그래프를 탐색하는 방법으로, BFS와 DFS가 있다. 각 순회방식마다 장단점이 있으므로 적절한 탐색방법을 사용하면 될 것 같다.
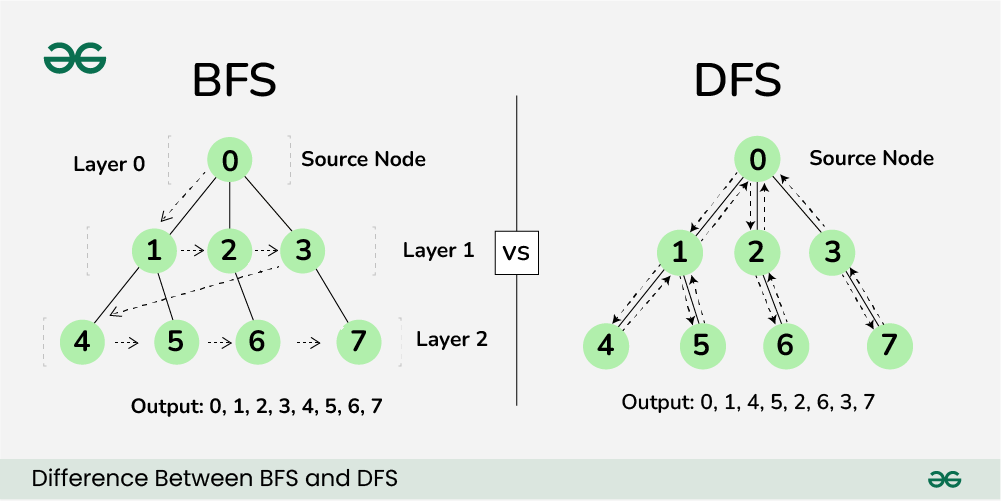
출처 : https://www.geeksforgeeks.org/difference-between-bfs-and-dfs/
BFS (Breadth First Search) 너비 우선 탐색
주어진 정점에서 인접한 정점을 먼저 탐색하는 방식이다. 해당 정점에서 인접한 모든 정점 탐색을 완료했을 때, 먼저 탐색 완료한 순서대로 탐색을 시작한다.
이때 탐색 완료한 정점에 대한 정보를 큐에 삽입하여 알고리즘을 진행한다.
루트 노드 0에서 인접한 노드인 1, 2, 3을 탐색하였을 때, 큐에 순서대로 1, 2, 3이 push된다. 0에 대한 모든 인접 노드를 탐색한 후, 큐에서 pop하여 노드 1에 대한 인접 노드 탐색을 다시 수행한다.
구현 코드(cpp)
#include <iostream>
#include <queue>
#define n 100
using namespace std;
int adj_matrix[n][n] = {0,};
bool visitied[n] = {0,};
queue<int> q;
void BFS(int v){
q.push(v);
visitied[v] = true;
while(!q.empty()){
v = q.front();
q.pop();
cout << v << " ";
//pop하면서 원소 출력
for(int j = 1; j <= n; j++){
if(adj_matrix[v][j] == 1 && visitied[j] == false){ //정점과 연결되어있고 방문X여야함
q.push(j);
visitied[j] = true;
}
}
}
}
int main() {
adj_matrix[1][2] = 1;
adj_matrix[1][3] = 1;
adj_matrix[1][4] = 1;
adj_matrix[2][5] = 1;
adj_matrix[2][6] = 1;
adj_matrix[2][7] = 1;
adj_matrix[2][11] = 1;
adj_matrix[2][12] = 1;
adj_matrix[3][8] = 1;
adj_matrix[3][9] = 1;
adj_matrix[3][10] = 1;
BFS(1);
}다음과 같이 구현할 수 있다.
노드 1의 인접 노드 ⇒ 2, 3, 4
노드 2의 인접 노드 ⇒ 5, 6, 7, 11, 12
노드 3의 인접 노드 ⇒ 8, 9, 10
다음과 같은 그래프에서 BFS를 수행한다고 했을 때, 처음 1을 큐에 push하 해고당 노드를 해당 노드의 visited 여부를 true로 변경한다. 노드 1에서 인접 노드를 순회하며 visit하지 않은 노드를 탐색하였을 때 해당 노드의 visit여부를 true로 변경하고 해당 노드를 큐에 push한다. 노드 1에 대한 순회가 끝나고 나서는 큐의 상태는 2 , 3, 4 일 것이다.
다음 노드는 큐에서 pop()한 노드인 노드 2이다. 해당 노드에서 인접 노드를 순회하면 5, 6, 7, 11, 12이며 이를 순서대로 큐에 push한다. 노드 2에 대한 순회가 끝나면 큐의 상태는 노드 2가 pop되고 노드 2의 인접 노드가 push되었으므로 3, 4, 5, 6, 7, 11, 12일 것이다. 큐의 상태는 노드 1의 인접 노드와 노드 2의 인접 노드가 들어가있다. 하지만 큐의 FIFO의 성질에 의해 두 부분이 섞일 일은 없다.
다음 노드는 노드 1의 인접노드인 3, 4일 것이다. 해당 노드의 인접노드를 찾아 큐에 push하면 큐의 최종 상태는 노드 3, 4가 빠지고 노드 3, 4에 대한 인접 노드를 push하므로 5, 6, 7, 11, 12, 8, 9, 10이 된다. 즉, 노드 1의 인접노드인 2, 3, 4에 대한 인접 노드 순회가 끝나면 큐의 상태는 2, 3, 4가 빠지고 해당 노드에 대한 인접노드가 들어가는 상태가 된다.
이러한 흐름이 큐에 아무것도 없을 때까지 반복하면 BFS가 완료된다. 해당 코드의 탐색 순서 실행 결과는 다음과 같다.
