를 저장하거나 조회하면 MongoDB 서버는 옵티마이저(Optimizer)을 통해 최적화된 실행 계획을 수립하게 되는데, 그 수립된 실행 계획에 맞게 이제 디스크에서 데이터를 어떻게 가져오고 저장할지를 결정하는 부분이 스토리지 엔진인 것이다.
MongoDB 서버도 MySQL 서버와 동일하게 다양한 스토리지 엔진을 사용할 수 있지만,
현재 MongoDB 3.0 이상부터는 WiredTiger 스토리지 엔진을 기본적으로 사용하고 있다.
인덱스
트랜잭션
MonoDB는 ACID를 준수하는 데이터베이스이다.
BASE → ACID
초기에 MongoDB는 NoSQL로서 일관성을 중요시하는 ACID 보다 가용성을 우선시하는 BASE 속성(Basically Available, 일관성)을 우선시하여 설계되었다.
- 일관성 (Consistency) : 모든 사용자가 동일한 데이터를 보는 것에 중점
- 가용성 (Availability) : 시스템이 항상 작동 가능하고 사용자의 요청에 응답하는 것에 중점
BASE
- Basically Available : 가용성, 기본적으로 언제든지 사용할 수 있다.
- Soft state : 외부의 개입 없이도 정보가 바뀔 수 있다.
- Eventually consistent : 유연한 일관성. 시간이 지나면 일관적인 상태를 유지한다.
하지만, 이제 MongoDB는 트랜잭션이 일관성을 유지하는 원칙을 따르기 때문에 BASE 호환성은 가지지 않는다고 볼 수 있다.
문서 데이터 모델을 통해 관련된 데이터를 함께 저장함으로써 트랜잭션이 필요하지 않을 수 있지만, 필요한 경우 Multi-Document ACID Transaction, Shard Cluster Transaction도 지원된다.
WiredTiger 스토리지 엔진
기본적으로 WiredTiger 스토리지 엔진도 트랜잭션을 지원하는 B-Tree 기반의 스토리지 엔진으로 RDBMS와 흡사한 내부 구조로 되어있다.
단, MongoDB의 트랜잭션은 MySQL의 트랜잭션과 약간 다르다.
MongoDB의 기본 스토리지 엔진 중 트랜잭션 처리에 사용되는 WiredTiger 스토리지 엔진이 제공하는 트랜잭션의 ACID는 다음과 같다.
- 최고 레벨의 격리 수준은 Snapshot (Repeatable-Read)
- 트랜잭션의 Commit과 체크포인트 2가지 형태로 영속성 보장
- 커밋되지 않은 변경 데이터는 공유 캐시 크기보다 작아야 함
MongoDB 공식 문서를 살펴보면, F
Spring & MongoTransactionManager
Spring 에서 @Transactional 을 통해 몽고 트랜잭션을 사용하기 위해선 몇가지 알아둬야할 점들이 있다.
(1) 먼저,mongoDB에서 트랜잭션은 선택사항이다.
때문에 Spring Boot에서는 mongoDB가 등록된 라이브러리를 보고도 자동으로 스프링 컨테이너에 Bean으로 올려주지 않는다. 그래서 우리는 직접 mongoTransactionManager를 스프링 컨테이너에 올려 주어야 한다.
(2) 또한, 트랜잭션을 활용하려면 MongoDB를 레플리카 셋 또는 샤드된 클러스터로 구성해야 한다.
트랜잭션은 논리적인 세션의 개념으로 만들어졌는데, 이때 트랜잭션의 상태를 기록하는 oplog(운영 로그)가 레플리카 셋 환경에서만 사용가능하기 때문에 레플리카 셋 환경의 구성이 필수적이다.
🚨 만약 위와 같은 설정을 하지 않았다면, 다음과 같은 오류가 발생한다.
com.mongodb.MongoCommandException: Command failed with error 263 (ShardingOperationFailed):
'Transaction numbers are only allowed on a replica set member or mongos' on server localhost:27017. The full response is { "ok" : 0.0, "errmsg" : "Transaction numbers are only allowed on a replica set member or mongos", "code" : 263, "codeName" : "ShardingOperationFailed" }Replica Set
MongoDB는 클러스터를 구성하기 위한 가장 간단한 방법으로 Replica Set을 이용할 수 있다.
