
본 게시물은 "모두를 위한 딥러닝 2" 강의 수강을 바탕으로 작성된 포스트이다.
Logistic Regression
What is logistic Regression?
Logistic Regression은 분류 기법 주의 하나로, 다른 특징을 가진 것을 서로 분류하는 데에 많이 사용되는 알고리즘이다.
Classification
Machine learning의 기초로 알아야 하는 분류 기법인 Binary Classification은, '그렇다'와 '그렇지 않다'로 구분되어 positive와 negative 또는 0과 1로 귀결될 수 있는 분류 기법을 말한다. 이 결과인 0과 1의 집합들을 바탕으로 logistic regression을 만들 수 있는 것이다.
Logistic vs Linear
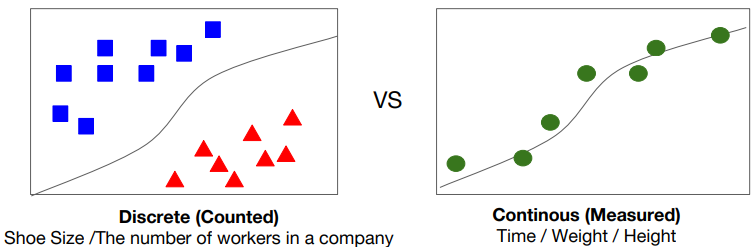
Linear은 전체 data의 '경향성'을 대표하는 것인 반면, Logistic이란 두 가지의 경우를 '구분'하는 것이다.
Linear는 연속적인 data로, 시간이나 무게 또는 높이처럼 실수단위이다.
Logistic은 각각의 data가 셀 수 있고, 흩어져 있기 때문에 신발 사이즈나 인원수처럼 뚝뚝 끊기는 정수단위로 생각하면 좋다.
Hypothesis Representation
: Logistic Regression의 가설 설정

Logistic에서는 Linear와 달리, 결과값을 0과 1로 구분해내는 가설을 세팅해야 한다. 어떻게 만들어야 하는 것일까?
먼저, Linear function을 통해 H(x)값을 도출해내야 한다. 그 이후에 Logistic function을 거쳐 값을 0과 1 사이로 만져주고, decision boundary (경계값)을 만들어 그 값보다 크거나 작으면 0 또는 1로 최종 Y값을 만들도록 하면 된다. 이 step이 Logistic 가설을 만드는 단계라 생각하면 되겠다.
Sigmoid/Logistic Function
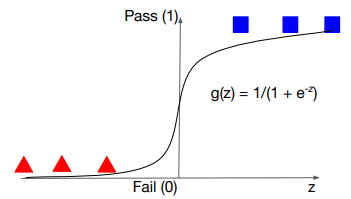

Logistic function 보다는 Sigmoid로 부르는 데에 익숙해지도록 하자. Sigmoid function은 위의 g(z)에 해당하는 함수이다. Linear를 통해 도출한 수치화 값을 특수한 모양새로 변경하는 것이다. 이 모양새로 만들려는 이유는 그 결과값이 0과 1사이로 수렴되기 때문이다.
Decision Boundary
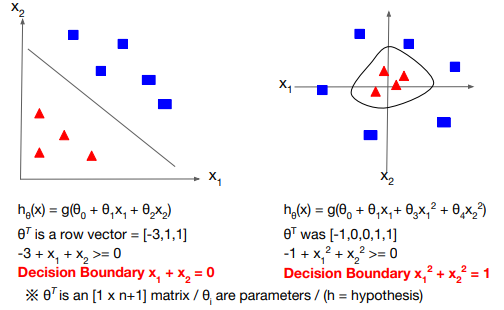
Sigmoid function을 통해 값을 0과 1 사이로 제한시켰으니 그 중 결과값을 0으로 도출하는 구간과 1로 도출하는 구간을 나눠야 한다. 그 구간의 경계를 기준으로 한 쪽을 0으로, 반대 쪽을 1로 변환하면 되는데 이것을 decision boundary라고 한다. 예를 들어, 일차함수보다 아래 또는 위에 위치하는 경우나 원의 안에 또는 밖에 위치하는 경우가 있다.
Cost Function
기본적인 개념과 원리는 비슷함. Cost는 비용. θ는 weight에 해당하기 때문에 초기값은 랜덤하게 설정되나 추후 조정. 이 때, 0과 1의 구분이 잘 되도록 하는 θ를 찾아가는 것이 cost function이라 할 수 있음.
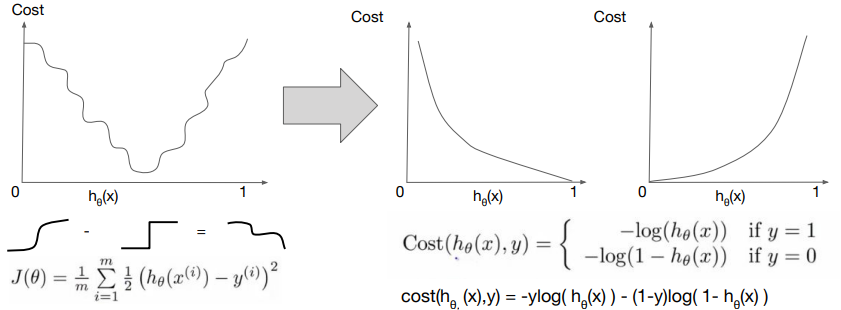
Linear cost function에 이 식을 대입해본다고 해보자. Cost값을 최소화하기 위한 과정은, 실제 가설을 통해 나온 sigmoid한 값에서 0과 1이 계단처럼 분류된 실제 라벨 값의 차이가 가장 적도록 만들어야 한다. 이 과정을 살펴보면, 0과 1 사이의 '실수값'을 갖는 sigmoid한 결과에서 계단형의 0 또는 1의 '정수값'을 빼면 꼬불꼬불한 값이 cost로 도출될 수밖에 없는 것이다.
따라서 우리는 logistic regression cost가 convex하게 볼록한 구조를 갖도록 만들어야 한다. 즉, 그 꼬불꼬불한 결과값을 convex하도록 바꿔주는 것이 Logistic cost function의 역할이다.
실제 라벨 값인 '실수값'이 0인지 1인지에 따라 볼록한 값을 갖게 하는 log의 형태가 달라지는 모양새이다.
Optimization (Gradient Descent)
Cost 함수를 최소화하는 과정이 optimization. Linear의 gradient descent와 흐름이 같다. Learning rate와 cost를 미분한 값을 곱한 것을 뺀 것을 새로운 경사값으로 update하며 최적의 모델을 찾아가는 것이다.
def grad(hypothesis, labels):
# hypothesis, label을 넣었을 때의 loss값의 차이인 loss_value와 [W,b]를 바탕으로 tape.gradient 실행.
with tf.GradientTape() as tape:
loss_value = loss_fn(hypothesis, labels)
return tape.gradient(loss_value, [W,b])
#GradientDescentOptimizer를 주어진 learning rate로 실행
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
#그 optimizer에 선언한 함수 grad 값과 [W,b]를 구하는 것...?
optimizer.apply_gradients(grads_and_vars=zip(grads,[W,b]))
실습
다음 링크는 logistic regression을 실습해 본 결과이다.
https://colab.research.google.com/drive/1Gmeb-jNAEPFwZtOkW-7M0g7i9G8iVeS5?usp=sharing
