1. 메모리
메모리는 데이터의 상태나 명령어 등을 기록하는 장치를 말한다.
주기억장치인 RAM을 보통 메모리라고 한다.앞서 컴퓨터 구조를 공부했듯이, CPU는 메모리에 올려져있는 명령어를 단지 실행할 뿐이다.
CPU와 가장 가까이 있는 레지스터부터 디스크까지 메모리 계층 구조에 관해 알아보자.
2. 메모리 계층
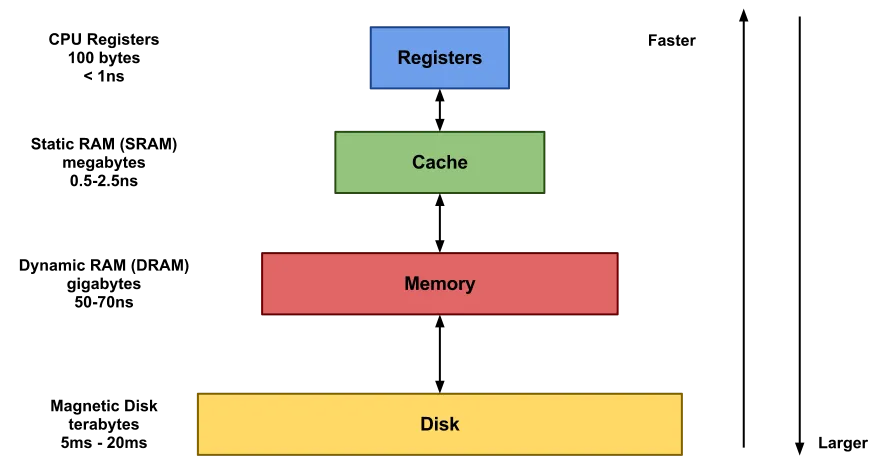
메모리 계층은 레지스터, 캐시(L1, L2, L3), RAM, 디스크(HDD/SSD)로 이루어져 있다.
경제성
레지스터로 갈 수록 속도는 매우 빠르지만 용량이 적고, 디스크로 갈 수록 속도는 느려지지만 용량은 커진다.
계층 위로 올라갈수록 가격은 비싸지기 때문에 이러한 경제성 때문에 메모리를 효율적으로 관리하는 것이 중요하다.
동작원리
CPU의 속도에 비해 하드디스크는 너무 느리기 때문에 CPU는 RAM을 통해 프로그램 데이터를 가져온다.
우리가 어떤 프로그램을 작동시키면 RAM은 하드디스크로부터 데이터를 복사해 임시 저장하고 필요 시마다 CPU에게 데이터를 넘긴다.
그러나 RAM도 CPU에 비하면 속도가 굉장히 느리기 때문에 CPU 내부나 근처에 캐시메모리를 두어 데이터를 저장한다.
캐시메모리는 다시 레지스터와 호흡하는데,
레지스터는 CPU 내부에서 데이터를 일시적으로 저장하는 장치로 속도가 가장 빠른 메모리다.
cf) 게임을 실행하다보면 '로딩중'이라는 메세지가 나오는데,
이는 하드디스크에서 RAM으로 데이터를 전송하는 과정이 진행 중임을 나타낸다.RAM(Random Access Memory)
그렇다면 RAM을 왜 주기억장치라고 부를까?에 대한 의문이 생겼다.
그리고 아래 블로그 글을 읽으니 바로 이해가 됐다.
https://blog-of-gon.tistory.com/46
블로그에서 가져온 그림이다.
