📝 DB에 관해 공부한 것을 정리해보고자 합니다 (업데이트 상시 예정)
데이터베이스
-
DBMS (DataBase Management System)
사용자와 데이터베이스 사이에서 사용자의 요구에 따라 정보를 생성해 주고 데이터베이스를 관리해 주는 소프트웨어이다.
ex) MySQL, Oracle 등 -
SQL (Strucured Query Language)
관계형 데이터베이스 관리 시스템의 데이터를 관리하기 위한 프로그래밍 언어이다.

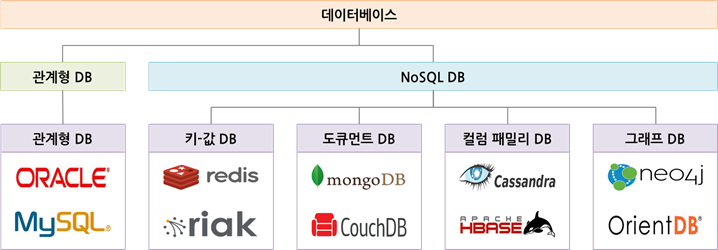
RDBMS
RDBMS(Relational+DMBS)는 말 그대로 관계형 데이터베이스 관리 시스템이다.
관계형 데이터 모델을 기초로 두고 모든 데이터를 2차원 테이블 형태로 관리한다.
(*관계형 데이터 모델 : 2차원 구조의 테이블 형태를 통해 자료를 표현하는 데이터 모델)
RDBMS는 테이블간의 관계를 정의하기 때문에 관계에는 3가지 유형이 존재한다.
→ 일대일, 일대다, 다대다
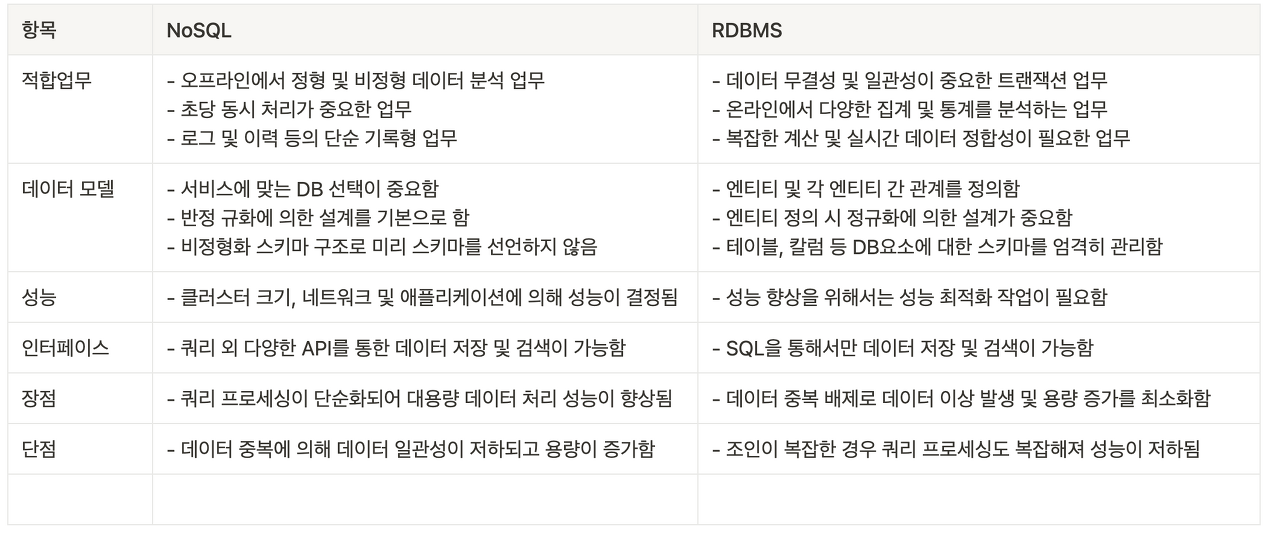
때문에 NoSQL은 데이터 구조가 명확한 정형 데이터를 저장 해야할 때 사용하는 것이 더 적합하다.
