강화학습이란?
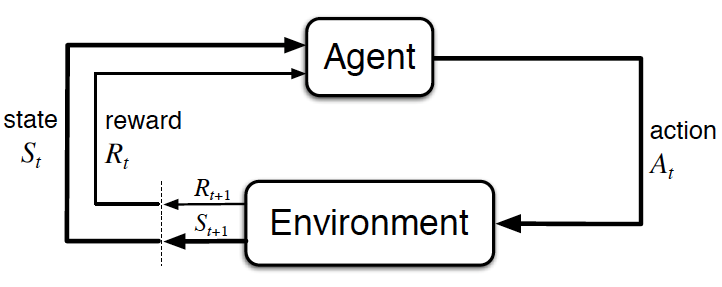
강화학습이란 action에 대한 reward를 받아가면서, reward를 최대화 하는 방향으로 방법(policy)를 학습하는 것을 강화학습이라고 한다.
- Observe : Agent가 Environment를 관측하여 State 를 얻는다.
- Action : Agent는 State 를 기반으로 Action 를 결정한다.
- Get Reward : Environment의 State가 로 바뀌고 Action 에 대한 reward 를 얻는다.
강화학습 문제를 풀기 위해서는 어떻게 해야 하는가?
강화학습 문제 뿐만이 아니라, 이 세상의 모든 문제를 풀기 위해 공통적으로 사용할 수 있는 방법이 있다. 바로 파인만 알고리즘(Feynman Algorithm)이다.
파인만 알고리즘
- 문제를 쓴다.
- 문제를 열심히 생각한다.
- 답을 쓴다.
파인만 알고리즘의 1번 문제를 쓴다를 사용하기 위해서 문제를 수학적으로 정의하는 작업을 해 보자. 즉 우리는 강화학습 문제를 풀기 위해서 다음 과정을 거칠 것이다.
- 강화학습 문제를 수학적으로 정의한다.
- 문제를 열심히 생각한다.
- 답을 쓴다.
자 이제 강화학습 문제를 수학적으로 정의하기 위해 수학자 Markov의 발자취를 따라가보자.
강화학습 문제 정의하기
- 거의 대부분의 RL 문제들은 MDP 문제로 표현할 수 있다.
MP (markov property)
미래가 오직 현재 상태와 관련이 있고 과거와는 관련이 없을 때 현재 상태는 Markov property를 가진다. 수식으로 표현하면 다음과 같다
- 는 probability를 의미한다.
- 현재 상태 는 과거의 정보를 함축하고 있다.
- 따라서 현재 상태 를 알고있다면 과거 정보는 필요하지 않다.
MP (markov process)
Markov process는 모든 상태가 markov property를 가지는 확률 과정이다.
markov process는 유한 상태집합 의 모든 state가
Defs
Markov Process(또는 markov chain)은 튜플 로 표현된다.
- 는 유한 상태 집합이다.
- 는 state transition probability matrix이다.
MRP (markov reward process)
markov process는 state transition에 대한 reward가 있는 markov process이다.
Defs
Markov Reward Process는 튜플 로 표현된다.
- 은 reward function이다, , 는 Expectation value를 의미한다.
- 는 discount factor이다,
Return & Discount Factor & State Value Function
- Return은 현재 상태 부터 Environment와의 상호작용이 끝날 때 까지의 모든 discounted reward의 합이다.
- Discount Factor는 의 값을 가지며 미래의 reward를 discount 하는 기능을 한다. reward를 discount 하는 이유는 다음과 같다.
- cyclic Markov processes에서 infinite return을 피하기 위해
- 미래에 대한 불확실성이 표현되지 않을 수 있어서
- reward가 돈이라면, 즉각적인 보상이 나중의 보상보다 더 가치가 있기 때문에
- 사람, 동물은 원래 바로 보상이 주어지는 것을 좋아함
- 정리하자면 1에 가까울 수록 거시적으로 미래의 reward의 가치도 인정하겠다는 것이고, 0에 가까울 수록 근시적으로 미래의 reward의 가치를 낮게 평가하겠다는 의미이다.
- Value Function : MRP에서의 state value function v(s)는 상태 s부터 시작하는 expected return 값이다.
MDP (markov decision process)
Markov Decision Process는 MRP에 desicion이 더해진 process이다.
Defs
Markov Decision Process는 튜플 로 표현된다.
- 는 유한한 크기의 state 집합이다.
- 는 유한한 크기의 선택할 수 있는 action의 집합이다.
- 는 state transition probability matrix이다.
- 현재 state 에서 action 를 선택했을 때, next state가 이 될 확률을 의미한다.
- 은 reward function이다,
- 현태 state 에서 action 를 선택했을 때, reward가 이 될 확률을 의미한다.
- 는 discount factor이다.
Policies & Value Function
- Policy 는 state 에서 선택할 수 있는 action에 대한 확률 분포이다.
- policy는 agent의 행동을 모두 정의한다. (policy를 따르지 않는 action은 취하지 않는다)
- MDP에서의 policy는 current state에 의해서만 action을 결정한다. (과거의 state는 영향을 주지 않는다.)
- MDP에서는 State-Value Function과 Action-Value Function을 정의한다.
- State-Value Function은 policy 를 따를 때, state 에서 부터의 expected return 값을 가진다.
- Action-Value Function은 policy 를 따를 때, state 에서 action 를 선택했을 때의 expected return의 값을 가진다.
Remind
- RL이란 무엇인가? 어떤 것을 강화학습이라 부르는가?
- RL의 5가지 elements를 설명하시오.
- MP란?
- MDP란? MDP를 수식으로 표현하시오.
- value function을 return 값을 기반으로 설명하고 수식을 쓰시오
Next
와 의 관계를 Bellman equation으로 풀어보자.
Refs
MP : david silver lecture
