상황
다음 코드와 같이 4개 유형의 크롤링 데이터 파일을 DB에 저장해야하는 상황이다.
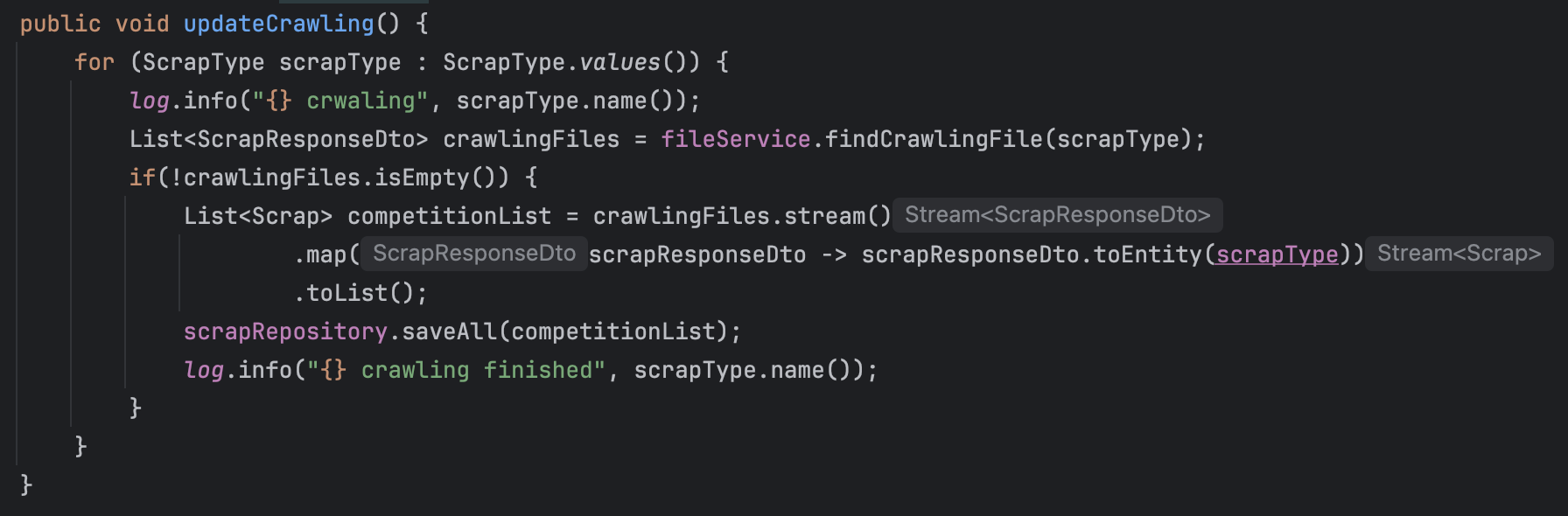
에러 발생
해당 메서드 실행 결과,
2025-06-28T19:20:01.889+09:00 WARN 4864 --- [xpact] [ Thread-0] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 1062, SQLState: 23000
2025-06-28T19:20:01.889+09:00 ERROR 4864 --- [xpact] [ Thread-0] o.h.engine.jdbc.spi.SqlExceptionHelper : Duplicate entry '247375' for key 'scrap.UKs2ptf15nrmc6tnmrvfkbibhay'다음과 같은 에러가 발생했다.
이는 scrap테이블이 유니크 키 제약 조건을 위반했음을 의미한다. 원인은 4개의 유형의 데이터셋에 서로 exclusive하지 않고 겹치는 데이터가 존재했기 때문이다. 이미 존재하는 데이터 247375가 다시 저장되면서 중복 예외가 발생한 것이었다.
해결방안
이에 각 엔티티를 저장하기 전에 DB에 해당 데이터가 존재하는지 확인하는 쿼리를 추가하고자 하였다.
하지만 6천개의 데이터를 일괄 저장하는데 중복되는 값을 찾기 위해 데이터 개수만큼 추가적인 쿼리가 발생하게 되어 좋은 방식이 아니라고 판단했다.
데이터를 저장 시 유니크한 컬럼에 대해 중복된 값을 저장하려고 시도할 때, 자바 레벨에서 예외가 터지는게 아닌 SQL레벨에서 이를 처리하면 정상적으로 해당 로직을 실행할 수 있을 것이라고 생각했다.
구글링을 해본 결과, MySQL에는 INSERT IGNORE라는 기능이 있음을 알 수 있었다. INSERT쿼리에 IGNORE키워드를 추가하면 삽입 시 중복된 키 값으로 인해 발생하는 오류를 무시하고, 중복되지 않는 데이터만 삽입할 수 있다.
지금 상황에 딱 맞는 해결책이다. INSERT IGNORE를 사용하면, 중복된 키로 인한 에러를 무시하고 유효한 데이터만 삽입된다.
하지만 INSERT IGNORE 기능을 JpaRepository에서 찾을 수 없었다. JPQL로 작성하려 했지만, 아래와 같이 JPQL에서 지원하지 않는 문법임을 알 수 있었다.
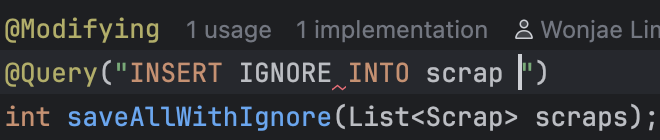
아무래도 RDBMS 공통된 기능이 아니라 MySQL에서만 지원하는 기능이라 구현되어있지 않은듯 했다.
SQL 쿼리를 직접 작성하여 실행하면 IGNORE키워드를 사용할 수 있으므로, Native SQL을 사용하여 작성하였다.
여러 엔티티를 한꺼번에 INSERT하므로 jdbcTemplate의 batchUpdate메서드 사용하였다.
BatchPreparedStatementSetter를 구현하여 파라미터를 매핑하고, INSERT할 크기를 반환하도록 하였다.
작성한 코드는 아래와 같다.
@Transactional
public int saveAllWithIgnore(List<Scrap> scraps) {
String sql = """
INSERT IGNORE
INTO scrap (linkareer_id, scrap_type, title, organizer_name, start_date, end_date, job_category, homepage_url, img_url, benefits, eligibility, on_off_line, enterprise_type, region)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ? ,? ,?)
""";
int[] result = jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
Scrap scrap = scraps.get(i);
ps.setLong(1, scrap.getLinkareerId());
ps.setString(2, scrap.getScrapType().name());
ps.setString(3, scrap.getTitle());
ps.setString(4, scrap.getOrganizerName());
ps.setString(5, scrap.getStartDate());
ps.setString(6, scrap.getEndDate());
ps.setString(7, scrap.getJobCategory());
ps.setString(8, scrap.getHomepageUrl());
ps.setString(9, scrap.getImgUrl());
ps.setString(10, scrap.getBenefits());
ps.setString(11, scrap.getEligibility());
ps.setString(12, scrap.getOnOffLine());
ps.setString(13, scrap.getEnterpriseType());
ps.setString(14, scrap.getRegion());
}
@Override
public int getBatchSize() {
return scraps.size();
}
});
return Arrays.stream(result).sum();
}다음과 같이 SQL레벨에서 IGNORE를 적용하여, 중복된 값이 있어도 무시하고 예외를 던지지 않아 정상적인 흐름을 가져갈 수 있었다.
