[모두를 위한 딥러닝2] Basic Machine Learning : Linear Regression and How to minimize cost
모두를 위한 딥러닝 2

본 게시물은 "모두를 위한 딥러닝 2" 강의 수강을 바탕으로 작성된 포스트이다.
복습
- Linear Regression
: Data의 분포를 반영하여 이에 가장 오차가 적도록 하는 "y=ax+b"의 직선을 만드는 것 - Hypothesis:Data의 분포를 가장 잘 대변하는 직선의 예측
==> H(x) = Wx + b ==> 요약해 H(x) = Wx 로 표현 - Cost: 실제 data와 가설의 차이
==> 참고로 1/2m에서 2m의 값은 뭐가 되든 상관 없다. 추후 미분에 용이하기 위해 m이 아닌 2m으로 설정한 것
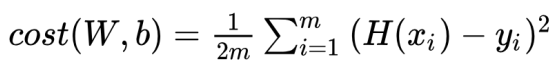
Gradient Descent Algorithm
W에 따른 cost(W) 변화
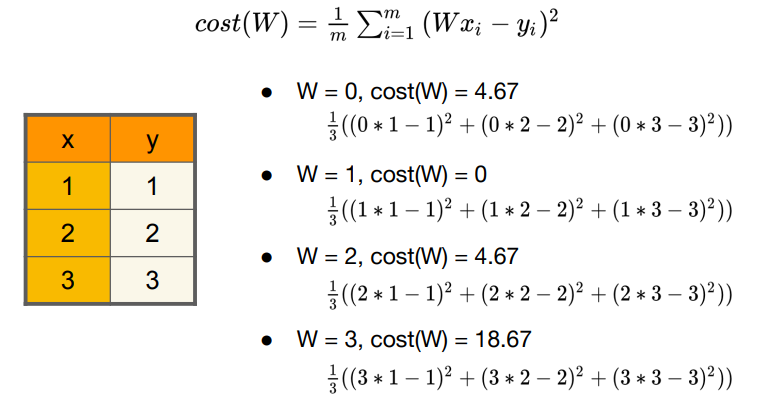
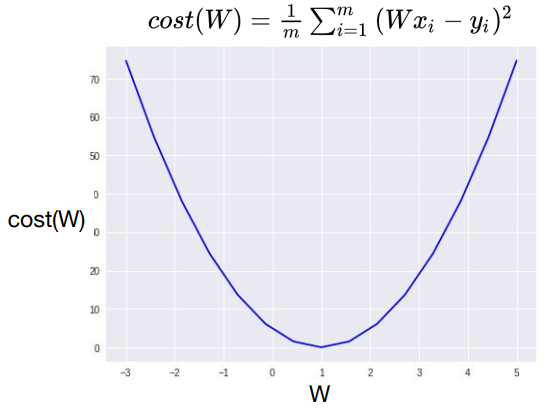
x, y의 값이 정해져 있으므로, cost(W)는 W에 따른 함수로 해석할 수 있다. 위 사진은 W의 값에 따른 cost의 변화이다. 그래프로 표현하면 최소의 cost를 갖는 W 값을 단번에 확인할 수 있다. 그렇다면 최소의 cost를 찾을 수 있는 방법은 없을까?
Gradient Descent Algorithm
Gradient descent algorithm이 대표적인 minimize cost function, 즉 최소의 cost를 찾아내는 기법이다.
Gradient는 경사, Descent는 하강을 의미하며, 경사를 따라 내려가면서 최저점을 찾도록 설계된 알고리즘이다.
참고로 변수가 하나가 아니라 두 개 이상일 때도 사용될 수 있다!
How it works?
- 최초의 initial point를 설정한다. 랜덤이어도 좋고, 원점이어도 좋다.
- Cost가 줄어들 수 있는 방향으로 W와 b값을 지속적으로 바꾸며,
바꿀 때마다 기울기 값을 구하고 cost가 최소가 되는 방향으로 업데이트를 한다. - 최소점에 도달했다고 생각이 들 때까지 2번 과정을 반복한다.
Formal Definition
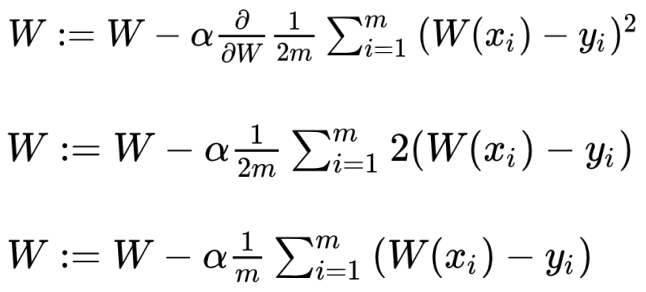
α: learning rate. 기울기 값을 얼마나 반영할지를 나타내는 상수다. 매우 작은 상수로 설정.
∂: 편미분 기호. 여기선 W에 대해서만 미분한다는 의미!
사진의 마지막 줄이 gradient descent algorithm이다.
정리하자면 cost function을 미분한 값, 즉 gradient에 α만큼 곱한 뒤 이 값을 W에서 빼서 업데이트한 것이다.
미분에 대한 공식은 derivative-calculator 또는 wolframalpha 같은 사이트에서 계산할 수 있기 때문에, 실제 계산은 우리의 목시 아니니 안심해도 된다.
Convex function
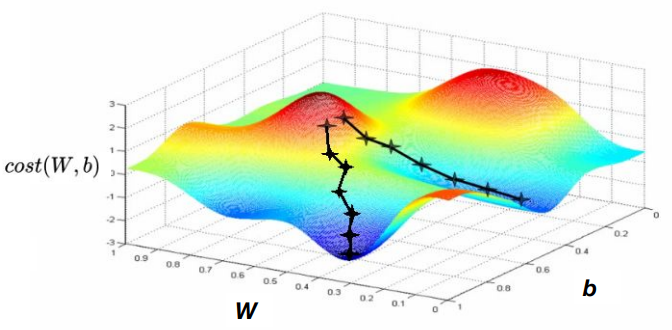
위 사진처럼 초기 시작 점이 어디냐에 따라서, local minimum일 수는 있어도 전체의 minimum이 아닐 가능성이 있다. 이런 상황에서는 Gradient descent algorithm을 적용하기 어렵다.
실습
이 링크는 cost function 실습을 진행해 본 결과이며,
https://colab.research.google.com/drive/1FrfdHRXiKJX3To5rKc4FOqwVLOO-jVXC?usp=sharing
이 링크는 gradient descending 실습을 진행한 결과이다!
https://colab.research.google.com/drive/1wgGGXlr58qL8Z-Dy4T9l5ikKYHL_jwQS?usp=sharing
