
본 게시물은 "모두를 위한 딥러닝 2" 강의 수강을 바탕으로 작성된 포스트이다.
복습

- Linear vs Logistic = 실수 vs 정수
- Logistic regression: 직관적으로, 두 가지로 구분하는 선을 찾아내는 것.
실제 차원에서는 'hyper plane'이라 부름.
Multinomial classification
multinomial classification 이란?
Multinomial classification이란 여러 개의 class가 있다는 의미다. 앞선 logistic regression에서는 두 가지를 구분하는 선을 찾아내는 것이 목표였다면 이제부터는 두 가지가 아닌 세 개 이상이 목표가 된다는 의미다.
간단한 예시로, Pass와 Fail로 grade가 매겨지는 것이 아닌 A, B, C의 등급제인 경우를 생각해보자. 최종 output이 0 또는 1로 나뉘는 것이 아니라 세 개 이상이 된다. 이 경우가 multinomial에 해당한다.
학습 과정
STEP 1. data의 output의 분포를 fix
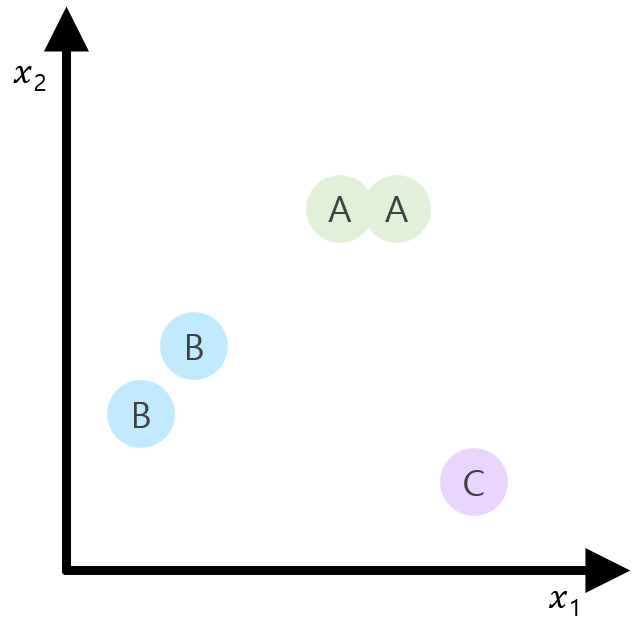
STEP 2. 각 output에 대해 각각의 binary classification을 생성
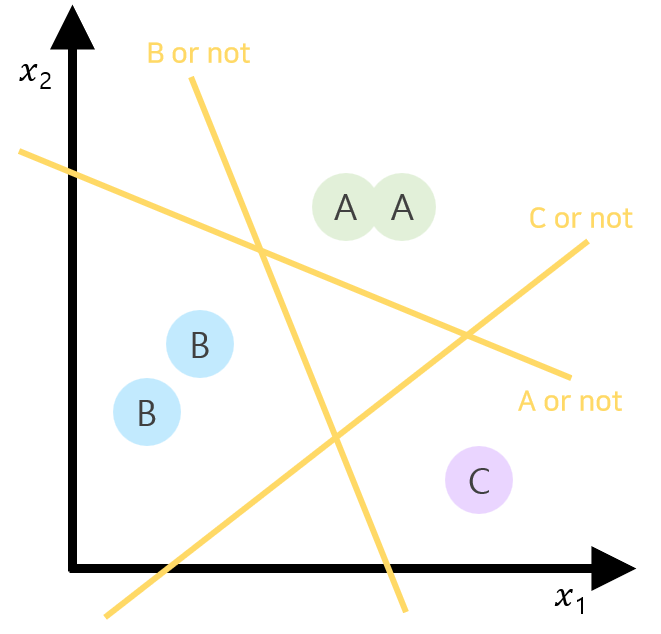
STEP3. 각 binary classification에 따라 독립된 H(x) 생성됨.


