아파치 하둡(Apache Hadoop, High-Availability Distributed Object-Oriented Platform)은 대량의 자료를 처리할 수 있는 큰 컴퓨터 클러스터에서 동작하는 분산 응용 프로그램을 지원하는 프리웨어 자바 소프트웨어 프레임워크이다.
Hadoop의 모듈
베이스 아파치 하둡 프레임워크는 다음의 모듈을 포함하고 있다
- 하둡 커먼(Hadoop Common)
- 하둡 분산 파일 시스템(HDFS)
- 하둡 YARN
- 하둡 맵리듀스
각각의 모듈이 어떤 역할을 하는지 확인해보자.
Hadoop Common
Hadoop Core라고도 하는 Hadoop Common은 다른 Hadoop 모듈을 지원하는 공통 유틸리티 및 라이브러리의 모음입니다. 그리고, Hadoop을 시작하는 데 필요한 JAR(Java Archive) 파일과 스크립트도 포함되어 있습니다.
몇 가지 기능을 살펴 보겠습니다.
Distribute Copy(DistCp)
Hadoop 시스템은 큰 데이터를 처리하기 때문에 대규모 데이터 이동을 위해 DistCp를 제공합니다. 맵리듀스를 이용하여 대규모의 파일을 병렬로 복사하는 명령입니다.
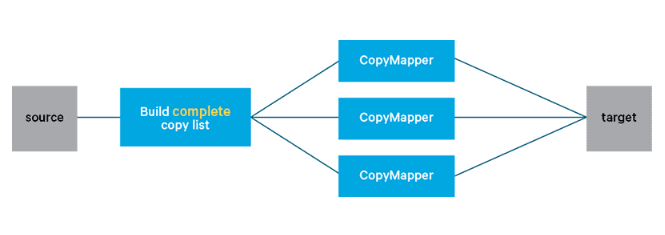
하지만, 대규모 병렬 처리 작업이기 때문에 네트워크 사용량을 잘 확인해야 합니다. 너무 많은 매퍼를 할당 하면 네트워크 자원을 많이 사용하여 운영에 문제가 생길 수 있습니다.
Hadoop Archive
하둡 HDFS는 작은 사이즈의 파일이 많아지면 네임노드에서 이를 관리하는데 많은 어려움을 겪게 되는 문제가 발생합니다. (약 3억 5천만개 제한) 따라서 블록사이즈 정도로 파일을 유지해주는 것이 좋습니다. 이를 위해서 하둡은 파일을 묶어서 관리하고, 사용할 수 있는 하둡 아카이브(Hadoop Archive) 기능을 제공합니다.
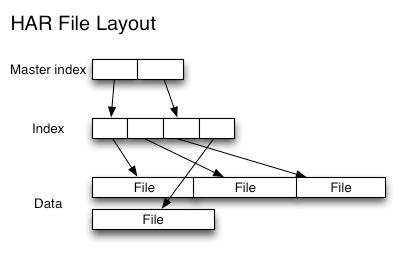
그림과 같이 여러 파일을 인덱스를 이용하여 묶어 관리하기 때문에 다수의 파일을 관리할 수 있습니다
HDFS (Hadoop Distributed File System)
수십 테라바이트 또는 페타바이트 이상의 대용량 파일을 분산된 서버에 저장하고, 그 저장된 데이터를 빠르게 처리할 수 있게 하는 파일시스템이다. 또한 저사양의 서버를 이용해서 스토리지를 구성할 수 있어 기존의 대용량파일스시스템(NAS, DAS, SAN등)에 비해 장점을 가진다. HDFS는 블록 구조의 파일 시스템이다. 파일을 특정크기의 블록으로 나누어 분산된 서버에 저장된다. 블록크기는 64MB에서 하둡2.0부터는 128M로 증가되었다.