-
장점
☑︎ 스키마에 맞춰 데이터를 관리하기 때문에 명확한 데이터 구조와 데이터의 정합성을 보장할 수 있다. -
단점
☑︎ 시스템이 커질 수록 (JOIN문이 많아져) 쿼리가 복잡해질 수 있다.
☑︎ 스키마로 인해 데이터가 유연하지 못하고, 스키마를 변경하게 될 경우 복잡해질 수 있다.
☑︎ 성능 향상을 위해서는 서버의 성능을 향상 시켜야하는 Scale-up만을 지원한다.
NoSQL
NoSQL(Not Only SQL)은 데이터와 트래픽이 나날이 증가하지만 RDBMS는 Scale-Up으로만 성능이 향상 가능하므로,
이를 해결하기 위해 데이터의 일관성은 포기하되 Scale-out을 목표로 등장하였다.
NoSQL의 기술은 RDBMS 스키마에 맞추어 데이터를 관리해야 된다는 한계를 극복 하고, 수평적 확장성(Scale-out)을 쉽게 할 수 있다는 장점을 가지고 있다. 때문에 RDBMS와는 달리 데이터 테이블은 그냥 하나의 테이블로, 테이블 간 관계를 정의하지 않는다. 테이블 간의 관계를 정의하지 않으므로 일반적으로 테이블 간 Join도 불가능하다.
- Key-Value Database
데이터가 Key와 Value의 쌍으로 저장
- Document Database
데이터가 Key와 Document의 형태로 저장. Document라는 구조화된 데이터 타입(JSON, XML 등)이 사용된다.
복잡한 계층 구조를 잘 표현할 수 있고, JSON 기반으로 통신을 하는 HTTP 웹 서버의 경우 편리하게 데이터를 사용할 수 있다.
- Wide Column Database
위의 Key-Value 값을 이용해 필드를 결정하는 것이 아니라, 키에서 필드를 결정하고 저장.
- Graph Database
데이터를 Node와 Edge, Property와 함께 그래프 구조를 사용하여 데이터를 표현하고 저장
데이터 간의 관계가 탐색의 키일 경우에 적합하다. (ex.연관 데이터 추천 엔진, 소셜 네트워크에서 내 친구의 친구를 찾는 질의 등)
때문에 NoSQL은 데이터 구조가 확장 가능성 있는 비정형 데이터를 저장 해야할 때 사용하는 것이 더 적합하다.
-
장점
☑︎ 스키마가 없기 때문에 유연하고 자유로운 데이터 구조를 가질 수 있다. (언제든 저장된 데이터를 조정하고 새로운 필드를 추가할 수 있다.)
☑︎ 데이터 분산이 용이하며 성능 향상을 위한 Saclue-up과 Scale-out이 가능하다. -
단점
☑︎ 데이터 중복이 발생할 수 있으며, 중복된 데이터를 UPDATE 하는 경우 모든 컬렉션에서 수행해야하기 때문에 느리다.
☑︎ 스키마가 존재하지 않기에 명확한 데이터 구조를 보장하지 않으며 데이터 구조 결정이 어려울 수 있다.
SQL
JOIN
조인이란 2개 이상의 테이블을 결합하는 연산이다.
데이터의 규모가 커서 하나의 테이블로 정보를 수용하기 어려울 때, 테이블을 분할하고 테이블 간의 관계성을 부여한다.
- Inner Join : 2개 이상의 테이블에서 교집합만을 추출
- Left Join : 2개 이상의 테이블에서 FROM문에 해당하는 부분을 추출
- Right Join : 2개 이상의 테이블에서 FROM 문의 테이블과 JOIN하는 테이블에 해당하는 부분을 추출
- Outer Join : 2개 이상의 테이블에서 모든 테이블에 해당하는 부분을 추출
HAVING, WHERE
having 은 그룹을 필터링 하는데 사용되고,
where 은 개별 행을 필터링하는데 사용된다.