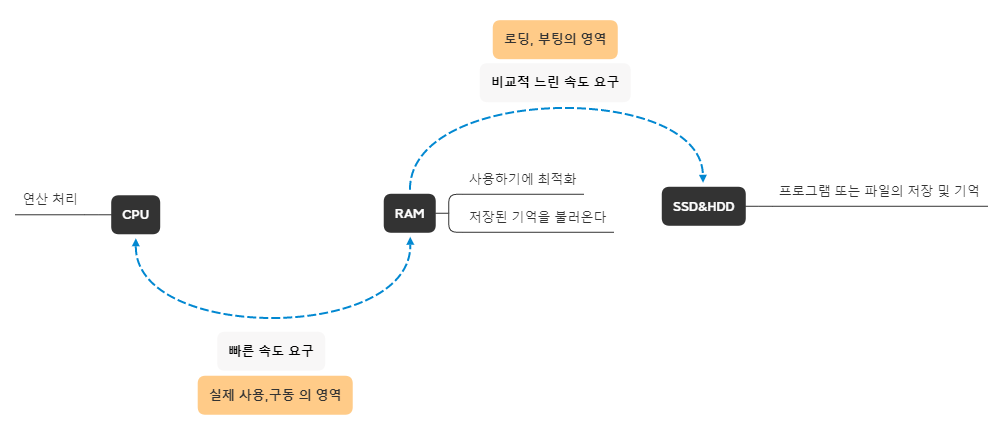
즉, 컴퓨터 입장에서 하드디스크는 필요한 것을 꺼내는 창고와 같고,
프로그램 실행에 필요한 데이터를 가져오는 RAM은 작업장이며,
그 명령어를 가져와 실행하는 CPU는 작업자이기 때문에 RAM을 주 기억장치라고 할 수 있다.
결국 RAM과 CPU의 소통이 빨라야 프로그램의 실행속도가 빠르다는 것을 알 수 있다.
3. 캐시메모리
시간적, 공간적 지역성을 기반으로 미래에 접근될 확률이 높은 데이터를 미리 보관해
전체적인 시스템의 성능을 높이는 메모리다.
빠른 장치와 느린 장치 속도 차이에 따른 병목 현상을 줄인다.속도 차이를 해결하기 위해 계층과 계층 사이에 존재하는 계층을 캐싱 계층이라고 한다.
캐시메모리와 디스크 사이에 존재하는 RAM을 디스크의 캐싱 계층이라고 할 수 있다.
비싸고 한정된 캐시메모리를 효율적으로 사용하기 위해서는 몇 가지 기준이 있다.
바로 시간지역성과 공간지역성이다.
시간지역성(temporal locality)
한 번 접근된 데이터는 가까운 미래에 다시 사용될 확률이 높음공간지역성(spatial locality)
한 번 접근된 데이터의 주변 데이터도 미래에 접근될 확률이 높음캐시라는 개념은 캐시메모리에 제한된 것이 아니라 컴퓨터의 부품이나 브라우저 등 다양한 곳에서 사용되고 있다.
캐시히트와 캐시미스
[캐시히트]
캐시에서 원하는 데이터를 찾는 것
[캐시미스]
찾는 데이터가 캐시에 없어 주메모리로 가서 데이터를 찾아오는 것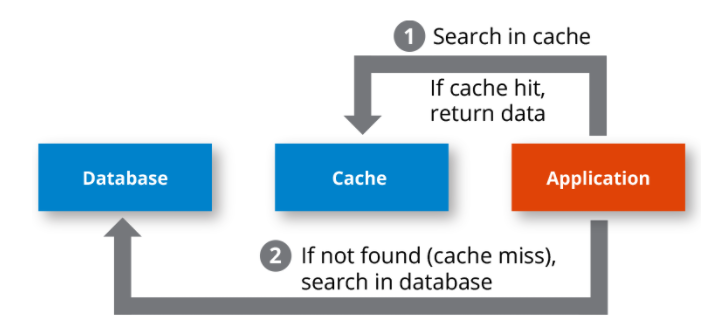
책에 나온 이미지 예시다.
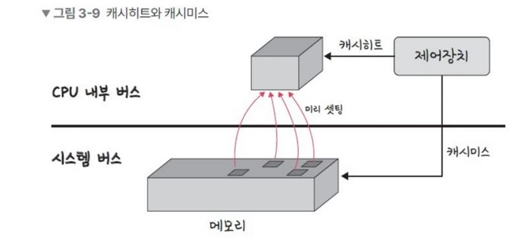
캐시히트를 하게되면 제어장치를 거쳐 데이터를 가져오게 된다.
캐시히트는 CPU와 위치가 가깝고 CPU 내부 버스를 기반으로 동작하기 때문에 속도가 매우 빠르다.
그러나 캐시미스가 발생하면 메모리에서 데이터를 가져오는데,
이는 시스템 버스를 기반으로 동작하고 있기 때문에 속도가 느리다.