방법은 크게 2가지 방식이 존재한다.
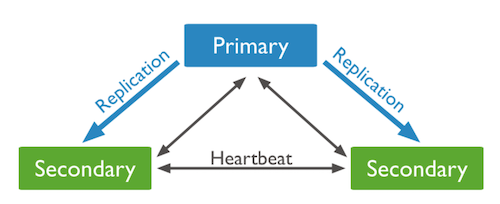
(1) P-S-S
P-S-S 시스템은 하나의 Primary와 여러 개의 Secondary로 이루어진 Replica Set이다.
만약 Primary가 죽을 경우 투표를 통해 남은 Secondary 중 새로운 Primary를 선출한다. 여기서 만약 Secondary가 하나만 남았다면 새로운 Primary를 선출할 수 없어 서버 장애가 발생한다.
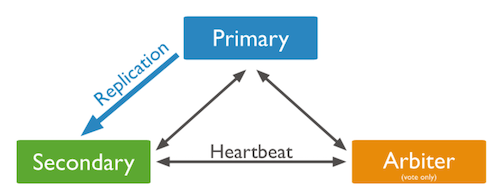
(2) P-S-A
P-S-A 시스템은 하나의 Primary와 Arbiter 그리고 여러 개의 Secondary로 이루어진 Replica Set이다.
P-S-A 시스템에선 Primary가 죽은 경우 Arbiter가 Secondary와 함께 투표해서 Secondary 중 새로운 Primary를 선출한다. P-S-A 시스템에선 Secondary가 하나만 남았더라도 Arbiter가 남아있어서 남은 Secondary를 Primary로 선출 할 수 있어서 정상적으로 서비스가 동작한다.
Project (실무 도입)
기술 선정 이유
채팅 시스템에서 데이터베이스를 선택하는 예시로 다음과 같은 상황을 고려해볼 수 있습니다:
프로젝트의 세부 사항:
- 데이터의 구조와 관계: 채팅 시스템에서는 어떤 데이터가 저장되어야 하는지, 데이터 간의 관계가 어떻게 형성되는지 등을 고려해야 합니다. 만약 데이터가 정형화되어 있고 관계형으로 표현하는 것이 자연스럽다면 MySQL이 적합할 수 있습니다. 반대로, 유연한 데이터 구조가 필요하거나 중첩된 데이터가 많은 경우 MongoDB가 유용할 수 있습니다.
- 데이터 양 및 확장성: 예상되는 데이터 양과 사용자 수가 많은 경우, MongoDB의 확장성과 성능이 더 적합할 수 있습니다. MongoDB는 수평적 확장이 용이하고 대용량 데이터 처리에 강점을 가지고 있습니다.
우선순위:
- 실시간 기능 요구: 채팅 시스템에서 실시간으로 메시지를 전송하고 읽음 표시 등을 처리해야 한다면, MongoDB의 실시간 데이터 처리 기능이 유용합니다. MongoDB는 Change Streams와 같은 기능을 제공하여 실시간 이벤트 감지 및 처리를 지원합니다.
- 트랜잭션 요구: 채팅 시스템에서 메시지의 상태 변경에 대한 일관성과 트랜잭션 처리가 필요한 경우, MySQL의 ACID 트랜잭션 기능이 적합할 수 있습니다. MySQL은 복잡한 트랜잭션 처리에 강점을 가지고 있습니다.
예를 들어, 채팅 시스템이 많은 사용자를 지원하고, 실시간 기능과 유연한 데이터 모델링이 필요한 경우 MongoDB가 더 적합할 수 있습니다. 반면에 채팅 시스템이 상대적으로 소규모이고, 메시지의 읽음 표시나 상태 변경에 대한 일관성이 중요한 경우 MySQL이 적합할 수 있습니다.
이러한 예시를 토대로 프로젝트의 세부 사항과 우선순위를 고려하여 데이터베이스 선택을 결정할 수 있습니다. 최종적인 판단은 프로젝트의 요구사항과 용도에 맞는 데이터베이스를 선택하는 것이 가장 적절합니다.