Index
Index란 테이블을 처음부터 끝까지 검색하는 방법인 FTS(Full Table Scan)이 아니라, 인덱스를 검색하여 해당 자료의 테이블을 엑세스 하는 방법이다.
DBMS는 index를 항상 최신의 정렬된 상태로 유지해야 원하는 값을 빠르게 탐색할 수 있다.
그렇기 때문에 인덱스가 적용된 컬럼에 INSERT, UPDATE, DELETE가 수행된다면 각각 다음과 같은 연산을 추가적으로 해주어야 하며 그에 따른 오버헤드가 발생한다.
즉, 인덱스는 데이터의 저장 성능 보단 데이터의 검색 속도를 높이는 기능이라 볼 수 있다.
-
인덱스를 사용해야 하는 경우
데이터의 양이 많고 검색이 변경보다 빈번한 경우
인덱스를 걸고자 하는 필드의 값이 다양한 값을 가지는 경우 -
인덱스를 사용할 시 단점
INSERT, DELETE, UPDATE 쿼리문을 실행할 때 별도의 과정이 추가적으로 발생하기 때문에 DB의 변경작업이 잦으면 오버헤드가 발생한다.
RDBMS Index 생성 전략
이상적인 컬럼 구성과 순서 결정을 통해 최소의 인덱스로 모든 액세스 형태를 만족할 수 있도록 해야한다.
엑세스 빈도, 사용 빈도(컬럼에 대한 희소성), 테이블 크기, 엑세스 유형 등을 활용하여 종합적으고 전략적으로 결정한다.
+) 더 자세한 것은 인덱스를 설정하여 조회 성능 개선 포스팅을 참조한다.
RDBMS의 Index 관리(자료구조)
- B+Tree
자식 노드가 2개 이상인 B-Tree를 개선시킨 자료구조이다.
데이터베이스의 인덱스 컬럼은 부등호(<,>)를 이용한 순차 검색 연산이 자주 발생될 수 있는데, BTree 리프노드들을 LinkedList로 연결하여 순차 검색이 용이하다. O(log2N)의 시간복잡도를 갖고 일반적으로 사용된다.
- 해시 테이블
해시 테이블 기반의 DB 인덱스는 <데이터=컬럼의 값,데이터의 위치>를 <Key, Value>로 사용하여 컬럼의 값으로 생성된 해시를 통해 인덱스를 구현한다.
해시가 등호(=) 연산에 특화되어 시간복잡도가 O(1)이라 검색이 매우 빠르지만, 대신 부등호와 같은 연속적인 데이터를 위한 순차 검색이 불가능하기 때문에 사용에 적합하지 않다.
트랜잭션
트랜잭션은 데이터의 정합성을 보장하기 위한 기능이다.
논리적인 작업 셋 자체가 100% 적용되거나(COMMIT) 또는 아무것도 적용되지 않아야 함(ROLLBACK)을 보장해준다.
트랜잭션 제어어 (TCL/Transaction Control Language)
☑︎ 커밋 (Commit) : 트랜잭션의 모든 미결정 데이터를 영구적으로 반영함으로써 트랜잭션을 종료한다.
☑︎ 롤백 (Rollback) : 트랜잭션의 모든 미결정 데이터 변경을 포기함으로써 트랜잭션을 종료한다.
트랜잭션 특징
이러한 트랜잭션은 ACID 라 하는 원자성, 일관성, 격리성, 지속성 4가지 성질을 보장해야한다.
- 원자성 (
Atomicity) : 트랜잭션 내에서 실행한 작업들은 마치 하나의 작업인 것처럼 모두 성공 혹은 모두 실패해야한다.- 일관성 (
Consistency) : 모든 트랜잭션은 일관성있는 데이터베이스 상태를 유지한다.- 격리성 (
Isolation) : 동시에 실행되는 트랜잭션들이 서로에게 영향을 미치지 않도록 격리해야한다.- 지속성 (
Durability) : 트랜잭션을 성공적으로 끝내면 그 결과가 항상 기록되어야한다.
격리 수준
트랜잭션에서는 원자성, 일관성, 지속성을 보장하더라도, 격리성에서 문제가 발생할 수 있다.