웹브라우저의 캐시
웹브라우저의 캐시로는 쿠키, 로컬 스토리지, 세션 스토리지가 있다.
보통 사용자의 정보나 인증 관련 사항을 웹브라우저에 저장해 서버에 요청시 활용한다.
쿠키
키-값으로 이루어진 만료기한이 있는 저장소다.
보통 서버에서 만료기한을 정하며 모든 클라이언트 요청마다 자동으로 함께 보내진다.
저장용량이 작고, 보안에 취약하다.
다시보지 않기 창 등을 설정하는 데 이용할 수 있다.웹스토리지
키-값으로 이루어진 만료기한이 없는 저장소다.
HTML5부터 지원이 가능하며, 클라이언트에서만 수정이 가능하다.로컬스토리지
웹브라우저를 닫아도 데이터가 유지가 된다.
자동로그인 기능에 사용할 수 있다.세션스토리지
탭윈도우 단위로 스토리지가 생성되고, 탭을 닫으면 데이터가 휘발된다.
비로그인 장바구니, 입력폼데이터 유지 등에 사용할 수 있다.[ 참고영상 ]
https://www.youtube.com/watch?v=5s--sLWzuZc
데이터베이스의 캐싱 계층
데이터베이스를 구축할 때 메인 데이터베이스 위에 redis를 캐싱 계층으로 두어 성능을 향상시키기도 한다.
프로젝트를 할 때 refresh Token을 주로 redis에 담았는데,
이는 레디스에 키-값 형태로 데이터를 저장할 수 있고 조회가 빠르며, 데이터 만료일을 정할 수 있다는 특징 때문에 그렇다.
아래 링크는 JWT토큰과 Redis에 대해 설명해놓은 아주 흥미롭고 유익한 글이다.
https://junior-datalist.tistory.com/352
4. 메모리 관리
가상메모리(Virtual Memory)
메모리관리 기법 중 하나로, 실제 사용할 수 있는 메모리 자원을 추상화해
사용자에게 더 큰 메모리로 보이게 만드는 것을 말한다.어렵게 말해서 헷갈리는데 예시를 들어보겠다.
16GB 램을 샀다고 했을 때,
컴퓨터로 게임, 인터넷 등 몇 개의 프로그램만 실행해도 전체 필요한 메모리는 16GB를 훨씬 넘어갈 것이다.
RAM은 하드디스크에 저장된 파일에서 현재 필요한 데이터만 올리고 나머지는 그대로 하드디스크에 보관한다.
이게 바로 가상 메모리다.
즉, 필요한 부분만 메모리에 올려 실행시키기 때문에 실제 메모리의 크기를 훌쩍 넘는 여러 프로그램을 실행시킬 수 있다는 것이다.
CPU는 가상적으로 주어진 메모리 주소를 보고 실제 해당 데이터가 메모리의 어디에 존재하는 물리 주소를 알지 못한다.
이 때 메모리관리장치(MMU)가 가상주소를 물리주소로 변환한다.
가상주소와 실제주소는 페이지 테이블로 관리된다.
페이지 테이블 참조의 속도를 향상시키기 위해 TLB를 사용한다.
