
본 게시물은 "모두를 위한 딥러닝 2" 강의 수강을 바탕으로 작성된 포스트이다.
Linear Regression
Regression
"Regression toward the mean"에서의 Regression을 의미한다.
전체의 평균으로 되돌아간다ㅏ.
굉장히 크거나 작은 data들이 나오더라도 결과적으로 data들은 전체의 평균으로 되돌아가려는 특징이 있다는 통계적 원리를 설명하는 말이다.
Linear Regression
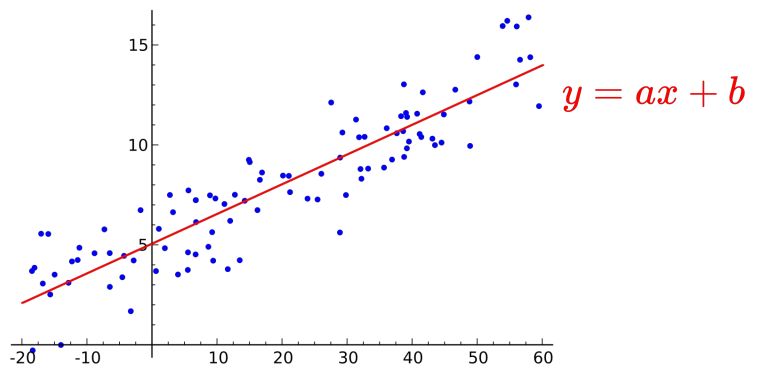
Linear Regression, 즉 선형 회귀는 data를 가장 잘 대변하는 직선의 방정식을 찾는 것이다. Data의 분포를 반영하여 이에 가장 오차가 적도록 하는 "y=ax+b"의 직선을 만드는 것이라 할 수 있다.
다시, Regression이란?
Linear Regression에서의 regression을 다시 해석해보자. 이 때의 Regression은 Data가 선형적으로 증/감하는 관계에 있을 때, 그 관계를 해석하는 것이라 볼 수 있다.
Hypothesis
말 그대로 '가설'이다. Linear Regression에서의 hypothesis란, 'data의 분포를 가장 잘 대변하는 직선은 이것이다' 하는 "H(x)=Wx+b"의 직선의 방정식이 된다. 가설은 꼭 정답이 아니어도 된다. 그러므로,
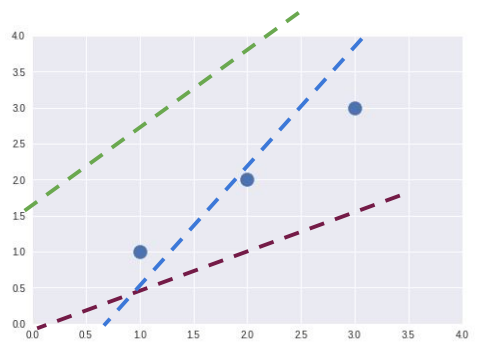
위 사진처럼 한 data set에 대해 3개 이상의 가설이 존재할 수 있는 것이다.
Cost
많은 가설 중 가장 오차가 적은 가설을 찾아내야 한다. 이 때의 오차가 'Cost'이다. Cost를 구하는 방법에 대해 알아보자.

사진에 빨간색으로 표시된 부분인 각 data마다의 y값의 차가 각각의 오차가 될 것이다. H(x) 자체의 오차는 이 것을 더하면 되므로, 다음과 같은 Cost function을 도출할 수 있다.
Cost Function
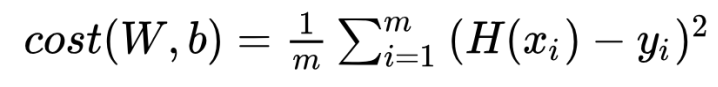
복잡해보이나? 별 거 없다. 오차의 제곱의 합을 구하고 data의 갯수대로 평균을 내면 된다. 오차의 '제곱'을 구하는 이유는 오차가 양수일 수도 음수일 수도 있기 때문이다.
Goal: Minimize cost
이 과정에서의 목표는, 가장 cost가 적게 만드는 함수를 찾는 것이다.
Training data에 가장 fit한 line을 찾는 것이 목적임을 잊어선 안된다!
아래 링크는 실습을 실행 결과이다.
https://colab.research.google.com/drive/1WfEtvKdGl-55KiM0Xf0hi0xST6P8dsmN?usp=sharing