트랜잭션간에 격리성을 완벽히 보장하려면 동시에 처리되는 트랜잭션을 거의 순서대로 실행해야 한다. 하지만 이렇게 처리를 하면 처리 성능이 매우 나빠지게 된다.
때문에 격리성은 동시성과 관련된(ex.동시에 같은 데이터를 수정하여 영향) 성능 이슈로 인해 격리 수준을 선택할 수 있다.
트랜잭션의 격리 수준(Isolation level) 이란
동시에 여러 트랜잭션이 처리될 때, 특정 트랜잭션이 다른 트랜잭션에서 변경하거나 조회하는 데이터를 볼 수 있도록 허용할지 말지를 결정하는 것이다. 즉, 여러 트랜잭션끼리 얼마나 고립되어 있어야 하는 지를 나타내는 것으로 총 4가지로 나뉜다.
( MySQL 8.0에서는 기본 스토리지 엔진은 InnoDB이고, InnoDB의 기본 트랜잭션 격리 수준은 Repeatable Read 이다. )
- READ UNCOMMITTED (커밋되지 않은 읽기)
다른 트랜잭션의 변경내용이 COMMIT이나 ROLLBACK과 상관없이 보여진다.
데이터 정합성에 문제가 많아 사용되지 않는다.
- READ COMMITTED (커밋된 읽기)
변경내용이 COMMIT되어야만 다른 트랜잭션에서 조회가 가능하다. (오라클에서 기본적으로 사용)
다른 트랜잭션 진행과정 중에 COMMIT이 발생하면 REPEATABLE-READ를 보장하지 않는 다는 문제가 있다.
- REPEATABLE READ (반복 가능한 읽기) ⇢
MySQL default
트랜잭션이 시작하기 전에 커밋된 내용만 조회할 수 있다. (MySQL에서 기본적으로 사용)
트랜잭션 과정 중에서 일관된 데이터를 보장하지 않아 update 부정합이 발생할 수 있다.
- SERIALIZABLE (직렬화 가능)
트랜잭션이 진행중일 경우 다른 트랜잭션의 접근이 허용되지 않는다.
부정합은 발생하지 않으나 성능이 떨어진다는 단점이 있다.
격리 수준에 따라 발생할 수 있는 문제점
- DIRTY READ
어떠한 트랜잭션에서 처리한 작업이 완료되지 않았음에도 불구하고 다른 트랜잭션에서 볼 수 있게 되는 현상
특정 트랜잭션이 Rollback 했음에도 다른 트랜잭션은 해당 데이터를 그대로 판단하고 처리할 문제가 있다
- NON-REPEATABLE READ
동일한 SELECT 쿼리를 실행했을 때 항상 같은 결과를 보장해야 한다는 'REPEATABLE READ' 정합성에 어긋나는 현상
다른 트랜잭션에서 입금,출금이 계속 진행되고 있을 때 다른 트랜잭션에서 오늘 입금된 금액의 총합 조회시 데이터가 불일치 할 수 있다
- PHANTOM READ
한 트랜잭션내에서 동일한 쿼리를 두 번 수행했는데, 첫 번째 쿼리에서 존재하지 않던 유령(Phantom) 레코드가 두 번째 쿼리에서 나타나는 현상. 트랜잭션 도중 새로운 레코드 삽입을 허용하기 때문에 나타나는 현상
| 격리 수준 | DIRTY READ | NON-REPEATABLE READ | PHANTOM READ |
|---|---|---|---|
| READ UNCOMMITTED | O | O | O |
| READ COMMITTED | O | O | |
| REPEATABLE READ | O | ||
| SERIALIZABLE |
동시성
동시성은 동시에 실행되는 여러 개의 트랜잭션이 작업을 성공적으로 마칠 수 있도록 트랜잭션의 실행 순서를 제어 하는 기법이다.
동시성 제어의 목적은 트랜잭션의 직렬성을 보장하고, 데이터의 무결성 및 일관성 보장한다는 것에 있다.