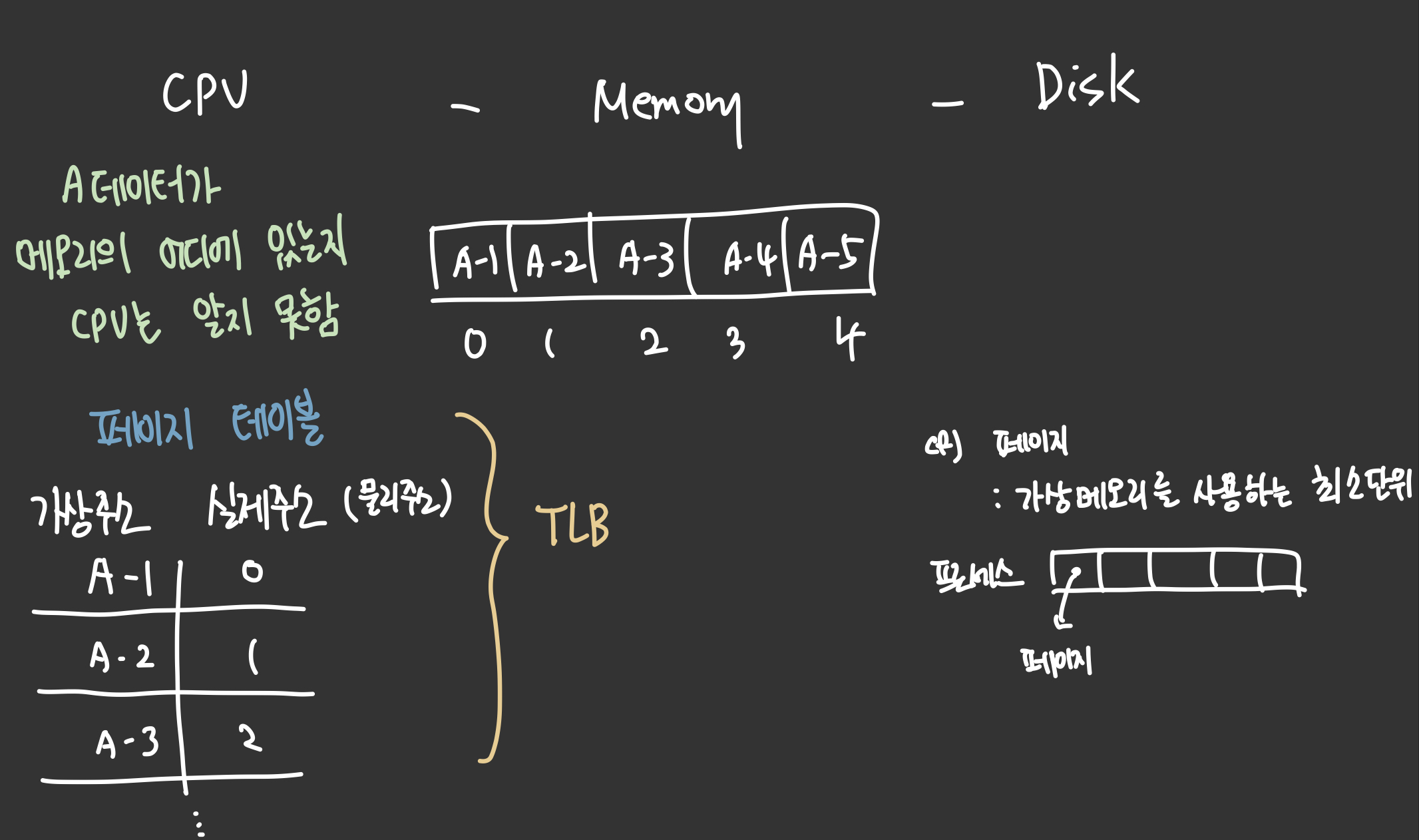
[TLB]
메모리와 CPU 사이에 존재하는 주소 변환을 위한 캐시.
페이지 테이블에 있는 리스트를 보관하며
CPU가 페이지 테이블로 가지 않도록 해 속도를 향상시키는 캐시 계층이다.5. 페이지 폴트(page fault)와 스와핑(Swapping)
가상 메모리에 존재하지만 실제 메모리인 RAM에 해당 데이터가 존재하지 않을 때 페이지 폴트가 발생한다.
이 때 운영체제는 당장 사용하지 않는 데이터는 다시 하드디스크로 옮기고,
필요할 때 다시 RAM으로 올리는 작업을 반복하면서 페이지 폴트를 해결한다.
우리는 이를 스와핑이라고 한다.
6. 스레싱(thrashing)
메모리의 페이지 폴트율이 높은 것을 의미한다.
컴퓨터의 심각한 성능 저하를 초래한다.CPU에서 찾는 데이터가 없을 때,
하드 디스크에서 필요한 데이터를 RAM으로 올리기까지 CPU는 동작을 멈춘다.
이 때 운영체제는 CPU가 한가하다고 생각해 더 많은 프로세스를 메모리에 올리게 되는데,
이와 같은 악순환이 반복되는 것을 바로 스레싱이라고 한다.