STEP4. 독립된 matrix를 하나로 묶어, 각각의 H(X)를 한 번에 추출
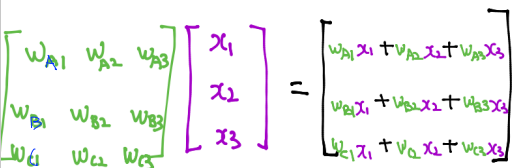
Softmax
A,B,C에 대해 각각 출력된 H(X) 결과는 현재 실수인 상태이며 0과 1사이도 아니다. 따라서 Sigmoid 과정을 거칠 필요가 있다. 하지만 두 개가 아닌 여러 개이기 때문에 단순 비율로 따지기도 힘든 상황. 이럴 땐 어떻게 해야 할까?
이럴 땐, 각 A B C에 대해 부여되는 값들의 합이 1이 되도록 숫자를 조정하면 된다. 그렇다면 저절로 0과 1 사이의 값으로 맞추어질 것이기 때문이며, 각각에 대한 '확률'로 표현되는 셈이기도 하기 때문이다.
이 과정이 "softmax"이다.
이후에는 "ONE-HOT encoding" 기법을 사용해 0 또는 1로 환산한다. 제일 큰 값만 1로 설정하고 나머지는 다 0으로 죽이는 것이다.
Cost function
예측한 값과 실제 값이 얼마나 차이나는지를 나타내는 cost function.
Cross-entropy
실제 Label(Y에 해당)과 예측값 사이의 차이를 Cross-entropy라는 함수를 통해 구한다. 우리의 목적은 예측이 맞는 경우 cost를 적게 출력하고 예측이 틀린 경우 cost를 많이 출력하는 것이다.
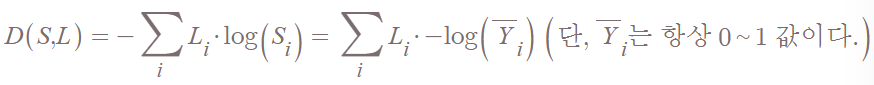
예측값은 softmax를 통과했기 때문에 0과 1 사이의 값을 가진다. 거기에 log를 씌우고 -를 붙이면, 오른쪽 아래로 내려가는 함수에 해당한다. 그 값에 실제 Y값을 곱하면 그게 cross-entry이다.
실제로 예측이 맞을 때와 틀릴 때 cost값이 어떻게 달라지는지를 확인해보자.
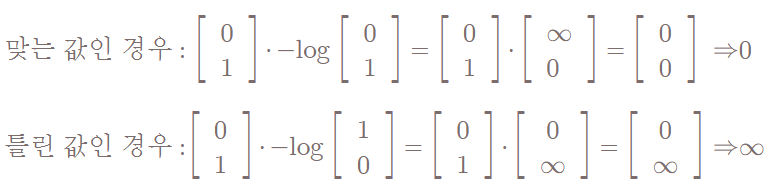
Logistic Cost vs Cross Entropy
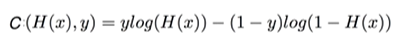
Logistic cost function에서는 길고 복잡했던 식으로 정리했었는데, 그걸 이렇게 단순한 cross entropy만으로 표현하자니 뭔가 불안하다. 과연 충분히 표현된 cost function일까?
정답은 '맞다'이다. 사실은 logistic cost가 사실상 cross entropy 였기 때문이다.
정리된 cost function
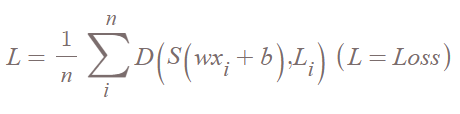
이제 cross entropy를 활용한 cost function의 형태를 보자. 단순하다. cross entropy를 한 뒤 그 평균을 내주면 된다.
Gradient descent
Cost를 구하는 방법을 찾았다면, 이제 그 cost를 최소화하는 방법을 강구해야 한다. 그건 당연하게도 gradient descent. 볼록한 cost function에서는 어느 점에서 시작하든 상관없이 최저점에 도달하게 되는데, 순서대로 함수를 미분하면 되는 수순이었다.