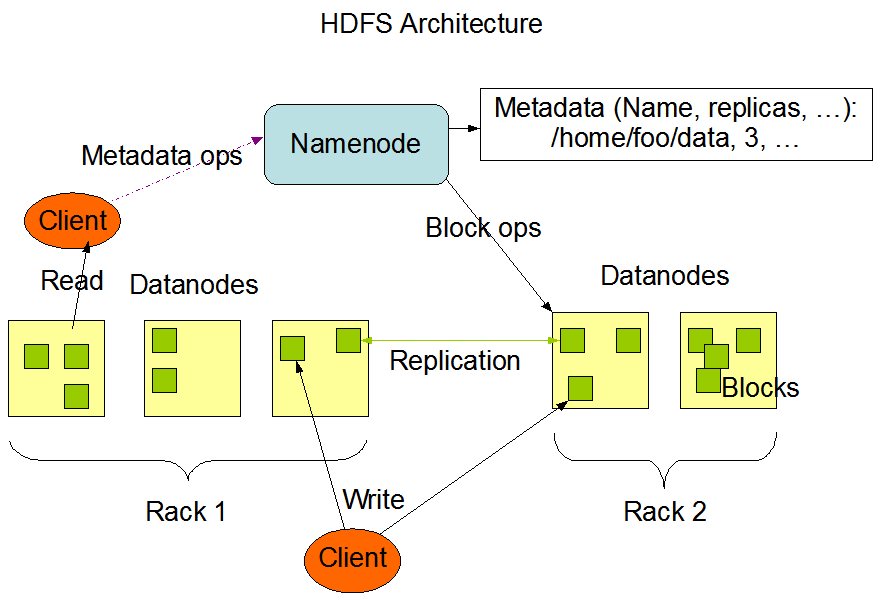
네임노드와 데이터노드
HDFS는 네임노드(마스터)와 데이터노드(슬레이브)로 구현되어 있다.
네임노드(NameNode)는 다음과 같은 핵심기능을 수행한다.
- 메타데이터 관리
- 데이터노드 모니터링
- 블록 관리
- 클라이언트 요청접수
데이터노드(DataNode)는 클라이언트가 HDFS에 저장하는 파일이다. RAW 데이터와 체크섬으로 구성되어 있다.
YARN(Yet Another Resource Negotiator)
Hadoop v1.0에서는 하나의 마스터 노드에서 job을 할당하고 관리를 하였는데 처리할 데이터 용량이 커짐에 따라 병목이 발생하였고, v2.0부터는 YARN을 인수하여 자원관리와 작업 스케쥴링을 맡기게 되었다.
YARN의 구성
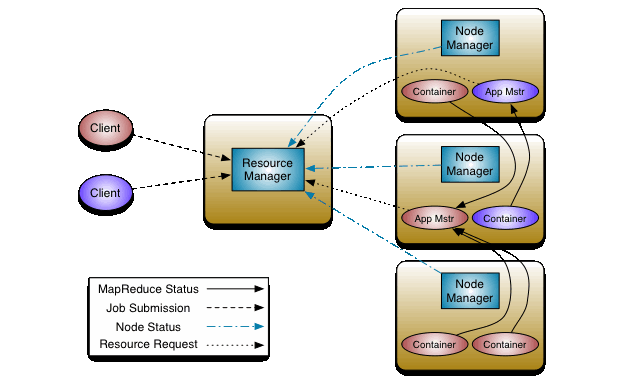
-
Resource Manager
: Master Daemon에서 구동되며, 클러스터들로의 자원 할당을 관리한다. -
Node Manager
: Slave Daemon에서 구동되며, 각 단일 노드의 Task 실행을 담당한다. -
Application Master
: 개별적인 응용에서 필요로 하는 자원과 Job에 대한 lifecycle을 관리한다. 이것은 Node Manager와 함께 작동하며, 작업의 실행을 모니터링한다. -
Container
: 한 노드의 자원을 모아둔 패키지 (RAM, CPU, Network, HDD 등)