동시성 제어 기법의 종류
- 락킹 (locking)
트랜잭션이 데이터에 접근하기 전에 Lock을 요청해서 Lock이 허락되면 해당 데이터에 접근할 수 있도록 하는 기법.
트랜잭션이 사용하는 자원에 대하여 상호 배제(Mutual Exclusive) 기능을 제공하는 기법. 다른 트랜잭션은 해당 데이터가 unlock될 때까지 접근/수정/삭제가 불가하다.
- 타임스탬프 (timestamp)
시스템에서 생성하는 고유 번호인 타임스탬프를 트랜잭션에 부여함으로써 트랜잭션 간의 접근 순서를 미리 정한다.
- 적합성 (validation) 검증
먼저 트랜잭션을 수행하고 트랜잭션을 종료할 때 적합성을 검증하여 데이터베이스에 최종 반영한다.
DB Lock(락)
DB 락은 트랙잭션 처리의 순차성을 보장 하기 위한 방법이다.
여러 개의 트랜잭션들이 하나의 데이터로 동시에 접근하려고 할 때 이를 제어해주는 방법이다.
세션이 트랜잭션을 시작하고 데이터를 수정하는 동안 커밋 혹은 롤백이 있기 전까지는
다른 트랜잭션에서는 데이터를 수정할 수 없도록 해당 데이터에 잠금(Lock)을 걸어두는 것이다.
트랜잭션이 시작되며 획득된 Lock은 트랜잭션이 커밋되거나 롤백될 때 해제된다.
Locking 종류
수정의 비율이 높다면 Pessimistic을 사용하고, 읽기의 비중이 높다면 Optimistic을 사용한다.
- 비관적 락 (Pessimistic lock)
데이터 수정 즉시 트랜잭션 충돌을 감지할 수 있다.
- 공유 락 (Shared Lock) : 사용중인 데이터를 같은 다른 트랜잭션이 읽기 허용, 쓰기 비허용
- 베타 락 (Exclusive Lock) : 사용중인 데이터를 다른 트랜잭션이 접근(읽기, 쓰기) 비허용
- 낙관적 락 (Optimistic lock)
Lock이 아닌 Version(버전) 관리 기능을 통해서 트랜잭션 격리성을 관리한다.
DB 가 제공하는 락 기능을 사용하지 않고 JPA 가 제공하는 버전 관리 기능을 사용한다.
Version 컬럼을 별도로 추가해서 충돌 방지하고, 커밋 전까지는 충돌을 알 수 없다.
MVCC(격리 수준 제어) 대신 락을 사용하는 이유
낙관적 락이나 비관적 락은 다른 트랜잭션이 수정하는 것 자체를 막아버린다.
반면에 MVCC는 레코드에 잠금을 걸지 않고 트랜잭션 격리 레벨에 따라 일관된 읽기를 제공한다.
따라서 두 개의 트랜잭션이 동시에 수정할 때 처음의 수정사항만 반영하도록 하여 갱신 분실 문제를 예방 하기 위해서는 락을 사용한다.
MVCC가 일관된 읽기를 사용할 수 있는 이유는 변경되기 이전의 내용을 보관하고 있는 언두 로그 에서 데이터를 가져오기 때문이다.
동시성 제어를 하지 않은 경우 발생하는 문제점
- 갱신 손실 (Lost Update)
두 개이상 트랜잭션이 한 개의 데이터를 동시에 갱신(Update)할 때 발생. 갱신이 무효화
- 현황파악 오류 (Dirty Read)
특정 트랜잭션이 쓰기 작업을 하고 있는데, 다른 트랜잭션이 읽기 작업을 하여 발생하는 문제.
쓰기 작업을 하던 트랜잭션이 Rollback한 경우, 읽기 트랜잭션은 무효가 된 데이터를 읽고 잘못된 결과를 도출할 수 있다.
