스프링이 어떻게 데이터베이스와 연결하고 쿼리를 통해 정보를 가져올 수 있을까 ?
스프링에서 어떻게 데이터베이스의 트랜잭션을 관리할 수 있을까?
Spring DB
커넥션 풀 (DB 커넥션 관리)
애플리케이션(WAS)이 데이터베이스에 쿼리를 실행하거나 데이터를 가져오기 위해서는 먼저 데이터베이스와의 커넥션(Connection)을 맺어야 한다.
(* 커넥션 : 데이터베이스와 애플리케이션 간의 연결)
커넥션은 일반적으로 네트워크 연결(3 way handshake 같은 TCP/IP 연결)을 통해 DB 서버에 연결되며, 연결이 맺어지면 쿼리를 수행할 수 있다.
커넥션을 얻는 방법
먼저 커넥션 연결하는 코드를 직접 구현하는 방법이 있다. (ex. JDBC DriverManager)
하지만 매번 커넥션을 직접 연결하게 되면 SQL을 실행하는 시간 뿐만 아니라 커넥션을 새로 만드는 시간이 추가 되기 때문에 결과적으로 응답 속도가 지연될 수 있다.
이런 문제를 해결하고자, 우리는 커넥션을 미리 생성해두고 사용하는 방법인 커넥션 풀을 사용한다. (ex.대표적으로 HikariCP)
이를 통해 데이터베이스에 접근할 때마다 연결을 맺고 끊는 오버헤드를 줄일 수 있다.
Connection Pool
커넥션 풀은 이름 그대로 '커넥션을 얻고 관리하는 풀(Pool)' 이라는 방법이다.
커넥션 풀은 애플리케이션이 시작될 때 미리 생성되어 풀에 유지된다.
이제 매번 새로운 커넥션을 맺을 필요없이 커넥션 풀을 통해 이미 생성되어있는 커넥션을 객체 참조로 그냥 가져다 쓰기만 하면 된다. (이때 커넥션 풀은 애플리케이션 실행 속도에 영향을 주지 않기 위해 별도의 쓰레드를 사용해서 커넥션을 채운다.)
- 애플리케이션 로직은 커넥션 풀에서 받은 커넥션을 사용해서 SQL을 데이터베이스에 전달하고 그 결과를 받아서 처리한다.
- 이후 커넥션을 사용하고나면, 커넥션은 종료되는 것이 아니라 살아있는 상태로 커넥션 풀에 반환된다.
커넥션 풀이 커지면 클라이언트 요청의 대기 시간이 감소할 수 있지만, 메모리 소모가 커지기 때문에 서비스의 특징, 서버,DB 스펙 등에 따른 성능 테스트를 통해서 적절한 커넥션 풀 숫자를 정해야한다.
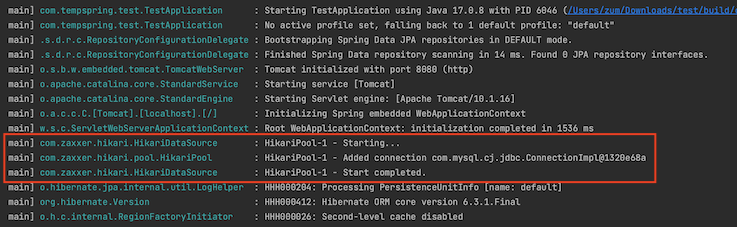
Spring Boot Start (Default)
- SpringBoot를 시작하면 보이는 화면이다. 다음과 같이 기본적으로
HikariCP의 커넥션 풀(HikariPool)이 시작되었음을 나타내고, MySQL DB에 대한 JDBC 커넥션 객체를 성공적으로 추가했음을 알리고 있다.- 기본적으로 Spring 은
application.yml에 아무런 설정도 하지 않았을 경우 쓰레드 풀의 쓰레드 default 개수는 200, DBCP(hikari CP사용)의 default 개수는 10개이다.
DataSource (DB 연결)
Spring은 일반적으로 java.sql.DataSource 를 사용하여 데이터베이스와의 연결을 관리한다.