YARN의 동작방식
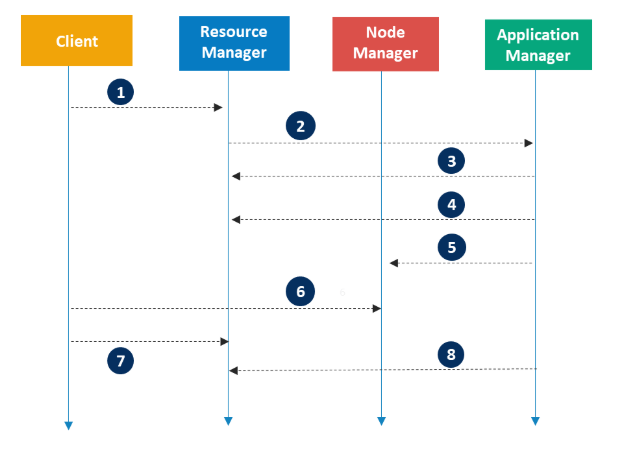
1. Client가 Resource Manager에게 Application에 대한 요청을 전송한다.
2. Resource Manager는 Application Master와 함께 Application을 등록한다. (이때 Application ID가 생성되며, 후에 Client에게 반환된다.)
3. Resource Manager는 각각의 분리된 Container에서 Application Master를 구동한다. 만약 Container가 구동 불가능하다면, 적합한 Container를 찾을 때까지 기다린다.
4. Application Master는 Node Manager에게 Container의 실행 명령을 전달한다.
5. Application 코드가 Container에서 실행된다.
6. Client는 Application의 상태를 모니터링하기 위해 Resource Manager/Application Manager와 주고 받는다.
7. Application Master가 Resource Manager에서 등록 해지된다.
MapReduce
맵리듀스의 기원은 구글에서 만든 Map Reduce라는 알고리즘에서 탄생됐다. 즉, Goggle MapReduce를 참고해서 Hadoop MapReduce 프레임워크를 만든것이다.
맵리듀스는 대용량 데이터 처리를 위한 분산 프로그래밍 모델이다. 분산되어 있는 데이터를 분석하려고 한다. 이때 분산된 데이터를 굳이 한 곳으로 모아서 분석을 한다면, 굉장히 오래걸리고 비효율적일 것이다. 따라서 특정 데이터를 가지고 있는 데이터 노드만 분석을 하고 결과만 받는 것이 맵리듀스이다. 통합분석이 아닌, 개별분석 후 결과를 취합한다고 생각하자.
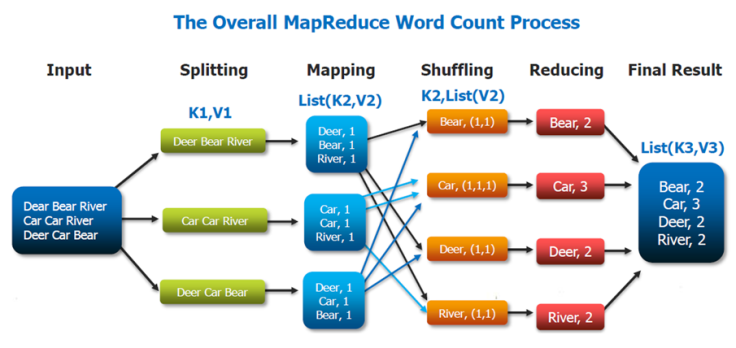
MapReduce의 작동원리
- Map: 입력 데이터를 우선 여러 개의 작은 블록으로 분할합니다. 다음으로 각각의 블록을 매퍼에 할당하여 처리하도록 합니다.
- Reduce: 작업자 노드가 Key-Value 데이터 그룹을 각각, 병렬로 처리하여 출력값을 도출합니다.키(Key)가 같은 맵 출력값은 모두 한 개의 Reducer에 할당되고, 이것이 그 Key의 값(Value)을 집계합니다.
레퍼런스
- 위키백과 - 아파치하둡
- 위키백과 - 맵리듀스
- WikiDocs - 빅데이터 - 하둡, 하이브로 시작하기
- databricks - MapReduce
- HAN_PY - 하둡(Hadoop) 기초 정리
- 와이케이의 마구잡이 - 하둡(Hadoop)의 HDFS에 대한 기본설명
- 길은 가면, 뒤에 있다. - [하둡] 맵리듀스(MapReduce) 이해하기
- IT딴따라 - DISPCP
- 망나니개발자 - [Hadoop] YARN의 구조와 동작 방식
- edureka - Hadoop YARN Tutorial – Learn the Fundamentals of YARN Architecture
- 아는 만큼 - 맵/리듀스 (Map/Reduce) 이해하기