- 모순성 (Inconsistency)
다른 트랜잭션들이 해당 항목 값을 갱신하는 동안, 한 트랜잭션이 두 개의 항목 값 중 어떤 것은 갱신되기 전의 값을 읽고 다른 것은 갱신된 후의 값을 읽게 되어 데이터의 불일치가 발생하는 상황
- 연쇄복귀 (Cascading Rollback)
한 트랜잭션이 갱신 후 다시 Rollback 하고 있는 중간에, 다른 트랜잭션에서 Rollback 이전에 갱신된 데이터를 읽어서 사용할 때 발생할 수 있는 문제
정규화
하나의 릴레이션에 하나의 의미만 존재하도록 릴레이션을 분해하는 과정이며, 데이터의 일관성, 최소한의 데이터 중복, 최대한의 데이터 유연성을 위한 방법이다.
-
제1정규형
모든 속성 값이 원자 값을 갖도록 분해한다. -
제2정규형
제1정규형을 만족하고, 기본키가 아닌 속성이 기본키에 완전 함수 종속이도록 분해한다.
(여기서 완전 함수 종속이란 기본키의 부분집합이 다른 값을 결정하지 않는 것을 의미한다.) -
제3정규형
제2정규형을 만족하고, 기본키가 아닌 속성이 기본키에 직접 종속(비이행적 종속)하도록 분해한다.
(여기서 이행적 종속이란 A->B->C가 성립하는 것으로, 이를 A,B와 B,C로 분해하는 것이 제3정규형이다.) -
BCNF 정규형
제3정규형을 만족하고, 함수 종속성 X->Y가 성립할 때 모든 결정자 X가 후보키가 되도록 분해한다.
이상현상
이상 현상은 테이블을 설계할 때 잘못 설계하여 데이터를 삽입,삭제,수정할 때 생기는 논리적 오류이다.
이러한 이상 현상을 예방하고 효과적인 연산을 하기 위해 데이터 정규화를 진행한다.
- 삽입 이상 : 자료를 삽입할 때 특정 속성에 해당하는 값이 없어 NULL을 입력해야 하는 현상
- 갱신 이상 : 중복된 데이터 중 일부만 수정되어 데이터 모순이 일어나는 현상
- 삭제 이상 : 어떤 정보를 삭제하면, 의도하지 않은 다른 정보까지 삭제되어버리는 현상
클러스터링
리플리케이션
샤딩
DB tuning
DB 튜닝이란 DB의 구조나, DB 자체, 운영체제 등을 조정하여 DB 시스템의 전체적인 성능을 개선하는 작업이다.
튜닝은 'DB 설계 튜닝 → DBMS 튜닝 → SQL 튜닝' 3단계로 진행할 수 있다.
-
설계 튜닝 (
모델링 관점)
◦ 설계 단계에서 성능을 고려하여 설계
◦ 데이터 모델링, 인덱스 설계
◦ 데이터베이스 용량 산정
◦ ex) 반정규화, 분산파일배치 -
DBMS 튜닝 (
환경 관점)
◦ 성능을 고려하여 CPU, 메모리 I/O에 관한 지정
◦ ex) Buffer 크기, Cache 크기 -
SQL 튜닝 (
App 관점)
◦ SQL 작성 시 성능 고려
◦ Join, Indexing, SQL Execution Plan
◦ ex) Hash / Join
ORM
ORM(Object-Relational Mapping)은 객체와 관계형 데이터베이스의 테이블을 매핑(연결)한다는 것을 의미한다.
ORM을 이용하면 SQL 쿼리가 아닌 코드를 통해 데이터를 조작할 수 있다.
JPA는 자바의 ORM 기술 표준으로 관계형 데이터베이스를 사용하는 방식을 정의한 인터페이스이다.
만약 ORM을 사용한다면 Member 테이블과 매핑된 객체를 member 이라고 할 때,
SELECT * FROM Memver 대신 member.findAll() 의 메소드 호출로 데이터 조회가 가능하다.
ORM을 사용하면, 객체지향적인 코드로 인해 더 직관적이고 로직에 집중할 수 있도록 해주고, 객체의 재사용 및 유지보수의 편리성이 증가한다.