DataSource 는 커넥션을 획득하는 방법을 추상화한 인터페이스로,
이제 애플리케이션(Spring)은 해당 인터페이스에만 의존하여 애플리케이션 로직을 작성하면 된다.
(DataSource가 추상화되었기 때문에 커넥션 풀 구현 기술을 유연하게 변경해도 애플리케이션 로직은 변경되지 않는다.)
설정 방법
Spring 에서는 주로 application.properties 또는 application.yml 파일에 데이터베이스 연결 정보를 설정한다.
# MySQL 데이터베이스 연결 설정
spring.datasource.url=jdbc:mysql://localhost:3306/{DB명}
spring.datasource.username=root
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver🫛 Bean 자동 등록
또한 스프링 부트는 여기서 직접 DataSource를 스프링 빈으로 등록해야하는 번거로움을 해결해준다.
스프링 부트는application.yml에 있는 속성을 사용해서 데이터소스(DataSource)를 생성한 후 스프링 빈에 자동으로 등록해준다.
🫛 DataSource Bean 직접 등록
물론 아래와 같이 Config를 통해 직접 빈으로 등록하는 경우도 있다.
예를 들면 Database Replication에 따라서 Master, Slave에 각각 접근하고자 하는 경우, 아래와 같이 직접 DataSource를 빈으로 등록할 수 있다. (실무에서 경험했던 예시이다.)@Configuration public class DataSourceConfig { @Bean public DataSource readDatasource() { return new LazyConnectionDataSourceProxy(...); } @Bean public DataSource writeDatasource() { return new LazyConnectionDataSourceProxy(...); } }
이제, 스프링이 제공해주는 트랜잭션을 살펴보기전에 JDBC, JPA등 각각의 데이터 접근 기술들을 통한 트랜잭션 처리 방법을 알아보자.
(1) JDBC 트랜잭션
JDBC에서는 Connection 객체를 생성하고 setAutoCommit(false)를 통해 트랜잭션을 시작한다. (트랜잭션을 사용하는 동안 같은 커넥션을 유지해야하기 때문에 커넥션을 연결하여 같은 세션을 사용을 유지하는 것이다.)
이후 비즈니스 로직이 끝나면 직접 커밋, 혹은 실패시 롤백하여 트랜잭션을 관리한다.
public void pay(int money) throw SQLException {
Connection con = dataSource.getConnection(); // 같은 커넥션(세션) 연결
try {
con.setAutoCommit(false); // 트랜잭션 시작
// ...
// 비즈니스 로직
// ...
con.commit(); // 성공시 커밋
} catch (Exception e) {
con.rollback(); // 실패시 롤백
throw new IllegalStateException(e);
} finally {
release(con); // 커넥션을 풀에 커넥션 반납
}
}(2) JPA 트랜잭션
JPA에서는 개발자가 명시적으로 Connection 객체를 생성하고 관리하는 대신, 추상화된 EntityManagerFactory, EntityManager를 통해 데이터베이스와의 물리적인 연결과 트랜잭션을 관리한다.
위와 동일하게 비즈니스 로직이 끝나면 커밋, 혹은 실패시 롤백하여 트랜잭션을 관리한다.
public void pay(int money) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("emf"); //엔티티 매니저 팩토리 생성
EntityManager em = emf.createEntityManager(); //엔티티 매니저 생성
EntityTransaction tx = em.getTransaction(); //트랜잭션 기능 획득
try {
tx.begin(); //트랜잭션 시작
// ...
// 비즈니스 로직
// ...
tx.commit();//트랜잭션 커밋
}catch (Exception e) {
tx.rollback(); //트랜잭션 롤백
} finally {
em.close(); // 엔티티 매니저 종료
}
emf.close(); //엔티티 매니저 팩토리 종료
}Spring 트랜잭션
개념 / 트랜잭션 매니저
위와 같은 경우 우리는 직접 코드를 작성하고, 만약 트랜잭션 처리 방법을 변경하고자 할 때 코드들을 모두 함께 변경해야한다는 문제점이 있다.
스프링은 트랜잭션 매니저(TransactionManager)라는 트랜잭션 추상화 기술을 제공하여 위와 같은 특정 트랜잭션 기술에 직접 의존하지 않고 유연하게 구현체를 변경할 수 있도록 도와준다.