데이터 모델링
MongoDB는 흔히 Schemaless Database 라고 알려져있다.
Schemaless Database 란, 사전에 데이터 구조를 정하지 않고 유연하게 다양한 형태의 구조로 데이터를 저장하고 관리할 수 있는 데이터베이스를 뜻한다.
때문에 Schemaless Database 에서 데이터 모델링시 핵심은 다큐멘트의 구조와 애플리케이션이 데이터 관계를 어떻게 나타내는지이다.
MongoDB는 관련 데이터를 하나의 다큐멘트 안에 포함하도록 한다.
두 가지 방법으로 관계에 대한 표현을 할 수 있는데, 하나의 다큐멘트 안에 포함시키는 Embedded 방식, 참조하도록 하는 Reference 방식이다.
1. Embedded 설계
Embedded Data 모델에서는 유관한 데이터를 하나의 다큐멘트에 담는 형식이다.
애플리케이션이 유관한 정보 조각들을 하나의 데이터베이스 레코드에 저장하기 때문에, 결과적으로 애플리케이션은 더 적은 쿼리와 업데이트를 가지고 필요한 작업을 수행할 수 있게 된다.
2. Reference 설계
모델링 설계시 고려할 점
MongoDB의 매뉴얼을 중심으로 많은 블로그나 소개글에서 (MongoDB는 MySQL처럼 범용적으로 사용할 수 있는 조인을 지원하지 않기 때문에) 컬렉션에서 최대한 데이터를 내장(Embed)할 것을 권장하고 있다.
하지만 만약 많은 데이터를 하나의 도큐먼트(컬렉션)에 내장할수록 도큐먼트 하나하나의 크기가 커지기 때문에, 더 많은 디스크 읽기 오퍼레이션이 필요하고 메모리의 캐시 효율은 떨어질 수 있다.
예제로, 만약 게시물에 대한 조회수를 게시물이라는 도큐먼트에 함께 저장할 때와(임베디드 설계) 조회수를 다른 도큐먼트로 두고 따로 설계할 때와(레퍼런스 설계)에 대해 생각해본다면,
- 장점 ) 게시물과 조회수를 하나의 쿼리로 동시에 가져올 수 있기 때문에 조회가 빠르다.
- 단점 ) 게시물의 경우 게시물 작성보다 조회가 많은 특성의 서비스이고, 때문에 조회수 update 쿼리가 조회보다 더 빈번하게 발생할 수 있는데, 이때마다 카운터 필드 하나를 바꾸기 위해 전체 게시물 도큐먼트를 통째로 변경해야한다.
이때 레퍼런스 설계로 진행할 경우 조회수만 저장하는 컬렉션의 크기가 크지 않아서 많은 변경 쿼리가 유입되더라도 실제 WiredTiger 스토리지 엔진의 캐시에 변경이 가해지는 블록(페이지)의 수가 통합된 컬렉셔느이 경우보다 훨씬 적기 때문에 디스크로 동기화해야할 데이터의 크기가 줄어들어 디스크 부하를 덜 일으킨다.
또한 과도한 임베디드 설계로 도큐먼트 하나의 크기가 비대해진다면, 하나의 필드를 읽기 위해 비대한 도큐먼트 전체를 조회해야하므로 네트워크 전송량 제한이 병목 지점이 될 수 있다.
(ex. 하나의 도큐먼트가 30KB, 초당 6000-7000쿼리 실행 기준, 네트워크 사용량은 1Gbps 이상 필요)
[참조]
* 개념
몽고DB 완벽 가이드
https://kciter.so/posts/about-mongodb
* 데이터 모델링
지마켓 기술 블로그
nhn 기술 블로그
https://gamguma.dev/post/2022/04/mongodb_schema_design
* 트랜잭션
https://www.nextree.io/mongodb-transaction/
https://jh2021.tistory.com/24
https://zzihyeon.tistory.com/51?category=460732
https://www.mongodb.com/community/forums/t/why-replica-set-is-mandatory-for-transactions-in-mongodb/9533