🖍 면접 질문
RDMS, NoSQL 의 차이에 대하여 설명해주세요
RDMS는 관계형 데이터 모델을 기초로 두고 모든 데이터를 2차원 테이블 형태로 관리합니다.
때문에 데이터의 정합성을 보장할 수 있지습니다. 하지만 시스템이 커질 수록 쿼리가 복잡해질 수 있고 성능 향상을 위해서는 Scale-up만을 지원합니다.
NoSQL은 RDBMS RDBMS는 Scale-Up으로만 성능이 향상 가능하므로 이를 해결하기 위해 Scale-out을 목표로 등장하였습니다.
테이블 간 관계를 정의하지 않아 스키마에 맞춰 데이터를 관리하지 않으므로, 수평적 확장을 쉽게 할 수 있다는 장점을 지니고 있습니다. 다만 스키마가 존재하지 않기에 명확한 데이터 구조를 보장하지 않으며 데이터 구조를 결정하기 어려울 수 있고, 데이터 중복이 발생할 수 있습니다.
RDBMS, NoSQL이 더 적합한 상황에 대하여 설명해주세요.
RDBMS는 데이터 구조가 명확하며 변경 될 여지가 없으며 명확한 스키마가 중요한 경우. 또는 중복된 데이터가 없어 변경이 용이하기 때문에 관계를 맺고 있는 데이터가 자주 변경이 이뤄지는 시스템에 적합합니다.
NoSQL은 정확한 데이터 구조를 알 수 없고 데이터가 변경/확장이 될 수 있는 경우에 사용하는 것이 적합합니다. 하지만 데이터 중복이 발생할 수 있으며 중복된 데이터가 변경될 시에는 모든 컬렉션에서 수정을 해야 하기 때문에 Update가 많이 이뤄지지 않는 시스템일때 좋습니다. 혹은 막대한 데이터 양을 저장해야하는 등 Scale-Out을 해야 되는 시스템에서 적합합니다.
Index 에 대해서 설명해주세요
인덱스는 full table scan 대신에 인덱스를 검색하여 테이블의 검색 속도를 향상시키는 방법입니다.
인덱스는 항상 정렬된 상태를 유지하기 때문에 조회에서는 빠르지만, 새로운 값을 추가 삭제 수정하는 경우는 속도가 느려질 수 있습니다.
때문에 데이터가 많고 수정보다 조회가 더 빈번할 때 사용하면 좋습니다.
RDBMS에서 Index 관리를 위한 자료구조에 대해 알고있나요?
RDBMS의 Index 관리는 B+Tree, 해시 테이블 자료구조를 통해 이루어집니다.
B+Tree는 자식 노드가 2개 이상인 B-Tree를 개선시킨 자료구조로, LinkedList로 연결되어 순차 검색에 용이하여 일반적으로 사용됩니다.
해시 테이블은 컬럼의 값으로 생성된 해시를 통해 인덱스를 구현합니다. 다만, 대신 부등호와 같은 연속적인 데이터를 위한 순차 검색이 어려워 사용에 적합하지 않습니다.
Index 설계를 통해 조회 성능을 개선한 경험이 있나요? (프로젝트 정리) ↩️
...
인덱스 컬럼 생성시 고려해야할 점은 어떤 점이 있나요?
넓은 범위를 인덱스로 처리시 오버헤드가 발생하고, 테이블 건수가 적으면 인덱스 생성보다 풀 스캔이 더 빠릅니다.
자주 조합되어 사용되는 경우는 결합인덱스로 생성하고, 분포도가 좋은 컬럼은 단독적으로 생성하여 활용도를 향상시키는 점 등을 고려할 수 있습니다.
트랜잭션에 대해서 설명해주세요
트랜잭션은 데이터의 정합성을 보장하기 위한 기능입니다.
하나의 트랜잭션은 Commit 되거나, Rollback 되며, 작업들이 모두 처리되지 못할 경우에는 변경을 포기함으로써 일부만 변경되는 것을 방지합니다.
(+ 트랜잭션의 특징은 원자성, 일관성, 격리성, 지속성이 있습니다.)