트랜잭션 매니저 (interface)
- 트랜잭션 매니저 인터페이스는 아래 사진과 같이 트랜잭션의 시작, 커밋, 롤백과 관련된 메서드를 정의하고 있다.
- 트랜잭션 매니저는 트랜잭션을 시작할 때 쓰레드 로컬을 사용하여 각 쓰레드 간 독립적인 커넥션을 사용할 수 있도록 한다. (커넥션 동기화)
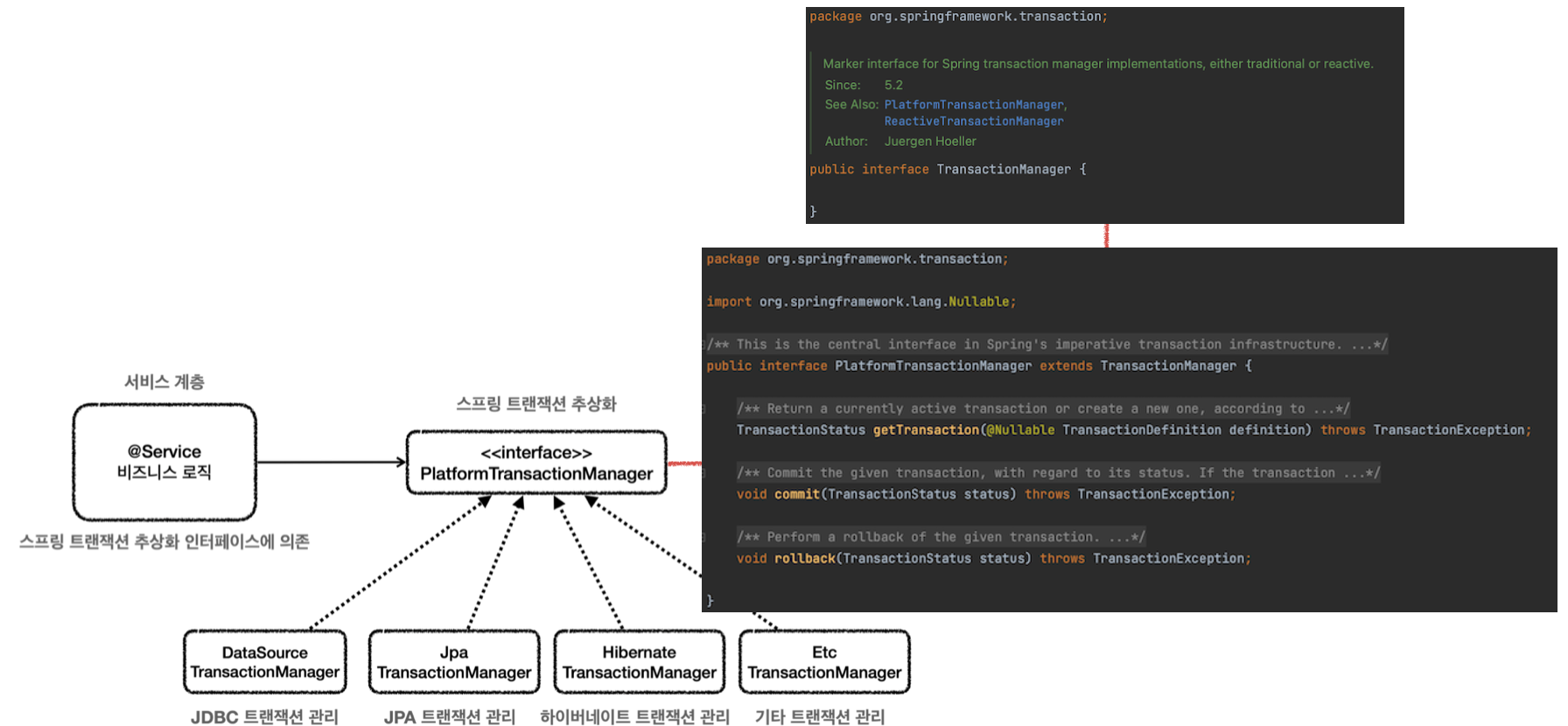
private final PlatformTransactionManager tm; //추상화된 트랜잭션 매니저 (이제 구현체 자유롭게 DI 가능)
public void pay(int money) throws SQLException {
TransactionStatus status = tm.getTransaction(new DefaultTransactionDefinition()); //트랜잭션 시작, 상태정보 반환
try {
// ...