1 2 3 4 5 6 7 11 12 8 9 10성질
너비 우선 탐색(BFS)은 주어진 노드에서 가까운 노드부터 찾기 시작하므로 최단거리를 구할 때 사용된다.
노드 수가 적고 깊이가 얕은 경우 빠르게 동작 가능하다.
DFS (Depth First Search) 깊이 우선 탐색
주어진 정점에서 인접한 정점을 모두 탐색하지 않고 한 방향으로 먼저 탐색하는 방식이다. 한 분기의 탐색을 모두 완료했을 때, 주어진 정점의 다른 인접 노드로 탐색을 시작한다.
DFS를 구현하는 방법에는 두 가지가 존재한다.
- 스택
- 재귀함수
재귀함수를 사용하면 더 간결한 코드로 구현 가능하다.
구현 코드 - 재귀 (cpp)
#include <iostream>
#include <queue>
#define n 100
using namespace std;
int adj_matrix[n][n] = {0,};
bool visitied[n] = {0,};
void DFS(int v){
visitied[v] = true;
cout << v << ' ';
for(int i = 1; i <= n; i++){
if(adj_matrix[v][i] == 1 && visitied[i] == false){ //정점과 연결되어있고 방문X
DFS(i);
}
}
}
int main() {
adj_matrix[1][2] = 1;
adj_matrix[1][3] = 1;
adj_matrix[1][4] = 1;
adj_matrix[2][5] = 1;
adj_matrix[2][6] = 1;
adj_matrix[2][7] = 1;
adj_matrix[2][11] = 1;
adj_matrix[2][12] = 1;
adj_matrix[3][8] = 1;
adj_matrix[3][9] = 1;
adj_matrix[3][10] = 1;
DFS(1);
}노드 1의 인접 노드 ⇒ 2, 3, 4
노드 2의 인접 노드 ⇒ 5, 6, 7, 11, 12
노드 3의 인접 노드 ⇒ 8, 9, 10
다음과 같은 그래프에서 DFS를 수행하면 다음과 같다.
노드 1에서 가장 처음의 인접 노드 2를 방문한다. 이때 visit여부를 true로 변경하여 중복으로 방문하는 일이 없도록 한다. 인접 노드 2에 대한 DFS 재귀를 시작한다.
노드 2에서 가장 처음의 인접 노드 5를 방문한다. 이때 visite여부를 true로 변경 후, 인접 노드 5에 대해 DFS 재귀를 다시 시작한다.
노드 5에 대해서는 인접 노드가 존재하지 않기 때문에 return한다.
return 후 노드 2에 대한 두 번째 인접 노드 6를 방문한다. 해당 노드에 대해서도 DFS 재귀를 한다.
해당 재귀를 계속 반복하면 인접 노드에 대한 탐색이 우선이 아니라 분기에 대해 우선되는 탐색임을 확인할 수 있다.
해당 코드의 탐색 순서 출력 결과는 아래와 같다
1 2 5 6 7 11 12 3 8 9 10 4구현 코드 - 스택 (cpp)
#include <iostream>
#include <stack>
#define n 100
using namespace std;
int adj_matrix[n][n] = {0,};
bool visitied[n] = {0,};
stack<int> s;
void DFS(int v){
visitied[v] = true;
s.push(v);
while(!s.empty()){
v = s.top();
s.pop();
cout << v << ' ';
for(int i = n; i >= 1; i--){
if(adj_matrix[v][i] == 1 && visitied[i] == false){ //정점과 연결되어있고 방문X
visitied[i] = true;
s.push(i);
}
}
}
}
int main() {
adj_matrix[1][2] = 1;
adj_matrix[1][3] = 1;
adj_matrix[1][4] = 1;
adj_matrix[2][5] = 1;
adj_matrix[2][6] = 1;
adj_matrix[2][7] = 1;
adj_matrix[2][11] = 1;
adj_matrix[2][12] = 1;
adj_matrix[3][8] = 1;
adj_matrix[3][9] = 1;
adj_matrix[3][10] = 1;
DFS(1);
}다음과 같이 스택으로도 구현 가능하다.
노드 1에서 인접한 노드 2, 3, 4를 스택에 push한다. 이때 스택을 pop하면 4, 3, 2 내림차순으로 나오게 되므로 push할 때 4 → 3 → 2 순서대로 push할 수 있도록 for문을 조절한다. 스택 : 2, 3, 4 (앞으로 나옴)
스택에서 pop하여 나온 노드인 2에 대해 인접 노드를 찾는다. 12, 11, 7, 6, 5 노드이며, 이들을 스택에 push한다. 스택은 2를 pop하고 노드 2의 인접 노드를 push하였으므로 5, 6, 7, 11, 12, 3, 4 이다.
스택에서 pop하면 노드 5가 나온다. 이에 대해 인접 노드를 확인하고 스택에 push한다. 노드 5에 대한 인접노드는 없으므로 다음으로 넘어간다.
이를 스택이 빌 때까지 반복한다. 인접노드 순이 아니라 한 분기에 대해 끝까지 내려가고 더 이상 분기가 존재하지 않으면 옆 분기로 넘어가는 흐름을 확인할 수 있다.
1 2 5 6 7 11 12 3 8 9 10 4성질
최단경로를 찾는 알고리즘은 아니다.
목표 노드의 레벨이 높은 경우 효과적이다.
DFS는 백트래킹 알고리즘에서 사용된다. 재귀 시 파라미터나 스택에 담을 값들로 상태를 저장하기 쉽기 때문이다.
개인적으로 DFS를 재귀로 구현하였을 때가 간단했다. DFS 호출 전후로 상태를 변경하고 원상태로 되돌리는 코드로 쉽게 백트래킹을 구현할 수 있었다.