프로세스를 많이 실행할수록 한정된 메모리를 나눠가져야 하고,
각 프로세스의 페이지를 RAM에 많이 올려놓을 수 없기 때문에 페이지 폴트가 발생할 가능성이 더 커진다.
이를 해결하기 위한 방법으로는 메모리를 늘리거나, HDD를 사용한다면 SSD로 바꾸는 방법이 있다.
운영체제에서 할 수 있는 방법은 작업 세트와 PFF가 있다.
작업세트(working set)
지역성의 원리를 기반으로 최근에 사용된 근처 데이터를 포함해 페이지 집합을 만들어 미리 메모리에 로드한다.
탐색에 드는 비용과 스와핑을 줄일 수 있다.PFF(Page Fault Frequency)
페이지 폴트 빈도의 상한선과 하한선을 주는 것.
상한선에 도달하면 페이지를 늘리고 하한선에 도달하면 페이지를 줄인다.7. 메모리 할당
메모리에 프로세스를 할당할 때 시작 메모리 위치, 메모리 할당 크기 등을 기준으로 할당한다.
연속할당과 불연속 할당
연속할당
프로세스를 페이지 단위로 쪼개지 않고, 메모리에 연속적으로 공간을 할당하는 것연속할당은 다시 두 가지 방식으로 나뉜다.
고정 분할 방식(fixed partition allocation)
- 메모리를 미리 나누어 관리하기 때문에 융통성이 없다.
- 나누어 놓은 메모리의 크기보다 프로세스의 크기가 작아 메모리에 낭비되는 부분이 발생하는 내부 단편화가 발생한다.
가변 분할 방식(variable partition allocation)
- 매 시점 프로세스의 크기에 맞게 메모리를 나눠 사용한다.
- 메모리를 나눈 크기보다 프로세스의 크기가 커 들어가지 못하는 공간이 발생하는 외부 단편화가 발생한다.
불연속할당
현대 운영체제가 쓰는 방법으로,
프로세스를 동일한 크기의 페이지로 나누고 프로세스마다 페이지 테이블을 두어 이를 통해 프로세스를 할당한다.불연속 할당에는 페이징, 세그멘테이션, 페이지드 세그멘테이션 기법이 있다.
페이징
- 프로세스를 동일한 크기의 페이지로 나누어 메모리의 서로 다른 위치에 프로세스를 할당한다.
- 페이지와 프레임을 대응시키기 위해 paging table이 필요하다.
[홀]
비어 있는 메모리 공간세그멘테이션
- 페이지 단위가 아닌 의미 단위로 프로세스를 나눈다.
- 세그먼트들의 크기가 서로 다르기 때문에 빈 공간을 찾아 프로세스가 메모리에 할당한다.
- segmentation table이 필요하다.
페이지드 세그멘테이션
- 공유나 보안을 세그먼트로 나누고, 물리적 메모리는 페이지로 나누는 것을 말한다.
8. 페이지 교체 알고리즘
운영체제는 어떤 데이터를 RAM에 올리고 어떤 데이터를 하드디스크로 내려야할 지 결정해야 한다. 이 때 사용하는 것이 바로 페이지 교체 알고리즘이다 .
페이지 교체를 최소로 만드는 것이 목적이다.
오프라인 알고리즘
미래에 참조될 페이지와 현재 할당하는 페이지를 바꾸는 알고리즘이다.
그러나 미래에 어떤 프로세스가 실행될 지 알 수 없기 때문에
다른 알고리즘의 성능과 비교할 수 있는 기준을 제공하는 역할을 한다.FIFO(First In First Out)
가장 먼저 온 페이지를 가장 먼저 교체하는 알고리즘.LRU(Least Recently Used)
참조가 가장 오래된 페이지를 교체한다.
오래됐다는 것을 판단하기 위해 각 페이지마다 계수기, 스택을 두어야 하는 문제가 있다.
들어오는 순서를 저장하는 스택, 얼마나 참조되었는지 Clock 알고리즘
참조되지 않았던 페이지를 교체한다.
시계 방향으로 돌면서 0을 찾고 0을 찾은 순간 해당 프로세스를 교체하고 1로 바꾼다.LFU(Least Frequently Used)
가장 참조 횟수가 적은 페이지를 교체한다.
즉, 많이 사용되지 않은 데이터를 교체한다.