// 비즈니스 로직
// ...
tm.commit(status); //성공시 커밋
} catch (Exception e) {
tm.rollback(status); //실패시 롤백
throw new IllegalStateException(e);
}
}🫛 Bean 자동 등록
또한 스프링 부트는 여기서 직접 트랜잭션 매니저를 스프링 빈으로 등록해야하는 번거로움을 해결해준다.
스프링 부트는 등록된 라이브러리를 보고 적절한 트랜잭션 매니저(ex.DataSourceTransactionManager,JpaTransactionManager…)를 판단한 후, TransactionManager 라는 스프링 빈으로 자동으로 등록한다.
🫛 TransactionManager Bean 직접 등록
위의 DataSource와 같이 TransactionManger도 해당 Config를 통해 직접 빈으로 등록할 수 있다.
@Configuration public class DataSourceConfig { @Bean public DataSourceTransactionManager writeTransactionManager() { return new DataSourceTransactionManager(writeDatasource()); } }
구현체
DataSourceTransactionManager
JpaTransactionManager
사용 방법
위의 트랜잭션 매니저(PlatformTransactionManager)를 사용하는 방법은 크게 2가지가 있다.
위의 코드처럼 직접 작성해줘도 되지만 해당 부분은 매번 코드 중복이 발생하는 등의 불편함이 존재하기 때문에 아래와 같이 사용한다.
1. TransactionTemplate
TransactionTemplate은 직접 구현을 통하는 프로그래밍 방식의 트랜잭션 관리이다.
PlatformTransactionManager 을 직접 선언하여 트랜잭션 코드를 작성할때 반복되는 트랜잭션 시작, 커밋, 롤백 같은 로직들을 템플릿 콜백 패턴을 통하여 정리한 방식이다.
DBMS 종류에 따라 DB Lock 지속 시간이나 Read Consistency의 차이, 그리고 이로 인한 서비스 동시성 문제 등을 생각하면 메소드 단위로 경계가 설정되는 AOP 방식의 트랜잭션이 비효율적일 수 있다. 이렇게 개발자가 직접 트랜잭션의 경계를 설정할 필요한 경우 TransactionTemplate을 구현하기도 한다.
private final TransactionTemplate txTemplate;
public void pay(int money) throws SQLException {
txTemplate.executeWithoutResult((status) -> {
try {
// ...
// 비즈니스 로직
// ...
} catch (SQLException e) {
throw new IllegalStateException(e);
}
});
}2. @Transactional
@Transactional 은 어노테이션만 선언하면 되는, 선언적 트랜잭션 관리 방법이다.
우리가 대표적으로 사용하는 방법으로, 프록시 방식의 AOP가 적용되어있다.
적용 방법은 이제 위와 같이 트랜잭션을 처리하기 위해 직접 서비스 로직에서 트랜잭션을 구현할 필요가 없다. @Transactional 을 메서드나 클래스에 붙이기만 하면 된다.
@Transactional
public void pay(int money) {
// ...
// 비즈니스 로직
// ...
}내부 동작 원리
기본적인 내부 동작 원리는 다음과 같다.
@Transactional이 붙은 객체(매서드, 클래스)는 트랜잭션 AOP 적용 대상이 되고, 실제 객체 대신에 트랜잭션을 처리해주는 프록시 객체가 스프링 빈에 등록된다.@Transactional이 붙은 메서드가 호출되면, 프록시는 트랜잭션을 시작한다.- 프록시가 참조한 실제 객체의 비즈니스 로직을 호출하여 실행한다.
- 메소드 실행이 완료되면 트랜잭션을 커밋하거나 롤백한다.
- 이후 트랜잭션은 종료되어 연결 해제(반납) 되거나, 예외처리를 진행한다.
