
BFS - 너비우선탐색
특정 노드로부터 인접한 모든 노드를 순회하는 순서로 그래프를 탐색하는 방법
BFS는 너비 우선 탐색으로 큐를 이용하여 구현된다
(DFS와 다르게 재귀로는 구현되지 않는다)
순서의 예시는 아래와 같다
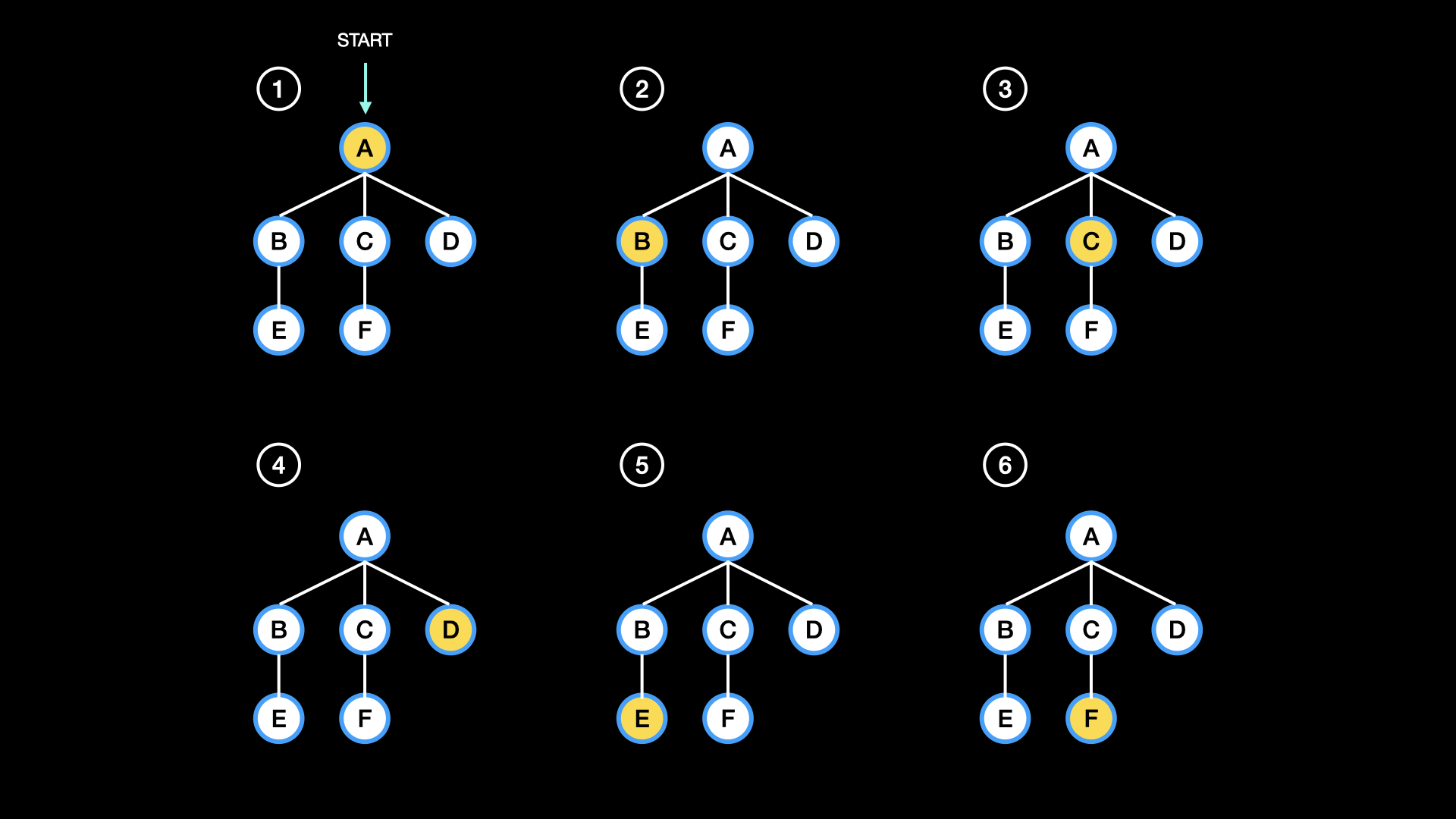
구현
1. 그래프의 구현
let graph: [String:[String]] = [
"A" : ["B", "C", "D"],
"B" : ["A", "E"],
"C" : ["A", "F"],
"D" : ["A"],
"E" : ["B"],
"F" : ["C"],
]2. DFS 함수 구현
기본적인 구조는 다음과 같다
- 탐색 시작 노드를 queue에 넣고 방문처리를 한다
- 스택의 fron에 존재하는 노드는 모든 인접한 노드의 방문을 끝내지 않은 노드를 의미한다
그러므로 노드를 queue에 넣고 방문처리 한다- 만약 해당 노드에 대해 모든 인접한 노드를 방문한 경우 에서 최상단 노드를 꺼낸다
아래 코드의 경우에는 이미 방문한 스택을 확인하는데 있어 배열을 사용하면 최악의 경우 O(N)의 시간복잡도를 가지기 때문에 별도의 Set를 이용해 탐색 시간을 줄이는 방법을 채택한다
func bfs(_ graph: [String: [String]], _ start: String) -> [String] {
// 방문한 지점을 탐색하기 위해 사용될 Set -> contains를 통해 특정 요소를 탐색하는데 O(1)의 시간복잡도 때문
// 배열은 탐색에서 최악의 경우 O(N)
var visitedRecord: Set<String> = []
// 방문이 필요한 요소들을 저장하기위한 큐
var needVisitQueue: [String] = [start]
// 탐색한 노드를 순서대로 기록하기 위한 배열(큐)
var result: [String] = []
while !queue.isEmpty {
// 큐에서 가장 앞에 위치한 노드를 꺼낸다
let node = queue.removeFirst()
// 이미 방문한 노드가 아니라면 아래 문장을 실행
if !visitedRecord.contains(node) {
//Set에 방문 지점을 저장
visitedRecord.insert(node)
탐색한 노드를 순서대로 저장하는 result 배열(큐)에 방문 노드를 저장
result.append(node)
방문한 노드에서 인접한 모든 노드를 저장. 단, 이미 거친 노드의 경우 저장하지 않는다
queue += graph[node]?.filter { !visitedRecord.contains($0) } ?? []
}
}
return result
}전체 코드
let graph: [String:[String]] = [
"A" : ["B", "C", "D"],
"B" : ["A", "E"],
"C" : ["A", "F"],
"D" : ["A"],
"E" : ["B"],
"F" : ["C"],
]
func bfs(_ graph: [String: [String]], _ start: String) -> [String] {
var visitedRecord: Set<String> = []
var queue: [String] = [start]
var result: [String] = []
while !queue.isEmpty {
let node = queue.removeFirst()
if !visitedRecord.contains(node) {
visitedRecord.insert(node)
result.append(node)
queue += graph[node]?.filter { !visitedRecord.contains($0) } ?? []
}
}
return result
}
print(bfs(graph, "A"))

내 꿈은 고등어