트랜잭션의 격리 수준과 각 수준에서 발생할 수 있는 문제들에 대해 설명해주세요
트랜잭션의 격리 수준이란 여러 트랜잭션끼리 얼마나 고립되어 있어야 하는 지를 나타내는 것으로, 총 4가지로 나뉩니다.
READ UNCOMMITTED 는 트랜잭션내에서 커밋하지 않은 데이터에 다른 트랜잭션의 접근이 가능합니다.
READ COMMITTED 는 트랜잭션내에서 커밋된 데이터만 다른 트랜잭션이 읽는 것을 허용합니다.
REPEATABLE READ 는 트랜잭션 내에서 한 번 조회한 데이터를 반복해서 조회해도 결과는 동일
SERIALIZABLE 는 한 트랜잭션이 진행중일 경우 다른 트랜잭션의 접근이 어려운 가장 엄격한 격리 수준입니다.
격리 수준에 따라 발생할 수 있는 문제점에는 무엇이 있나요?
DIRTY READ, NON-REPEATABLE READ, PHANTOM READ 와 같은 문제점이 발생할 수 있습니다.
DIRTY READ의 경우, 어떠한 트랜잭션에서 처리한 작업이 완료되지 않았음에도 불구하고 다른 트랜잭션에서 볼 수 있게 되는 현상입니다.
NON-REPEATABLE READ의 경우, 동일한 SELECT 쿼리를 실행했을 때 데이터 정합성에 어긋나는 현상입니다.
PHANTOM READ의 경우, 다른 트랜잭션에서 수행한 변경 작업에 의해 레코드가 보였다가 안보였다가 하는 현상입니다.
동시성 제어 기법에 관하여 설명해주세요
동시성 제어는 동시에 실행되는 트랜잭션에 대해 작업을 성공적으로 마칠 수 있도록 제어하는 기법입니다.
트랜잭션의 직렬성을 보장하고, 데이터의 무결성 및 일관성을 보장하는 것을 목표로 합니다.
동시성 제어 기법은 락킹, 타임스탬프, 적합성이 존재하고
락킹에서는 비관적 락과 낙관적 락이 존재하는데 낙관적 락의 경우 DB가 제공하는 락 기능이 아닌 JPA가 제공하는 버전 관리 기능을 사용합니다.
DB 락에 대해서 설명해주세요.
DB 락은 트랙잭션 처리의 순차성을 보장 하기 위한 방법입니다.
공유락은 트랙잭션이 읽기를 할 때 사용하는 락이고,
베타락은 트랜잭션이 읽고 쓰기를 할 때 사용하는 락입니다.
MVCC(격리 수준 제어) 대신 락을 사용하는 이유는 무엇인가요?
낙관적 락이나 비관적 락은 다른 트랜잭션이 수정하는 것 자체를 막아버립니다.
반면에 MVCC는 레코드에 잠금을 걸지 않고 트랜잭션 격리 레벨에 따라 일관된 읽기를 제공합니다.
따라서 두 개의 트랜잭션이 동시에 수정할 때 처음의 수정사항만 반영하도록 하여 갱신 분실 문제를 예방 하기 위해서는 락을 사용합니다.
행의 개수가 많은 테이블은 어떻게 설계하면 좋을까요 ↩️
파티셔닝 또는 샤딩으로 테이블을 분리하거나 레플리카를 사용해 write, read 트래픽을 분산시킬 수 있습니다.
...
[참조]
https://dev-coco.tistory.com/158?category=1056309
https://khj93.tistory.com/entry/Database-RDBMS%EC%99%80-NOSQL-%EC%B0%A8%EC%9D%B4%EC%A0%90
https://sujl95.tistory.com/83 /RDMBS, NoSQL
https://zzang9ha.tistory.com/381#2-5-%EC%A0%95%EB%A6%AC /격리 수준
https://jokerkwu.tistory.com/125 / 동시성
https://backtony.github.io/interview/2021-12-08-interview-18/#%EB%8F%99%EC%8B%9C%EC%84%B1-%EC%A0%9C%EC%96%B4