더 자세한 내부 동작 원리는 이전에 작성했던 Spring AOP 포스팅을 참고하면 된다.
코드와 옵션
@Transactional 내부 코드는 다음과 같다.
이를 참고하여 직접 트랜잭션 매니저, 트랜잭션 전파, 트랜잭션 격리 수준, 트랜잭션 타임아웃 등을 정할 수 있다. (자세한 옵션 내용들은 공식 문서를 참고 바랍니다.)
우선 순위 트랜잭션
@Transactional은 적용 위치에 따라 우선순위가 다르다.
- 스프링에서는 항상 더 구체적이고 자세한 것(= 구현체)이 더 높은 우선순위를 가진다.
(ex. 클래스에 적용된 트랜잭션 옵션과 메서드에 적용된 옵션이 다를 때, 메서드 것을 따른다.) - 때문에, 최하위 우선순위가 되는 인터페이스의 경우 트랜잭션 어노테이션 사용을 권장하지 않는다.
Exception & Rollback 기준
- 언체크 예외(
RuntimeException,Error) 와 그 하위 예외가 발생하면 트랜잭션을 롤백한다. - 체크 예외(
Exception) 와 그 하위 예외가 발생하면 트랜잭션을 커밋한다.
트랜잭션 전파
그럼 이제 트랜잭션이 둘 이상 있을 때는 어떻게 트랜잭션이 이루어질까?
만약 아래와 같이 주문 서비스는 결제와 배달이 함께 이루어진 서비스라고 보자.
Order, Pay, Delivery Service 모두 @Transacional 이 걸려있다.
그럼 이때 Delivery 에서 Exception이 발생하면 Order, Pay 는 각각 어떻게 될까?
이렇게 트랜잭션이 둘 이상 있을 때, 트랜잭션을 각각 별도로 사용할지 아니면 기존 트랜잭션을 그대로 이어받아서 수행할지 결정하는 것을 트랜잭션 전파(propagation)이라고 한다.
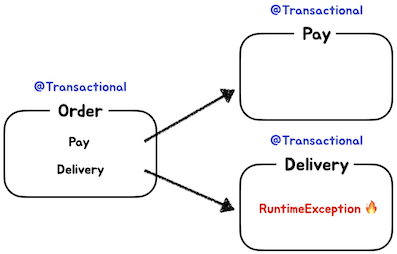
스프링은 이 경우 외부 트랜잭션(Order)과 내부 트랜잭션(Pay, Delivery)를 묶어서 하나의 물리 트랜잭션으로 만든다.
- 외부 트랜잭션 : 처음 시작된 트랜잭션. 가장 밖, 최상위의 트랜잭션 (논리 트랜잭션)
- 내부 트랜잭션 : 외부 트랜잭션이 수행되는 도중에 호출된 트랜잭션 (논리 트랜잭션)
- 논리 트랜잭션 : 트랜잭션 매니저를 통해 트랜잭션을 사용하는 단위
- 물리 트랜잭션 : 논리 트랜잭션들을 하나로 묶은 트랜잭션. 실제 커넥션을 통해 DB에 적용되는 트랜잭션
여기서 논리 트랜잭션 & 물리 트랜잭션의 원칙은 다음과 같다.
- 모든 논리 트랜잭션이 커밋되어야 물리 트랜잭션이 커밋된다.
- 논리 트랜잭션은 트랜잭션 매니저로 커밋하고, 물리 트랜잭션은 실제 커넥션으로 커밋한다.
- 하나의 논리 트랜잭션이라도 롤백되면 (예외를 잡건 아니건) 물리 트랜잭션은 롤백된다.
( 트랜잭션 동기화 매니저에 표시된rollbackOnly=true라는 롤백 전용 마크 체크 후 롤백된다. )
결과적으로 위의 서비스의 경우 다음과 같다.
- Pay, Delivery 서비스들은 Order 서비스가 외부 트랜잭션을 시작하였기 때문에 신규 트랜잭션을 시작하지 않고 외부 트랜잭션을 그대로 이어서 참여한다.
- 따라서 만약 Delivery 서비스에서 예외가 터졌다면 롤백될 것이고, 상위 Order 서비스에서도 Exception을 잡는 것과 상관없이 롤백된다.
전파 옵션
@Trasactional (propagation = {옵션}) 에 따라서 해당 외부,내부 트랜잭션의 의존성등을 설정할 수 있다.
(단, isolation , timeout , readOnly 는 트랜잭션이 처음 시작될 때만 적용된다. )
REQUIRED: 기존 트랜잭션이 없으면 생성하고 있으면 참여한다. ( 기본 설정 ⭐️ )REQUIRES_NEW: 기존 트랜잭션과 상관없이 항상 새로운 트랜잭션을 생성한다.SUPPORT: 기존 트랜잭션이 있으면 참여하고 없으면 트랜잭션 없이 진행한다.NOT_SUPPORT: 기존 트랜잭션 존재 여부와 상관없이 트랜잭션을 참여하지 않는다.MANDATORY: 기존 트랜잭션에 참여하고 없다면 Exception 발생한다.NEVER: 트랜잭션이 없어야하므로 기존 트랜잭션이 있다면 Exception 발생한다.NESTED: 기존 트랜잭션이 없으면 생성하고 있으면 참여한다. 단, 내부 트랜잭션의 롤백이 외부 트랜잭션에 영향을 주지 않는다. ( JPA는 사용불가 )
주의할 점
-
insert 작업 (
Auto Increment)
트랜잭션이 걸린 상태에서 insert 작업시 id(식별자) 가 자동으로 증가하도록 Auto Increment 옵션을 적용하는 경우, 트랜잭션이 롤백되더라도 증가한 id는 다시 원상 복구 되지 않는다. Auto Increment 옵션은 동시성 문제를 고려하여 트랜잭션의 범위 밖에서 동작하기 때문이다. -
@@Transactional의 경우, Proxy 포스팅에서 정리했듯이, self-invocation 로 인하여 트랜잭션(부가로직)이 반영되지 않을 수 있다.
-
@Transactional의 경우, private에는 @Transactional이 걸리지 않는다.
요약/정리
Spring Transaction 설명
스프링은 트랜잭션을 관리하기 위해 트랜잭션 매니저라 불리는 추상화 인터페이스를 제공합니다.
이 추상화된 트랜잭션 매니저를 통해 우리는 트랜잭션 기술의 구현체를 유연하게 변경할 수 있습니다.
이러한 트랜잭션 매니저를 구현하는 두 가지 주요 방법으로는 '트랜잭션 템플릿'과 AOP 기반의 '@Transactional' 어노테이션을 이용한 방법이 있습니다.
@Transactional 동작 원리 설명
스프링의 @Transactional은 AOP 기반으로 트랜잭션을 적용할 수 있게 도와줍니다.
@Transactional을 메소드 또는 클래스에 붙이면, AOP를 통해 타겟 객체 대신 프록시 객체가 스프링 빈으로 등록된다. 이후 프록시 객체의 메소드를 호출하면 타겟 메소드 전 후로 트랜잭션 처리를 수행한다.
더 자세히 살펴보자면, @Transactional은 내부적으로 커넥션을 가져와서 자동 커밋 모드를 비활성화하고 트랜잭션을 시작한다. (자동 커밋을 비활성화하는 이유는 기본적으로 데이터베이스는 자동 커밋(auto commit)을 사용하는데 하나의 작업이 여러 개의 쿼리로 구성되는 경우에는 중간에 하나가 실패되더라도 나머지는 커밋되기 때문에 자동 커밋 모드를 사용하면 안되는 것이다.) 여기서 트랜잭션 매니저는 해당 커넥션을 쓰레드 로컬을 통해 각 쓰레드 간 독립적인 커넥션을 공유(동기화)할 수 있도록 한다.
[참고][인프런 - 스프링 DB 1,2편](https://www.inflearn.com/course/%EC%8A%A4%ED%94%84%EB%A7%81-db-1/dashboard)
https://tecoble.techcourse.co.kr/post/2021-05-25-transactional/
https://mangkyu.tistory.com/312
https://steady-coding.tistory.com/610
